 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputationally Efficient Replicable Learning of Parities
Feb 10, 2026We study the computational relationship between replicability (Impagliazzo et al. [STOC `22], Ghazi et al. [NeurIPS `21]) and other stability notions. Specifically, we focus on replicable PAC learning and its connections to differential privacy (Dwork et al. [TCC 2006]) and to the statistical query (SQ) model (Kearns [JACM `98]). Statistically, it was known that differentially private learning and replicable learning are equivalent and strictly more powerful than SQ-learning. Yet, computationally, all previously known efficient (i.e., polynomial-time) replicable learning algorithms were confined to SQ-learnable tasks or restricted distributions, in contrast to differentially private learning. Our main contribution is the first computationally efficient replicable algorithm for realizable learning of parities over arbitrary distributions, a task that is known to be hard in the SQ-model, but possible under differential privacy. This result provides the first evidence that efficient replicable learning over general distributions strictly extends efficient SQ-learning, and is closer in power to efficient differentially private learning, despite computational separations between replicability and privacy. Our main building block is a new, efficient, and replicable algorithm that, given a set of vectors, outputs a subspace of their linear span that covers most of them.
Fast and Bayes-consistent nearest neighbors
Oct 07, 2019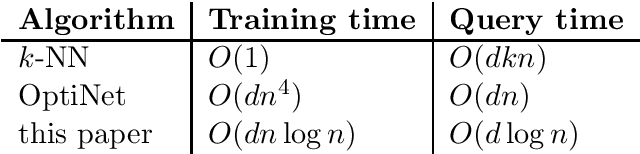
Research on nearest-neighbor methods tends to focus somewhat dichotomously either on the statistical or the computational aspects -- either on, say, Bayes consistency and rates of convergence or on techniques for speeding up the proximity search. This paper aims at bridging these realms: to reap the advantages of fast evaluation time while maintaining Bayes consistency, and further without sacrificing too much in the risk decay rate. We combine the locality-sensitive hashing (LSH) technique with a novel missing-mass argument to obtain a fast and Bayes-consistent classifier. Our algorithm's prediction runtime compares favorably against state of the art approximate NN methods, while maintaining Bayes-consistency and attaining rates comparable to minimax. On samples of size $n$ in $\R^d$, our pre-processing phase has runtime $O(d n \log n)$, while the evaluation phase has runtime $O(d\log n)$ per query point.