 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Cross-Lingual Stance Detection with Sentiment-Based Pre-Training
Sep 13, 2021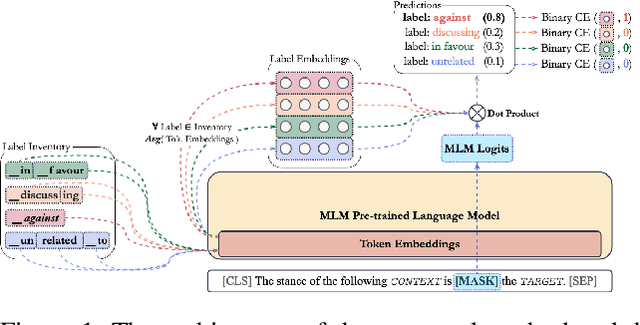
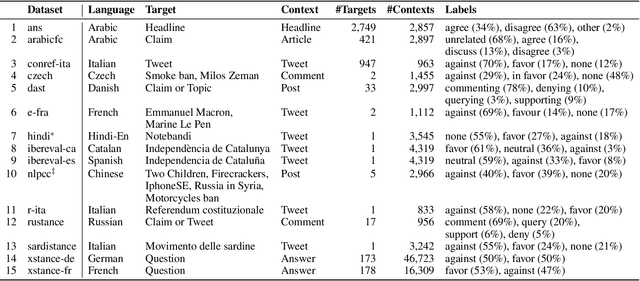
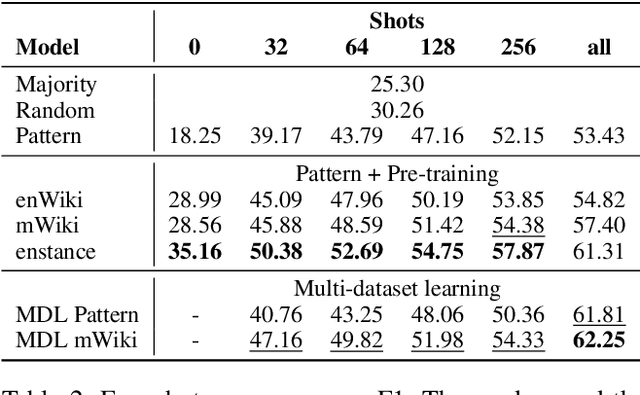
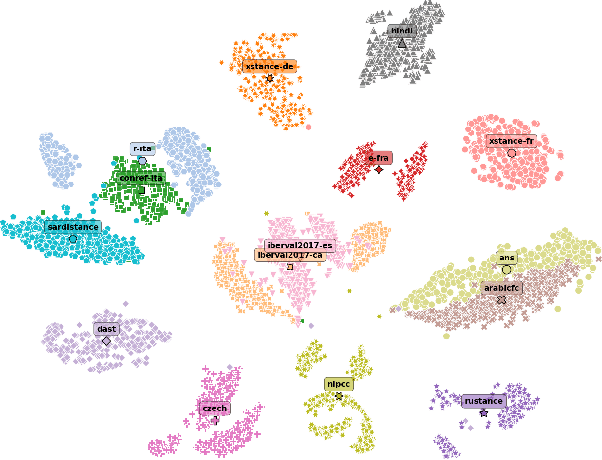
The goal of stance detection is to determine the viewpoint expressed in a piece of text towards a target. These viewpoints or contexts are often expressed in many different languages depending on the user and the platform, which can be a local news outlet, a social media platform, a news forum, etc. Most research in stance detection, however, has been limited to working with a single language and on a few limited targets, with little work on cross-lingual stance detection. Moreover, non-English sources of labelled data are often scarce and present additional challenges. Recently, large multilingual language models have substantially improved the performance on many non-English tasks, especially such with limited numbers of examples. This highlights the importance of model pre-training and its ability to learn from few examples. In this paper, we present the most comprehensive study of cross-lingual stance detection to date: we experiment with 15 diverse datasets in 12 languages from 6 language families, and with 6 low-resource evaluation settings each. For our experiments, we build on pattern-exploiting training, proposing the addition of a novel label encoder to simplify the verbalisation procedure. We further propose sentiment-based generation of stance data for pre-training, which shows sizeable improvement of more than 6% F1 absolute in low-shot settings compared to several strong baselines.
