 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnPoint: Offline-to-Online Multi-Level Distillation for Point-Supervised Online Temporal Action Localization
Jul 01, 2026Temporal Action Localization (TAL) typically relies on segment annotations or offline access to full videos, limiting scalability and online use. We introduce Point-Supervised Online TAL (POTAL), which localizes actions in streaming videos using only one temporal point per instance. To solve POTAL, we propose OnPoint, an offline-to-online multi-level distillation framework that transfers knowledge from a point-supervised offline teacher to an online student via (i) pseudo-segment instance distillation, (ii) class-activation sequence distillation, and (iii) anticipatory window-level distillation. We further improve robustness by incorporating the original point labels into student training and by refining anchor decoding with actionness-guided attention calibration. Experiments on five datasets show OnPoint consistently outperforms strong baselines, establishing a solid foundation for POTAL.
REEF: Relevance-Aware and Efficient LLM Adapter for Video Understanding
Apr 07, 2025Integrating vision models into large language models (LLMs) has sparked significant interest in creating vision-language foundation models, especially for video understanding. Recent methods often utilize memory banks to handle untrimmed videos for video-level understanding. However, they typically compress visual memory using similarity-based greedy approaches, which can overlook the contextual importance of individual tokens. To address this, we introduce an efficient LLM adapter designed for video-level understanding of untrimmed videos that prioritizes the contextual relevance of spatio-temporal tokens. Our framework leverages scorer networks to selectively compress the visual memory bank and filter spatial tokens based on relevance, using a differentiable Top-K operator for end-to-end training. Across three key video-level understanding tasks$\unicode{x2013}$ untrimmed video classification, video question answering, and video captioning$\unicode{x2013}$our method achieves competitive or superior results on four large-scale datasets while reducing computational overhead by up to 34%. The code will be available soon on GitHub.
Exploring Eye Tracking to Detect Cognitive Load in Complex Virtual Reality Training
Nov 18, 2024

Virtual Reality (VR) has been a beneficial training tool in fields such as advanced manufacturing. However, users may experience a high cognitive load due to various factors, such as the use of VR hardware or tasks within the VR environment. Studies have shown that eye-tracking has the potential to detect cognitive load, but in the context of VR and complex spatiotemporal tasks (e.g., assembly and disassembly), it remains relatively unexplored. Here, we present an ongoing study to detect users' cognitive load using an eye-tracking-based machine learning approach. We developed a VR training system for cold spray and tested it with 22 participants, obtaining 19 valid eye-tracking datasets and NASA-TLX scores. We applied Multi-Layer Perceptron (MLP) and Random Forest (RF) models to compare the accuracy of predicting cognitive load (i.e., NASA-TLX) using pupil dilation and fixation duration. Our preliminary analysis demonstrates the feasibility of using eye tracking to detect cognitive load in complex spatiotemporal VR experiences and motivates further exploration.
HAT: History-Augmented Anchor Transformer for Online Temporal Action Localization
Aug 12, 2024



