 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Foundation Models for Annotation-Efficient Adnexal Mass Segmentation in Cine Images
Apr 09, 2026Adnexal mass evaluation via ultrasound is a challenging clinical task, often hindered by subjective interpretation and significant inter-observer variability. While automated segmentation is a foundational step for quantitative risk assessment, traditional fully supervised convolutional architectures frequently require large amounts of pixel-level annotations and struggle with domain shifts common in medical imaging. In this work, we propose a label-efficient segmentation framework that leverages the robust semantic priors of a pretrained DINOv3 foundational vision transformer backbone. By integrating this backbone with a Dense Prediction Transformer (DPT)-style decoder, our model hierarchically reassembles multi-scale features to combine global semantic representations with fine-grained spatial details. Evaluated on a clinical dataset of 7,777 annotated frames from 112 patients, our method achieves state-of-the-art performance compared to established fully supervised baselines, including U-Net, U-Net++, DeepLabV3, and MAnet. Specifically, we obtain a Dice score of 0.945 and improved boundary adherence, reducing the 95th-percentile Hausdorff Distance by 11.4% relative to the strongest convolutional baseline. Furthermore, we conduct an extensive efficiency analysis demonstrating that our DINOv3-based approach retains significantly higher performance under data starvation regimes, maintaining strong results even when trained on only 25% of the data. These results suggest that leveraging large-scale self-supervised foundations provides a promising and data-efficient solution for medical image segmentation in data-constrained clinical environments. Project Repository: https://github.com/FrancescaFati/MESA
SWDE : A Sub-Word And Document Embedding Based Engine for Clickbait Detection
Aug 02, 2018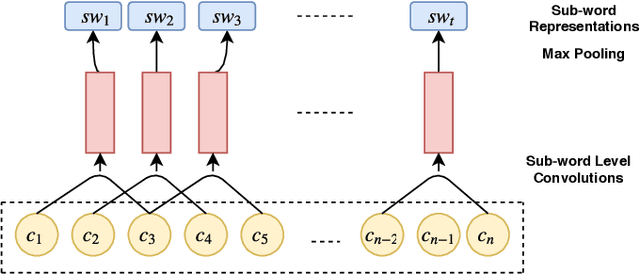
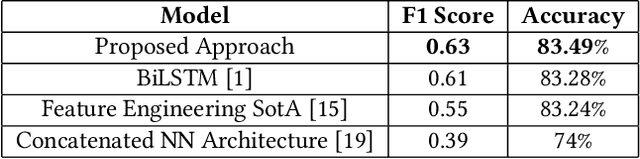
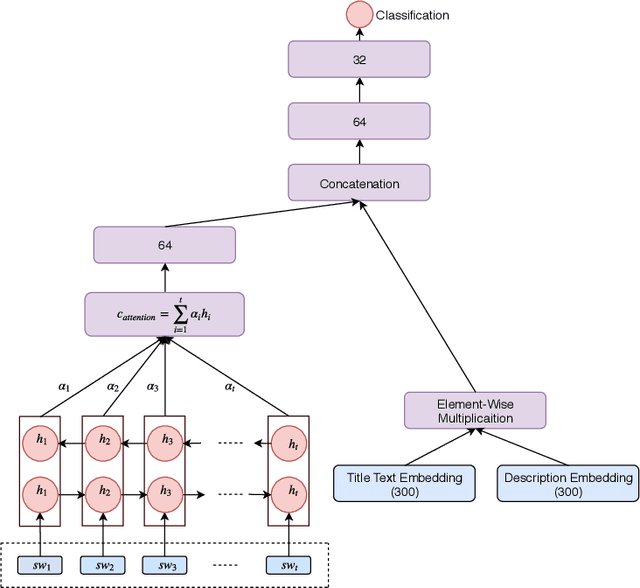
In order to expand their reach and increase website ad revenue, media outlets have started using clickbait techniques to lure readers to click on articles on their digital platform. Having successfully enticed the user to open the article, the article fails to satiate his curiosity serving only to boost click-through rates. Initial methods for this task were dependent on feature engineering, which varies with each dataset. Industry systems have relied on an exhaustive set of rules to get the job done. Neural networks have barely been explored to perform this task. We propose a novel approach considering different textual embeddings of a news headline and the related article. We generate sub-word level embeddings of the title using Convolutional Neural Networks and use them to train a bidirectional LSTM architecture. An attention layer allows for calculation of significance of each term towards the nature of the post. We also generate Doc2Vec embeddings of the title and article text and model how they interact, following which it is concatenated with the output of the previous component. Finally, this representation is passed through a neural network to obtain a score for the headline. We test our model over 2538 posts (having trained it on 17000 records) and achieve an accuracy of 83.49% outscoring previous state-of-the-art approaches.
* Accepted at SIGIR 2018 as Computational Surprise in Information Retrieval (CompS) Workshop Paper. arXiv admin note: substantial text overlap with arXiv:1710.01507