Generating Answer Candidates for Quizzes and Answer-Aware Question Generators
Aug 29, 2021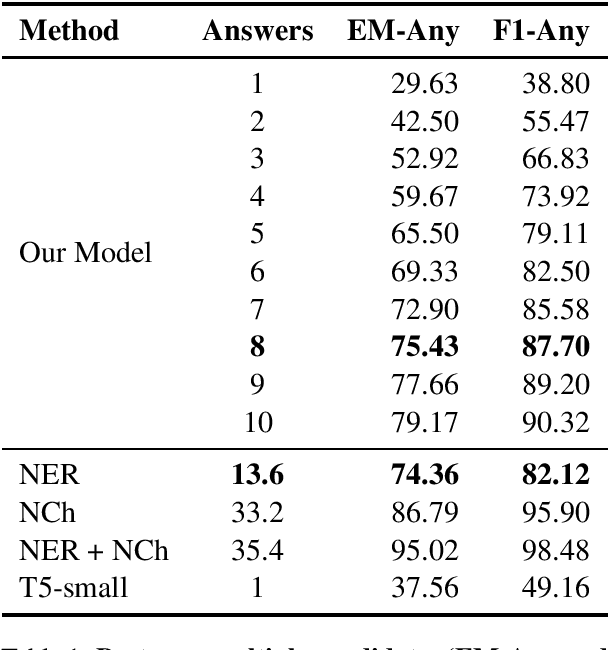
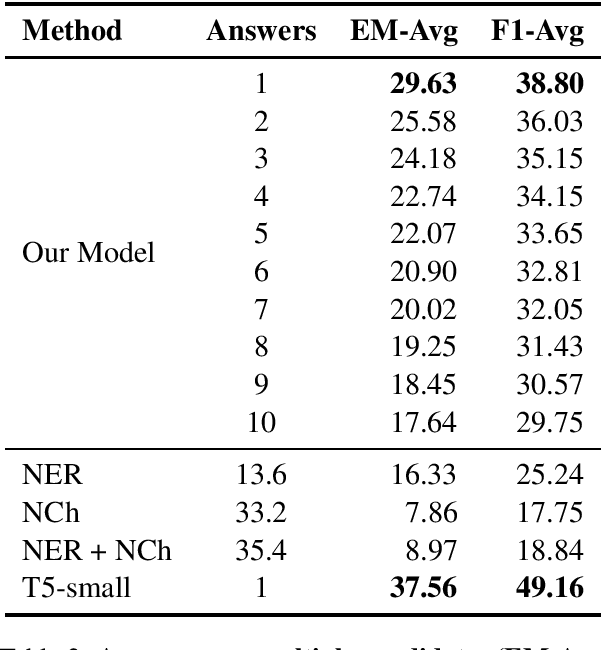

In education, open-ended quiz questions have become an important tool for assessing the knowledge of students. Yet, manually preparing such questions is a tedious task, and thus automatic question generation has been proposed as a possible alternative. So far, the vast majority of research has focused on generating the question text, relying on question answering datasets with readily picked answers, and the problem of how to come up with answer candidates in the first place has been largely ignored. Here, we aim to bridge this gap. In particular, we propose a model that can generate a specified number of answer candidates for a given passage of text, which can then be used by instructors to write questions manually or can be passed as an input to automatic answer-aware question generators. Our experiments show that our proposed answer candidate generation model outperforms several baselines.
