 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable and Efficient Large-Scale Generative Recommenders
May 22, 2026Generative recommendation models can model user behavior as sequences of events and provide a shared backbone for multiple recommendation tasks. In production, however, pre-training gains do not automatically translate into downstream application improvements: task headroom, repeated-training cost, serving latency, and item freshness all affect transfer. We describe our experience scaling a generative recommender from 2M to 1B backbone parameters, excluding embedding and decoding layers, in a production-scale title recommendation setting. Across multiple downstream tasks, we observe task-dependent scaling behavior: some tasks approach an empirical ceiling within the observed scale range, while others continue to benefit from additional capacity. This motivates using offset scaling-law fits as a diagnostic for where additional model scale may be more or less useful. We then study production constraints that arise when applying the model in practice. Frequent retraining over trillions of behavior tokens makes training and decoding efficiency important; cached serving can make the immediate next-token target stale; and newly launched titles may need to be scored from semantic metadata before collaborative ID embeddings are reliable. We address these issues with multi-token prediction for serving-latency alignment, sampled softmax and a projected decoding head for efficient repeated training, and semantic item towers with collaborative-embedding masking for cold-start adaptation. In a one-week production-shadow evaluation over 1M users, the 1B-backbone model achieves higher MRR than the 2M-backbone baseline across all reported tasks. Overall, the results support treating model scale as one component of a production transfer problem, alongside task headroom, decoding cost, serving-latency alignment, and item generalization.
Robust Post-Training for Generative Recommenders: Why Exponential Reward-Weighted SFT Outperforms RLHF
Mar 10, 2026Aligning generative recommender systems to user preferences via post-training is critical for closing the gap between next-item prediction and actual recommendation quality. Existing post-training methods are ill-suited for production-scale systems: RLHF methods reward hack due to noisy user feedback and unreliable reward models, offline RL alternatives require propensity scores that are unavailable, and online interaction is infeasible. We identify exponential reward-weighted SFT with weights $w = \exp(r/λ)$ as uniquely suited to this setting, and provide the theoretical and empirical foundations that explain why. By optimizing directly on observed rewards without querying a learned reward model, the method is immune to reward hacking, requires no propensity scores, and is fully offline. We prove the first policy improvement guarantees for this setting under noisy rewards, showing that the gap scales only logarithmically with catalog size and remains informative even for large item catalogs. Crucially, we show that temperature $λ$ explicitly and quantifiably controls the robustness-improvement tradeoff, providing practitioners with a single interpretable regularization hyperparameter with theoretical grounding. Experiments on three open-source and one proprietary dataset against four baselines confirm that exponential reward weighting is simple, scalable, and consistently outperforms RLHF-based alternatives.
Netflix Artwork Personalization via LLM Post-training
Jan 06, 2026Large language models (LLMs) have demonstrated success in various applications of user recommendation and personalization across e-commerce and entertainment. On many entertainment platforms such as Netflix, users typically interact with a wide range of titles, each represented by an artwork. Since users have diverse preferences, an artwork that appeals to one type of user may not resonate with another with different preferences. Given this user heterogeneity, our work explores the novel problem of personalized artwork recommendations according to diverse user preferences. Similar to the multi-dimensional nature of users' tastes, titles contain different themes and tones that may appeal to different viewers. For example, the same title might feature both heartfelt family drama and intense action scenes. Users who prefer romantic content may like the artwork emphasizing emotional warmth between the characters, while those who prefer action thrillers may find high-intensity action scenes more intriguing. Rather than a one-size-fits-all approach, we conduct post-training of pre-trained LLMs to make personalized artwork recommendations, selecting the most preferred visual representation of a title for each user and thereby improving user satisfaction and engagement. Our experimental results with Llama 3.1 8B models (trained on a dataset of 110K data points and evaluated on 5K held-out user-title pairs) show that the post-trained LLMs achieve 3-5\% improvements over the Netflix production model, suggesting a promising direction for granular personalized recommendations using LLMs.
