 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Aware Spoken Language Translation Applied to English-Arabic
Feb 26, 2018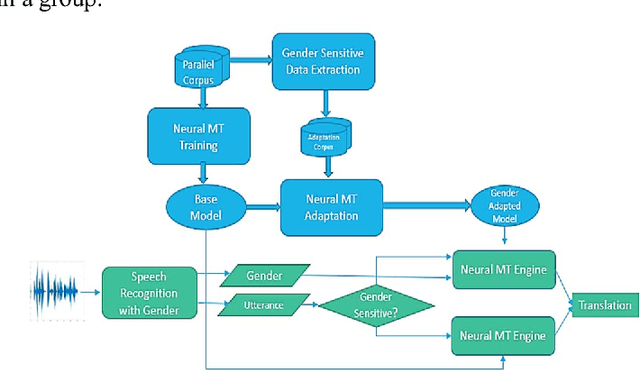
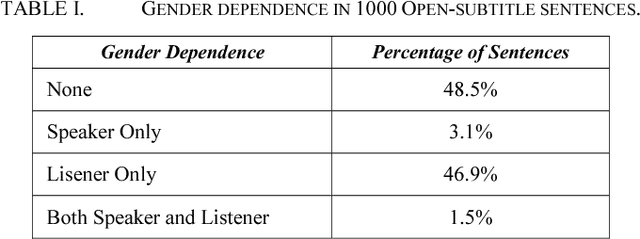
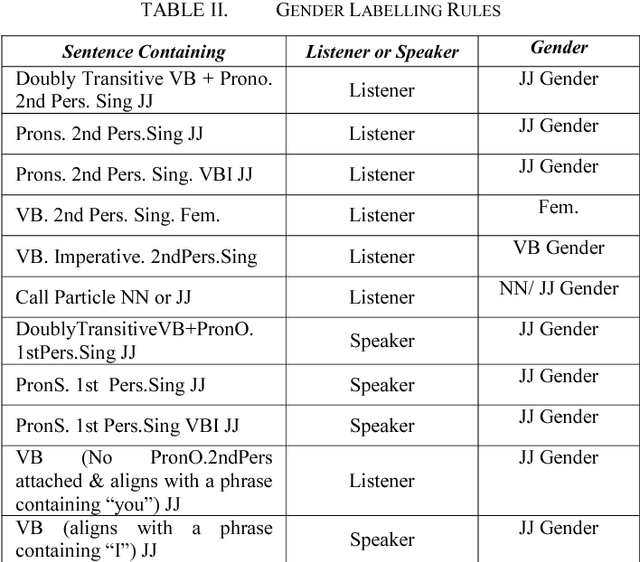
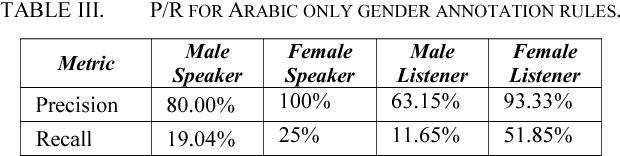
Spoken Language Translation (SLT) is becoming more widely used and becoming a communication tool that helps in crossing language barriers. One of the challenges of SLT is the translation from a language without gender agreement to a language with gender agreement such as English to Arabic. In this paper, we introduce an approach to tackle such limitation by enabling a Neural Machine Translation system to produce gender-aware translation. We show that NMT system can model the speaker/listener gender information to produce gender-aware translation. We propose a method to generate data used in adapting a NMT system to produce gender-aware. The proposed approach can achieve significant improvement of the translation quality by 2 BLEU points.
Synthetic Data for Neural Machine Translation of Spoken-Dialects
Nov 28, 2017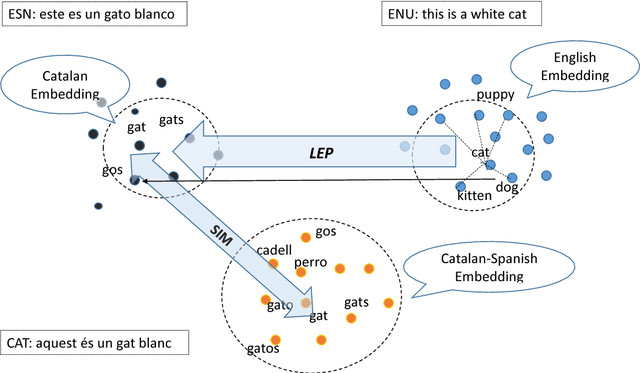
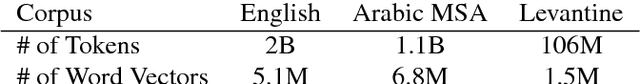
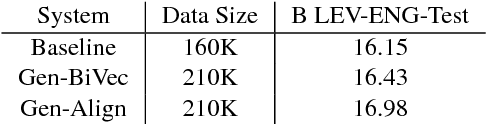

In this paper, we introduce a novel approach to generate synthetic data for training Neural Machine Translation systems. The proposed approach transforms a given parallel corpus between a written language and a target language to a parallel corpus between a spoken dialect variant and the target language. Our approach is language independent and can be used to generate data for any variant of the source language such as slang or spoken dialect or even for a different language that is closely related to the source language. The proposed approach is based on local embedding projection of distributed representations which utilizes monolingual embeddings to transform parallel data across language variants. We report experimental results on Levantine to English translation using Neural Machine Translation. We show that the generated data can improve a very large scale system by more than 2.8 Bleu points using synthetic spoken data which shows that it can be used to provide a reliable translation system for a spoken dialect that does not have sufficient parallel data.