* answer generation, question generation, answer-aware question generation, quiz questions, question answering
Cross-Domain Label-Adaptive Stance Detection
Apr 15, 2021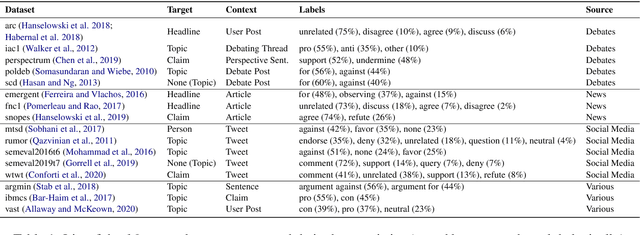
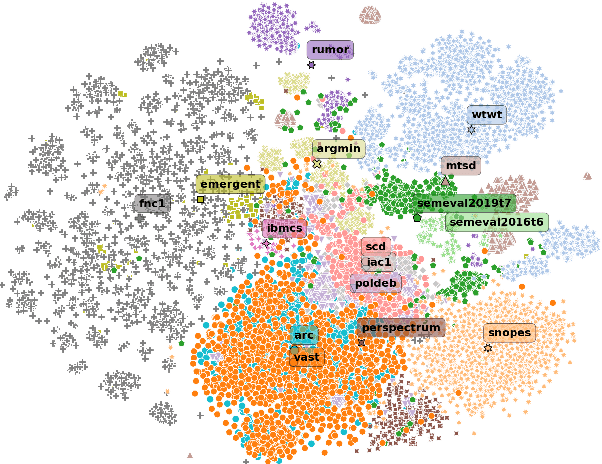
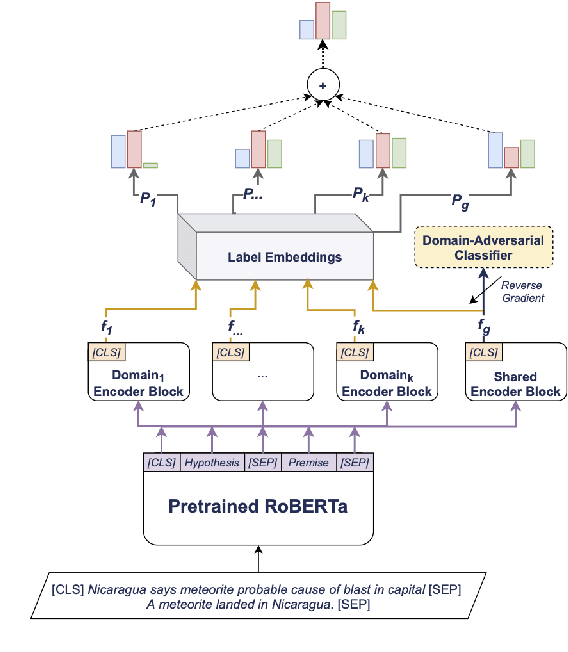
Stance detection concerns the classification of a writer's viewpoint towards a target. There are different task variants, e.g., stance of a tweet vs. a full article, or stance with respect to a claim vs. an (implicit) topic. Moreover, task definitions vary, which includes the label inventory, the data collection, and the annotation protocol. All these aspects hinder cross-domain studies, as they require changes to standard domain adaptation approaches. In this paper, we perform an in-depth analysis of 16 stance detection datasets, and we explore the possibility for cross-domain learning from them. Moreover, we propose an end-to-end unsupervised framework for out-of-domain prediction of unseen, user-defined labels. In particular, we combine domain adaptation techniques such as mixture of experts and domain-adversarial training with label embeddings, and we demonstrate sizable performance gains over strong baselines -- both (i) in-domain, i.e., for seen targets, and (ii) out-of-domain, i.e., for unseen targets. Finally, we perform an exhaustive analysis of the cross-domain results, and we highlight the important factors influencing the model performance.