Joint Modeling of Search and Recommendations Via an Unified Contextual Recommender (UniCoRn)
Aug 19, 2024
Search and recommendation systems are essential in many services, and they are often developed separately, leading to complex maintenance and technical debt. In this paper, we present a unified deep learning model that efficiently handles key aspects of both tasks.
Augmenting Netflix Search with In-Session Adapted Recommendations
Jun 05, 2022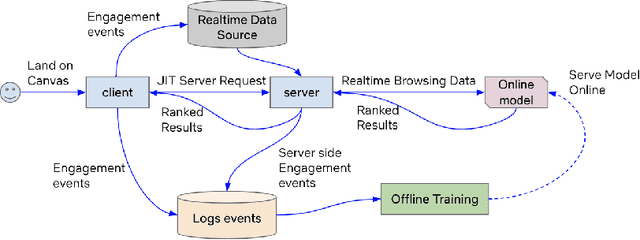
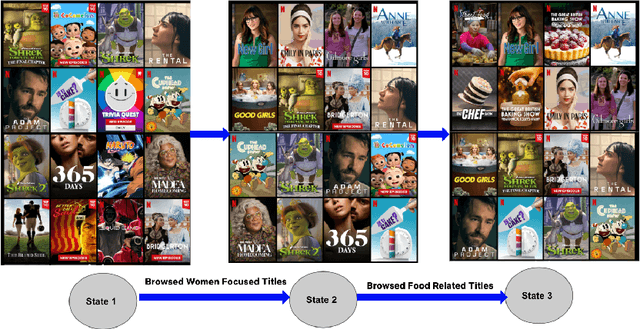
We motivate the need for recommendation systems that can cater to the members in-the-moment intent by leveraging their interactions from the current session. We provide an overview of an end-to-end in-session adaptive recommendations system in the context of Netflix Search. We discuss the challenges and potential solutions when developing such a system at production scale.
Identifying Ventricular Arrhythmias and Their Predictors by Applying Machine Learning Methods to Electronic Health Records in Patients With Hypertrophic Cardiomyopathy(HCM-VAr-Risk Model)
Sep 19, 2021
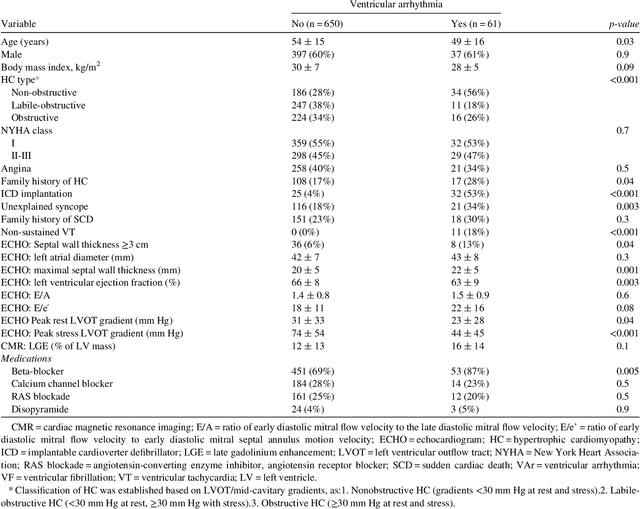
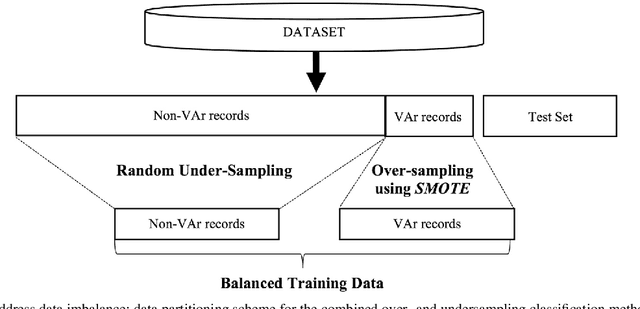
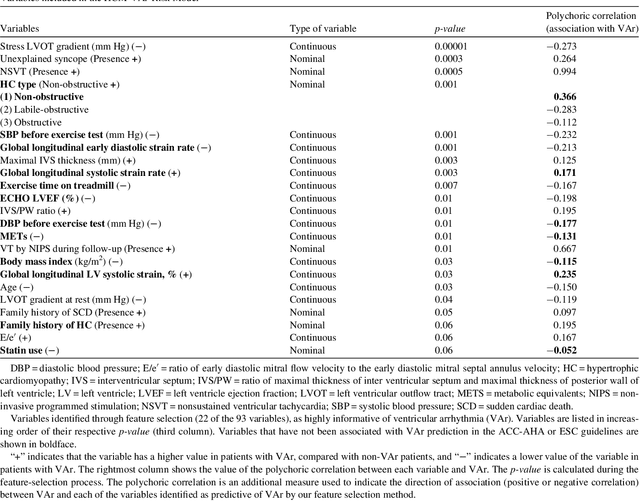
Clinical risk stratification for sudden cardiac death (SCD) in hypertrophic cardiomyopathy (HC) employs rules derived from American College of Cardiology Foundation/American Heart Association (ACCF/AHA) guidelines or the HCM Risk-SCD model (C-index of 0.69), which utilize a few clinical variables. We assessed whether data-driven machine learning methods that consider a wider range of variables can effectively identify HC patients with ventricular arrhythmias (VAr) that lead to