Online video understanding often relies on individual frames, leading to frame-by-frame predictions. Recent advancements such as Online Temporal Action Localization (OnTAL), extend this approach to instance-level predictions. However, existing methods mainly focus on short-term context, neglecting historical information. To address this, we introduce the History-Augmented Anchor Transformer (HAT) Framework for OnTAL. By integrating historical context, our framework enhances the synergy between long-term and short-term information, improving the quality of anchor features crucial for classification and localization. We evaluate our model on both procedural egocentric (PREGO) datasets (EGTEA and EPIC) and standard non-PREGO OnTAL datasets (THUMOS and MUSES). Results show that our model outperforms state-of-the-art approaches significantly on PREGO datasets and achieves comparable or slightly superior performance on non-PREGO datasets, underscoring the importance of leveraging long-term history, especially in procedural and egocentric action scenarios. Code is available at: https://github.com/sakibreza/ECCV24-HAT/
Enhancing Transformer Backbone for Egocentric Video Action Segmentation
May 23, 2023Egocentric temporal action segmentation in videos is a crucial task in computer vision with applications in various fields such as mixed reality, human behavior analysis, and robotics. Although recent research has utilized advanced visual-language frameworks, transformers remain the backbone of action segmentation models. Therefore, it is necessary to improve transformers to enhance the robustness of action segmentation models. In this work, we propose two novel ideas to enhance the state-of-the-art transformer for action segmentation. First, we introduce a dual dilated attention mechanism to adaptively capture hierarchical representations in both local-to-global and global-to-local contexts. Second, we incorporate cross-connections between the encoder and decoder blocks to prevent the loss of local context by the decoder. We also utilize state-of-the-art visual-language representation learning techniques to extract richer and more compact features for our transformer. Our proposed approach outperforms other state-of-the-art methods on the Georgia Tech Egocentric Activities (GTEA) and HOI4D Office Tools datasets, and we validate our introduced components with ablation studies. The source code and supplementary materials are publicly available on https://www.sail-nu.com/dxformer.
Adaptable Automation with Modular Deep Reinforcement Learning and Policy Transfer
Nov 27, 2020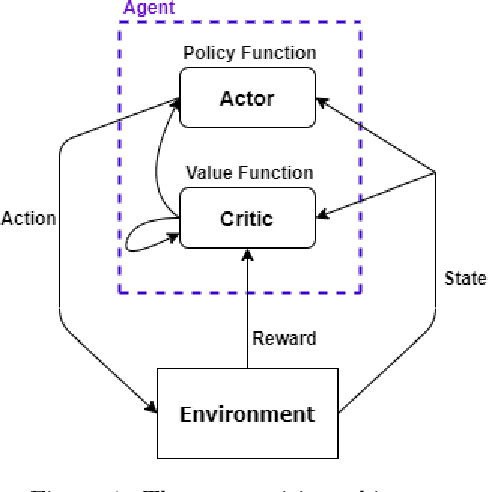
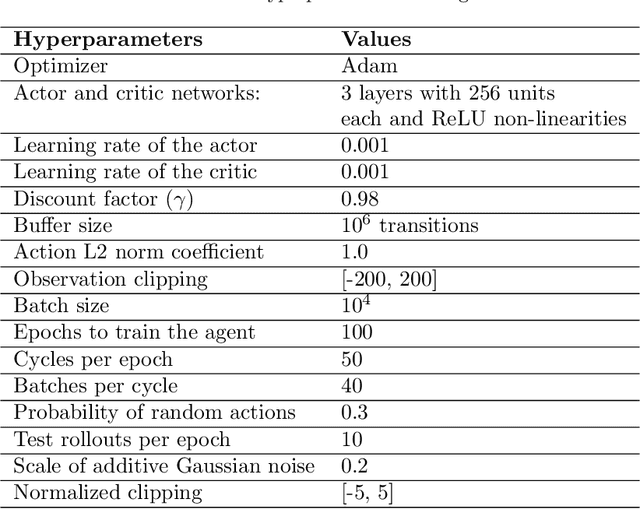
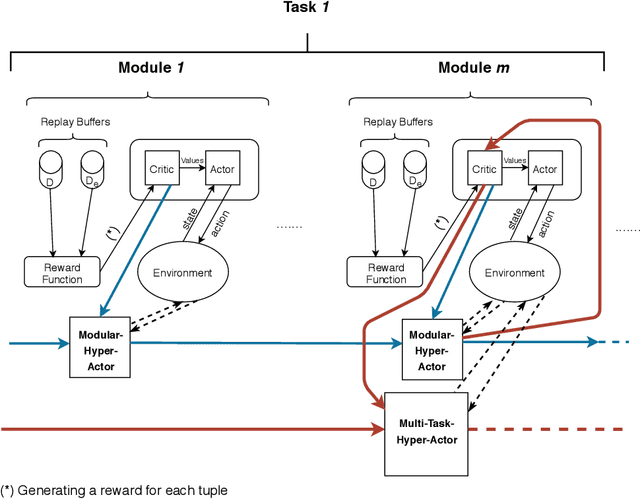
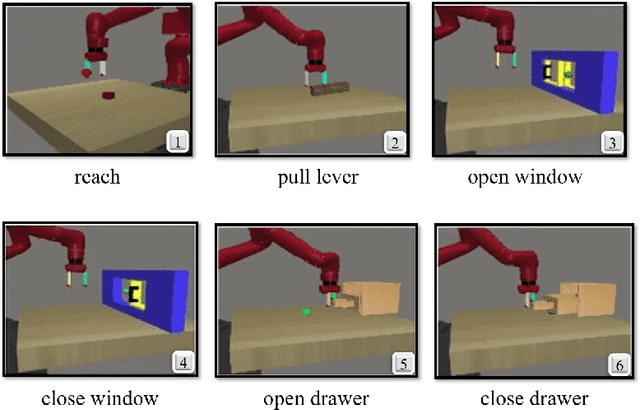
Recent advances in deep Reinforcement Learning (RL) have created unprecedented opportunities for intelligent automation, where a machine can autonomously learn an optimal policy for performing a given task. However, current deep RL algorithms predominantly specialize in a narrow range of tasks, are sample inefficient, and lack sufficient stability, which in turn hinder their industrial adoption. This article tackles this limitation by developing and testing a Hyper-Actor Soft Actor-Critic (HASAC) RL framework based on the notions of task modularization and transfer learning. The goal of the proposed HASAC is to enhance the adaptability of an agent to new tasks by transferring the learned policies of former tasks to the new task via a "hyper-actor". The HASAC framework is tested on a new virtual robotic manipulation benchmark, Meta-World. Numerical experiments show superior performance by HASAC over state-of-the-art deep RL algorithms in terms of reward value, success rate, and task completion time.
Garment Design with Generative Adversarial Networks
Jul 23, 2020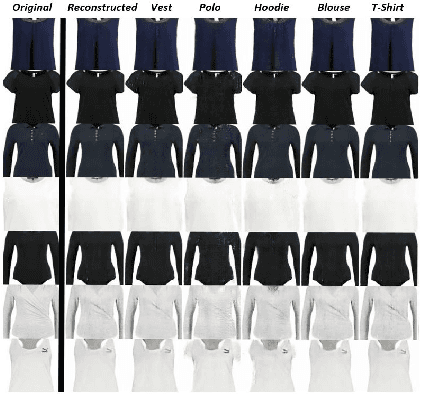



The designers' tendency to adhere to a specific mental set and heavy emotional investment in their initial ideas often hinder their ability to innovate during the design thinking and ideation process. In the fashion industry, in particular, the growing diversity of customers' needs, the intense global competition, and the shrinking time-to-market (a.k.a., "fast fashion") further exacerbate this challenge for designers. Recent advances in deep generative models have created new possibilities to overcome the cognitive obstacles of designers through automated generation and/or editing of design concepts. This paper explores the capabilities of generative adversarial networks (GAN) for automated attribute-level editing of design concepts. Specifically, attribute GAN (AttGAN)---a generative model proven successful for attribute editing of human faces---is utilized for automated editing of the visual attributes of garments and tested on a large fashion dataset. The experiments support the hypothesized potentials of GAN for attribute-level editing of design concepts, and underscore several key limitations and research questions to be addressed in future work.