A Neighbourhood Framework for Resource-Lean Content Flagging
Mar 31, 2021
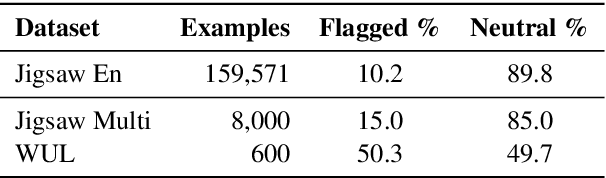
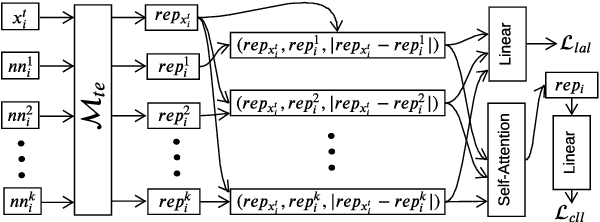
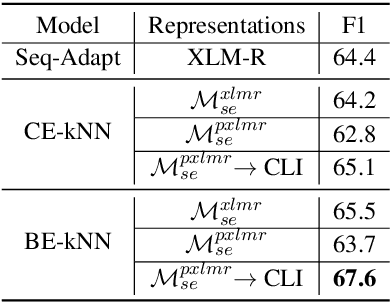
We propose a novel interpretable framework for cross-lingual content flagging, which significantly outperforms prior work both in terms of predictive performance and average inference time. The framework is based on a nearest-neighbour architecture and is interpretable by design. Moreover, it can easily adapt to new instances without the need to retrain it from scratch. Unlike prior work, (i) we encode not only the texts, but also the labels in the neighbourhood space (which yields better accuracy), and (ii) we use a bi-encoder instead of a cross-encoder (which saves computation time). Our evaluation results on ten different datasets for abusive language detection in eight languages shows sizable improvements over the state of the art, as well as a speed-up at inference time.
A Survey on Stance Detection for Mis- and Disinformation Identification
Feb 27, 2021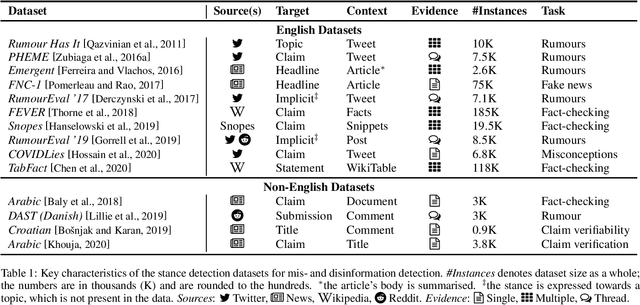
Detecting attitudes expressed in texts, also known as stance detection, has become an important task for the detection of false information online, be it misinformation (unintentionally false) or disinformation (intentionally false, spread deliberately with malicious intent). Stance detection has been framed in different ways, including: (a) as a component of fact-checking, rumour detection, and detecting previously fact-checked claims; or (b) as a task in its own right. While there have been prior efforts to contrast stance detection with other related social media tasks such as argumentation mining and sentiment analysis, there is no survey examining the relationship between stance detection detection and mis- and disinformation detection from a holistic viewpoint, which is the focus of this survey. We review and analyse existing work in this area, before discussing lessons learnt and future challenges.
Detecting Abusive Language on Online Platforms: A Critical Analysis
Feb 27, 2021
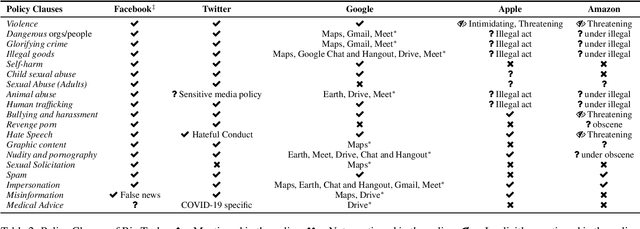
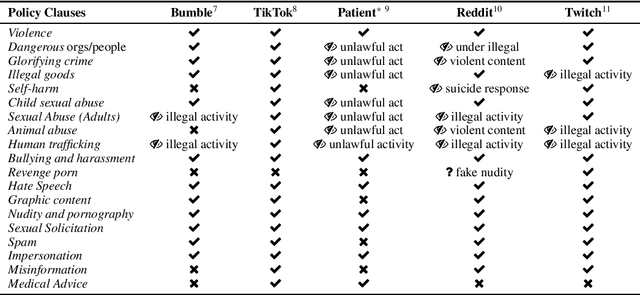

Abusive language on online platforms is a major societal problem, often leading to important societal problems such as the marginalisation of underrepresented minorities. There are many different forms of abusive language such as hate speech, profanity, and cyber-bullying, and online platforms seek to moderate it in order to limit societal harm, to comply with legislation, and to create a more inclusive environment for their users. Within the field of Natural Language Processing, researchers have developed different methods for automatically detecting abusive language, often focusing on specific subproblems or on narrow communities, as what is considered abusive language very much differs by context. We argue that there is currently a dichotomy between what types of abusive language online platforms seek to curb, and what research efforts there are to automatically detect abusive language. We thus survey existing methods as well as content moderation policies by online platforms in this light, and we suggest directions for future work.