SCD. We scanned the electronic health records of 711 HC patients for sustained ventricular tachycardia or ventricular fibrillation. Patients with ventricular tachycardia or ventricular fibrillation (n = 61) were tagged as VAr cases and the remaining (n = 650) as non-VAr. The 2-sample t test and information gain criterion were used to identify the most informative clinical variables that distinguish VAr from non-VAr; patient records were reduced to include only these variables. Data imbalance stemming from low number of VAr cases was addressed by applying a combination of over- and under-sampling strategies.We trained and tested multiple classifiers under this sampling approach, showing effective classification. We evaluated 93 clinical variables, of which 22 proved predictive of VAr. The ensemble of logistic regression and naive Bayes classifiers, trained based on these 22 variables and corrected for data imbalance, was most effective in separating VAr from non-VAr cases (sensitivity = 0.73, specificity = 0.76, C-index = 0.83). Our method (HCM-VAr-Risk Model) identified 12 new predictors of VAr, in addition to 10 established SCD predictors. In conclusion, this is the first application of machine learning for identifying HC patients with VAr, using clinical attributes.
Machine Learning Methods for Identifying Atrial Fibrillation Cases and Their Predictors in Patients With Hypertrophic Cardiomyopathy: The HCM-AF-Risk Model
Sep 19, 2021
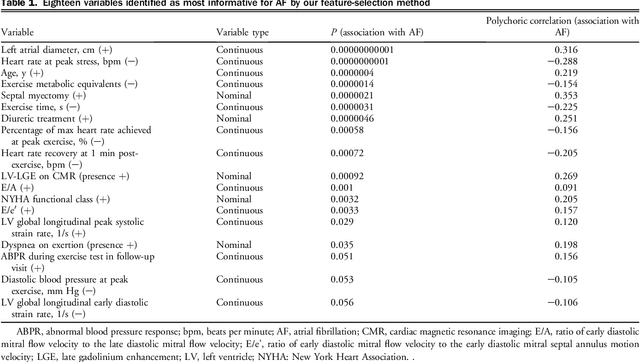
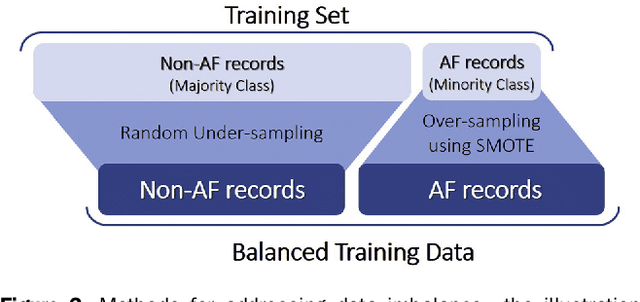
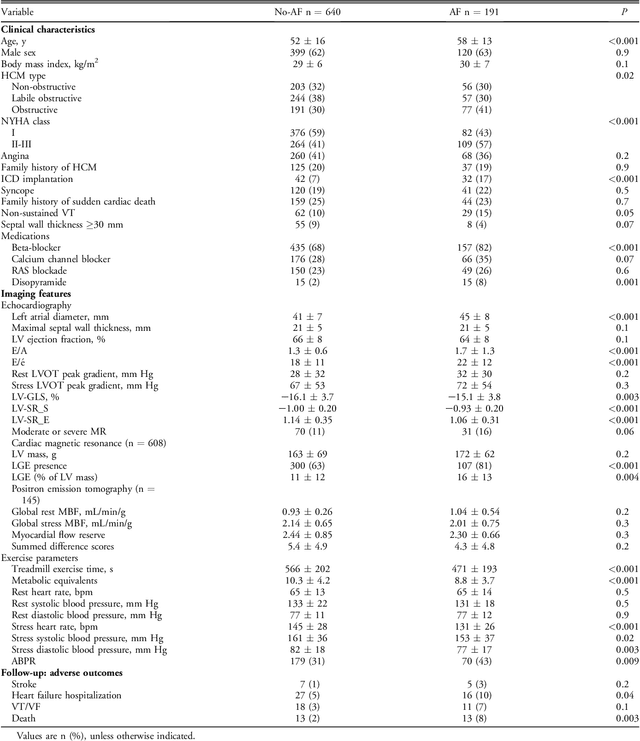
Hypertrophic cardiomyopathy (HCM) patients have a high incidence of atrial fibrillation (AF) and increased stroke risk, even with low risk of congestive heart failure, hypertension, age, diabetes, previous stroke/transient ischemic attack scores. Hence, there is a need to understand the pathophysiology of AF and stroke in HCM. In this retrospective study, we develop and apply a data-driven, machine learning based method to identify AF cases, and clinical and imaging features associated with AF, using electronic health record data. HCM patients with documented paroxysmal/persistent/permanent AF (n = 191) were considered AF cases, and the remaining patients in sinus rhythm (n = 640) were tagged as No-AF. We evaluated 93 clinical variables and the most informative variables useful for distinguishing AF from No-AF cases were selected based on the 2-sample t test and the information gain criterion. We identified 18 highly informative variables that are positively (n = 11) and negatively (n = 7) correlated with AF in HCM. Next, patient records were represented via these 18 variables. Data imbalance resulting from the relatively low number of AF cases was addressed via a combination of oversampling and under-sampling strategies. We trained and tested multiple classifiers under this sampling approach, showing effective classification. Specifically, an ensemble of logistic regression and naive Bayes classifiers, trained based on the 18 variables and corrected for data imbalance, proved most effective for separating AF from No-AF cases (sensitivity = 0.74, specificity = 0.70, C-index = 0.80). Our model is the first machine learning based method for identification of AF cases in HCM. This model demonstrates good performance, addresses data imbalance, and suggests that AF is associated with a more severe cardiac HCM phenotype.