EXAMS: A Multi-Subject High School Examinations Dataset for Cross-Lingual and Multilingual Question Answering
Nov 05, 2020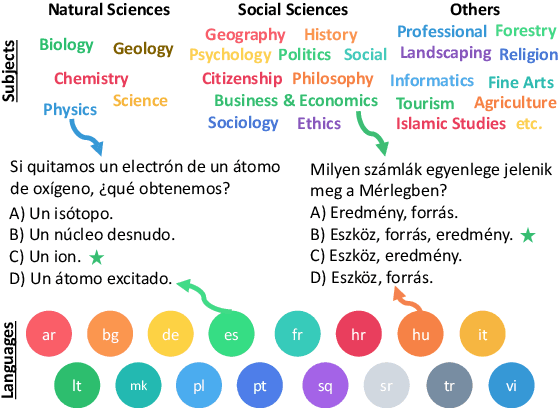
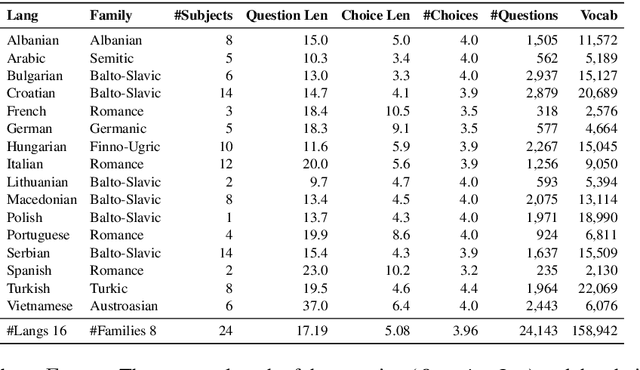

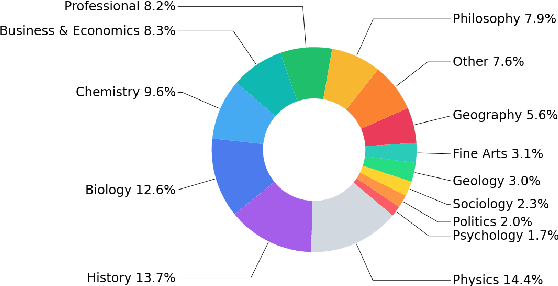
We propose EXAMS -- a new benchmark dataset for cross-lingual and multilingual question answering for high school examinations. We collected more than 24,000 high-quality high school exam questions in 16 languages, covering 8 language families and 24 school subjects from Natural Sciences and Social Sciences, among others. EXAMS offers a fine-grained evaluation framework across multiple languages and subjects, which allows precise analysis and comparison of various models. We perform various experiments with existing top-performing multilingual pre-trained models and we show that EXAMS offers multiple challenges that require multilingual knowledge and reasoning in multiple domains. We hope that EXAMS will enable researchers to explore challenging reasoning and knowledge transfer methods and pre-trained models for school question answering in various languages which was not possible before. The data, code, pre-trained models, and evaluation are available at https://github.com/mhardalov/exams-qa.
Enriched Pre-trained Transformers for Joint Slot Filling and Intent Detection
Apr 30, 2020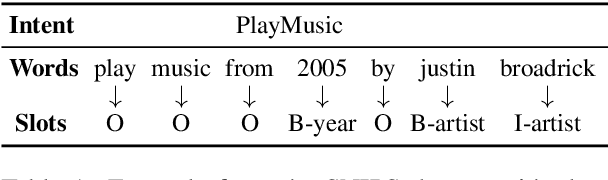
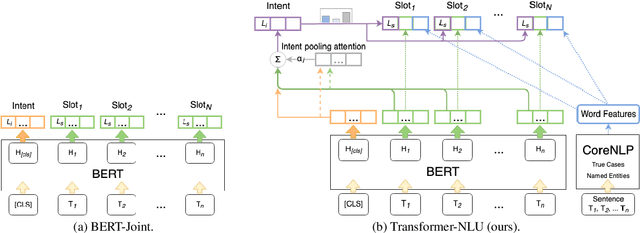
Detecting the user's intent and finding the corresponding slots among the utterance's words are important tasks in natural language understanding. Their interconnected nature makes their joint modeling a standard part of training such models. Moreover, data scarceness and specialized vocabularies pose additional challenges. Recently, the advances in pre-trained language models, namely contextualized models such as ELMo and BERT have revolutionized the field by tapping the potential of training very large models with just a few steps of fine-tuning on a task-specific dataset. Here, we leverage such model, namely BERT, and we design a novel architecture on top it. Moreover, we propose an intent pooling attention mechanism, and we reinforce the slot filling task by fusing intent distributions, word features, and token representations. The experimental results on standard datasets show that our model outperforms both the current non-BERT state of the art as well as some stronger BERT-based baselines.
In Search of Credible News
Nov 19, 2019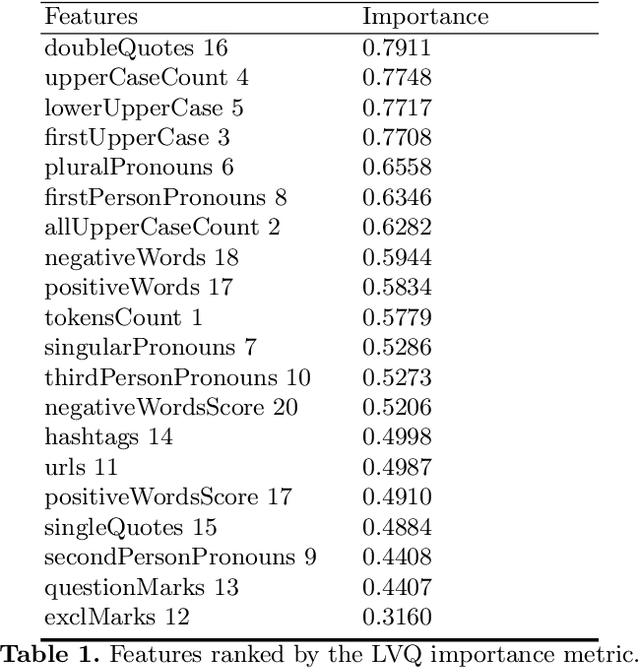
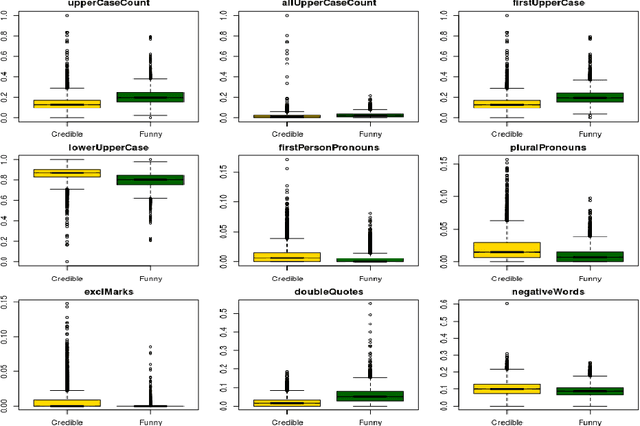
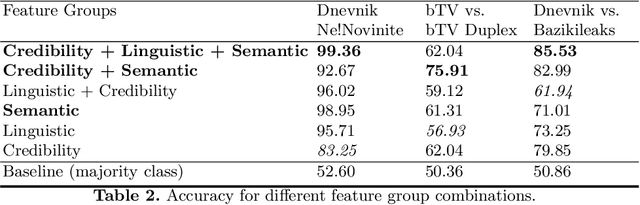
We study the problem of finding fake online news. This is an important problem as news of questionable credibility have recently been proliferating in social media at an alarming scale. As this is an understudied problem, especially for languages other than English, we first collect and release to the research community three new balanced credible vs. fake news datasets derived from four online sources. We then propose a language-independent approach for automatically distinguishing credible from fake news, based on a rich feature set. In particular, we use linguistic (n-gram), credibility-related (capitalization, punctuation, pronoun use, sentiment polarity), and semantic (embeddings and DBPedia data) features. Our experiments on three different testsets show that our model can distinguish credible from fake news with very high accuracy.