Co-occurrence of medical conditions: Exposing patterns through probabilistic topic modeling of SNOMED codes
Sep 19, 2021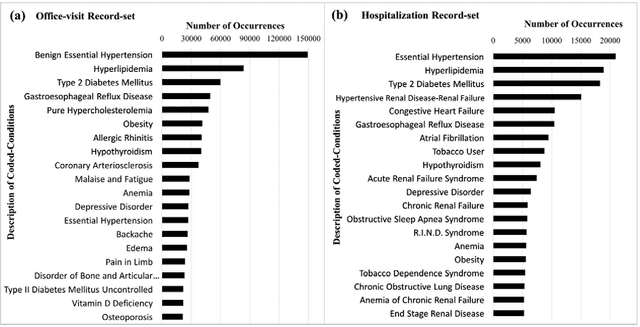
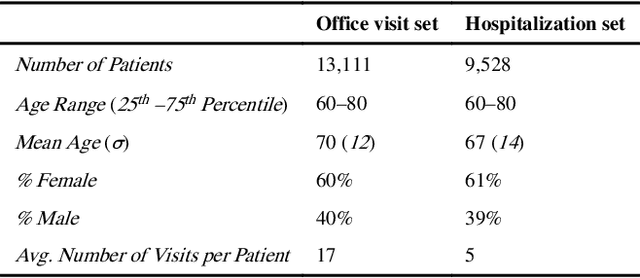
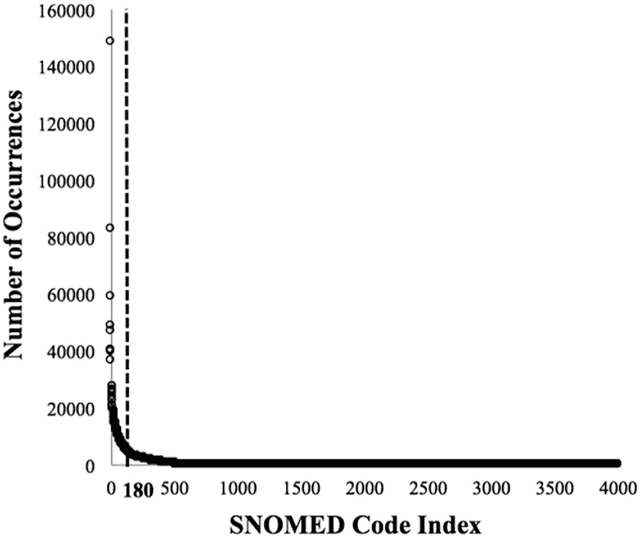
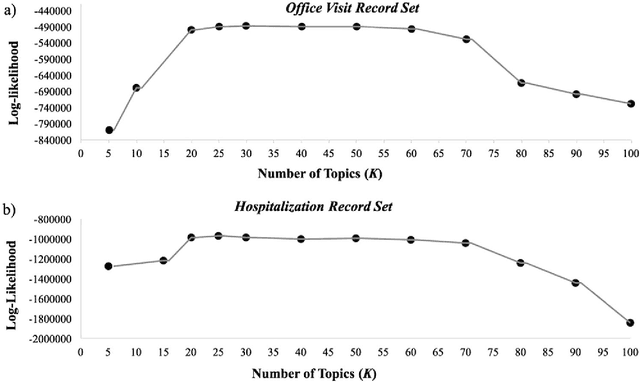
Patients associated with multiple co-occurring health conditions often face aggravated complications and less favorable outcomes. Co-occurring conditions are especially prevalent among individuals suffering from kidney disease, an increasingly widespread condition affecting 13% of the general population in the US. This study aims to identify and characterize patterns of co-occurring medical conditions in patients employing a probabilistic framework. Specifically, we apply topic modeling in a non-traditional way to find associations across SNOMEDCT codes assigned and recorded in the EHRs of>13,000 patients diagnosed with kidney disease. Unlike most prior work on topic modeling, we apply the method to codes rather than to natural language. Moreover, we quantitatively evaluate the topics, assessing their tightness and distinctiveness, and also assess the medical validity of our results. Our experiments show that each topic is succinctly characterized by a few highly probable and unique disease codes, indicating that the topics are tight. Furthermore, inter-topic distance between each pair of topics is typically high, illustrating distinctiveness. Last, most coded conditions grouped together within a topic, are indeed reported to co-occur in the medical literature. Notably, our results uncover a few indirect associations among conditions that have hitherto not been reported as correlated in the medical literature.
Identifying Patterns of Associated-Conditions through Topic Models of Electronic Medical Records
Nov 17, 2017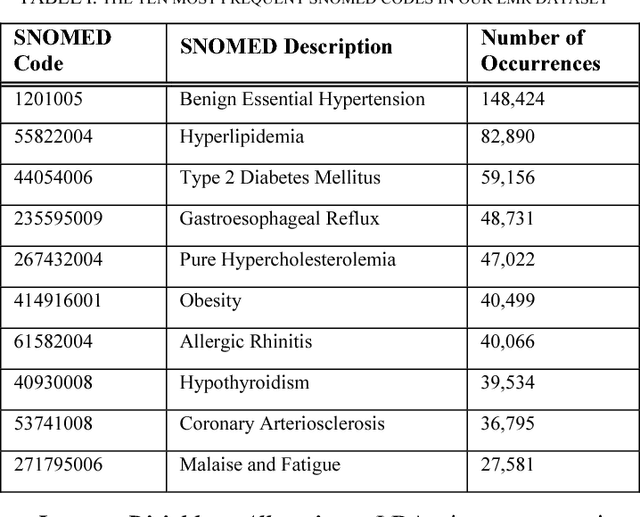
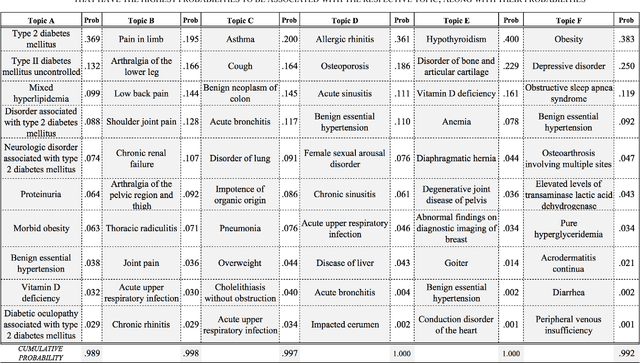
Multiple adverse health conditions co-occurring in a patient are typically associated with poor prognosis and increased office or hospital visits. Developing methods to identify patterns of co-occurring conditions can assist in diagnosis. Thus identifying patterns of associations among co-occurring conditions is of growing interest. In this paper, we report preliminary results from a data-driven study, in which we apply a machine learning method, namely, topic modeling, to electronic medical records, aiming to identify patterns of associated conditions. Specifically, we use the well established latent dirichlet allocation, a method based on the idea that documents can be modeled as a mixture of latent topics, where each topic is a distribution over words. In our study, we adapt the LDA model to identify latent topics in patients' EMRs. We evaluate the performance of our method both qualitatively, and show that the obtained topics indeed align well with distinct medical phenomena characterized by co-occurring conditions.