* Credibility, veracity, fact checking, humor detection
Beyond English-Only Reading Comprehension: Experiments in Zero-Shot Multilingual Transfer for Bulgarian
Sep 06, 2019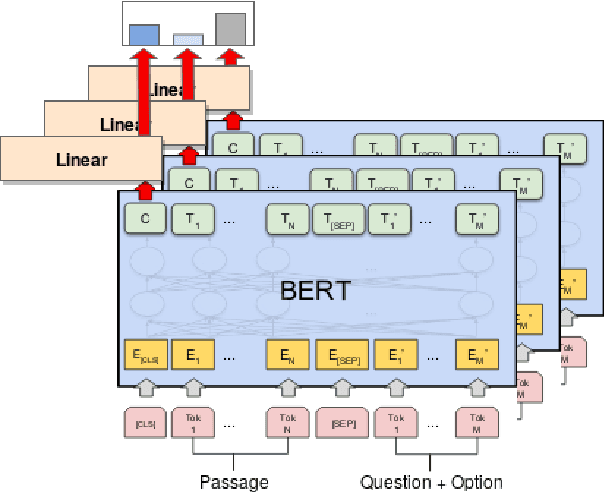
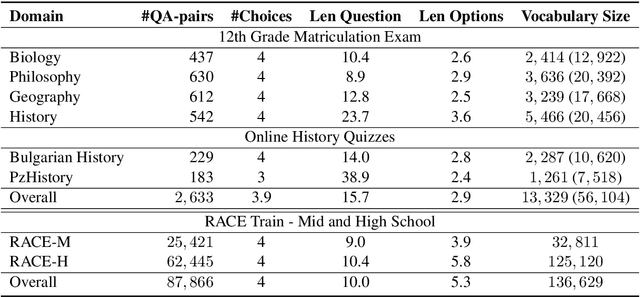

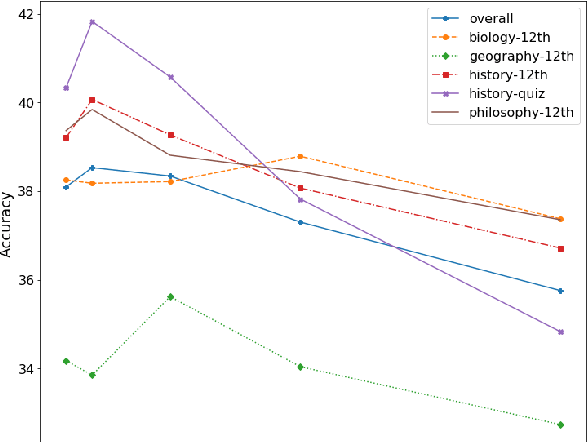
Recently, reading comprehension models achieved near-human performance on large-scale datasets such as SQuAD, CoQA, MS Macro, RACE, etc. This is largely due to the release of pre-trained contextualized representations such as BERT and ELMo, which can be fine-tuned for the target task. Despite those advances and the creation of more challenging datasets, most of the work is still done for English. Here, we study the effectiveness of multilingual BERT fine-tuned on large-scale English datasets for reading comprehension (e.g., for RACE), and we apply it to Bulgarian multiple-choice reading comprehension. We propose a new dataset containing 2,221 questions from matriculation exams for twelfth grade in various subjects -history, biology, geography and philosophy-, and 412 additional questions from online quizzes in history. While the quiz authors gave no relevant context, we incorporate knowledge from Wikipedia, retrieving documents matching the combination of question + each answer option. Moreover, we experiment with different indexing and pre-training strategies. The evaluation results show accuracy of 42.23%, which is well above the baseline of 24.89%.