Identifying Growth-Patterns in Children by Applying Cluster analysis to Electronic Medical Records
Aug 16, 2017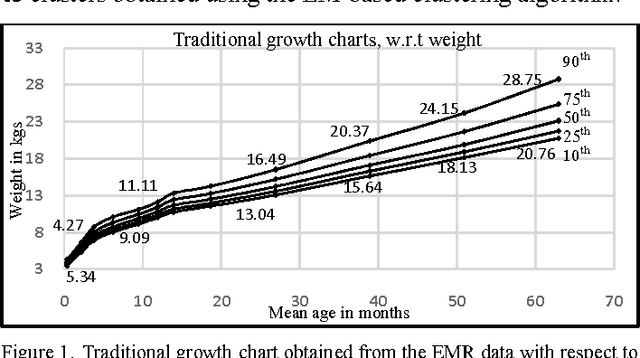
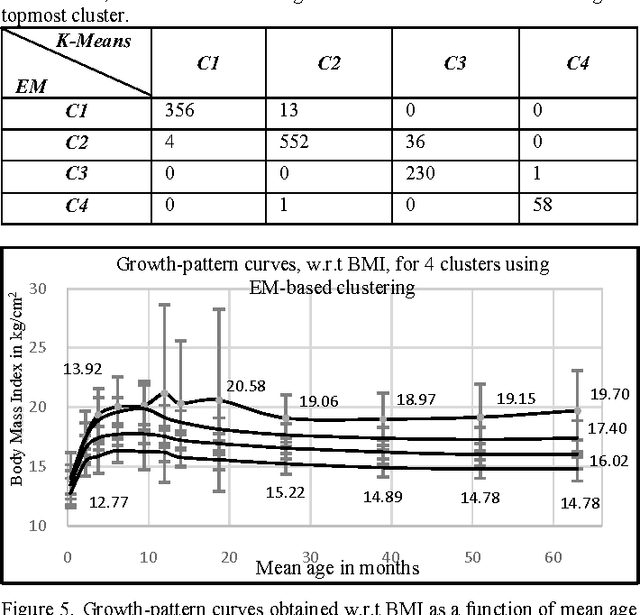
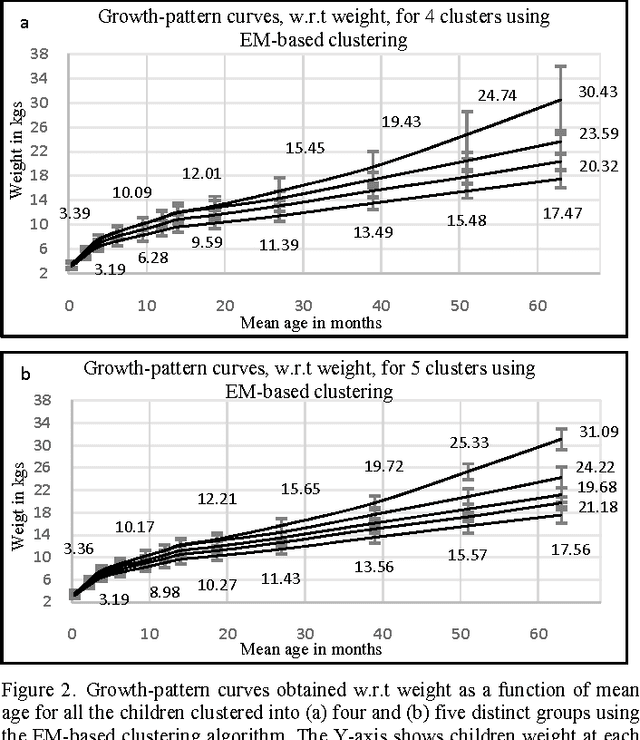
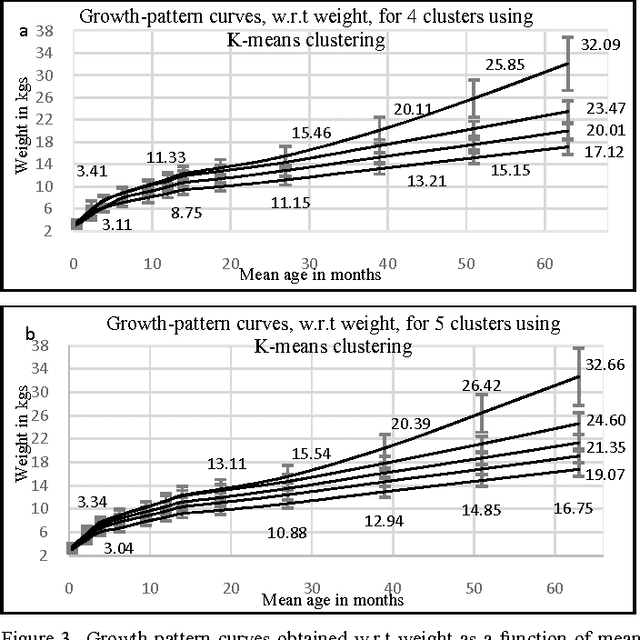
Obesity is one of the leading health concerns in the United States. Researchers and health care providers are interested in understanding factors affecting obesity and detecting the likelihood of obesity as early as possible. In this paper, we set out to recognize children who have higher risk of obesity by identifying distinct growth patterns in them. This is done by using clustering methods, which group together children who share similar body measurements over a period of time. The measurements characterizing children within the same cluster are plotted as a function of age. We refer to these plots as growthpattern curves. We show that distinct growth-pattern curves are associated with different clusters and thus can be used to separate children into the topmost (heaviest), middle, or bottom-most cluster based on early growth measurements.