 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Model Properties via Conformal Risk Control
Jun 26, 2024



AI model alignment is crucial due to inadvertent biases in training data and the underspecified pipeline in modern machine learning, where numerous models with excellent test set metrics can be produced, yet they may not meet end-user requirements. Recent advances demonstrate that post-training model alignment via human feedback can address some of these challenges. However, these methods are often confined to settings (such as generative AI) where humans can interpret model outputs and provide feedback. In traditional non-generative settings, where model outputs are numerical values or classes, detecting misalignment through single-sample outputs is highly challenging. In this paper we consider an alternative strategy. We propose interpreting model alignment through property testing, defining an aligned model $f$ as one belonging to a subset $\mathcal{P}$ of functions that exhibit specific desired behaviors. We focus on post-processing a pre-trained model $f$ to better align with $\mathcal{P}$ using conformal risk control. Specifically, we develop a general procedure for converting queries for a given property $\mathcal{P}$ to a collection of loss functions suitable for use in a conformal risk control algorithm. We prove a probabilistic guarantee that the resulting conformal interval around $f$ contains a function approximately satisfying $\mathcal{P}$. Given the capabilities of modern AI models with extensive parameters and training data, one might assume alignment issues will resolve naturally. However, increasing training data or parameters in a random feature model doesn't eliminate the need for alignment techniques when pre-training data is biased. We demonstrate our alignment methodology on supervised learning datasets for properties like monotonicity and concavity. Our flexible procedure can be applied to various desired properties.
A Probabilistic Approach for Alignment with Human Comparisons
Mar 16, 2024



A growing trend involves integrating human knowledge into learning frameworks, leveraging subtle human feedback to refine AI models. Despite these advances, no comprehensive theoretical framework describing the specific conditions under which human comparisons improve the traditional supervised fine-tuning process has been developed. To bridge this gap, this paper studies the effective use of human comparisons to address limitations arising from noisy data and high-dimensional models. We propose a two-stage "Supervised Fine Tuning+Human Comparison" (SFT+HC) framework connecting machine learning with human feedback through a probabilistic bisection approach. The two-stage framework first learns low-dimensional representations from noisy-labeled data via an SFT procedure, and then uses human comparisons to improve the model alignment. To examine the efficacy of the alignment phase, we introduce a novel concept termed the "label-noise-to-comparison-accuracy" (LNCA) ratio. This paper theoretically identifies the conditions under which the "SFT+HC" framework outperforms pure SFT approach, leveraging this ratio to highlight the advantage of incorporating human evaluators in reducing sample complexity. We validate that the proposed conditions for the LNCA ratio are met in a case study conducted via an Amazon Mechanical Turk experiment.
Causal Message Passing: A Method for Experiments with Unknown and General Network Interference
Nov 14, 2023



Randomized experiments are a powerful methodology for data-driven evaluation of decisions or interventions. Yet, their validity may be undermined by network interference. This occurs when the treatment of one unit impacts not only its outcome but also that of connected units, biasing traditional treatment effect estimations. Our study introduces a new framework to accommodate complex and unknown network interference, moving beyond specialized models in the existing literature. Our framework, which we term causal message-passing, is grounded in a high-dimensional approximate message passing methodology and is specifically tailored to experimental design settings with prevalent network interference. Utilizing causal message-passing, we present a practical algorithm for estimating the total treatment effect and demonstrate its efficacy in four numerical scenarios, each with its unique interference structure.
Geometry-Aware Approaches for Balancing Performance and Theoretical Guarantees in Linear Bandits
Jun 26, 2023



This paper is motivated by recent developments in the linear bandit literature, which have revealed a discrepancy between the promising empirical performance of algorithms such as Thompson sampling and Greedy, when compared to their pessimistic theoretical regret bounds. The challenge arises from the fact that while these algorithms may perform poorly in certain problem instances, they generally excel in typical instances. To address this, we propose a new data-driven technique that tracks the geometry of the uncertainty ellipsoid, enabling us to establish an instance-dependent frequentist regret bound for a broad class of algorithms, including Greedy, OFUL, and Thompson sampling. This result empowers us to identify and ``course-correct" instances in which the base algorithms perform poorly. The course-corrected algorithms achieve the minimax optimal regret of order $\tilde{\mathcal{O}}(d\sqrt{T})$, while retaining most of the desirable properties of the base algorithms. We present simulation results to validate our findings and compare the performance of our algorithms with the baselines.
Speed Up the Cold-Start Learning in Two-Sided Bandits with Many Arms
Oct 01, 2022



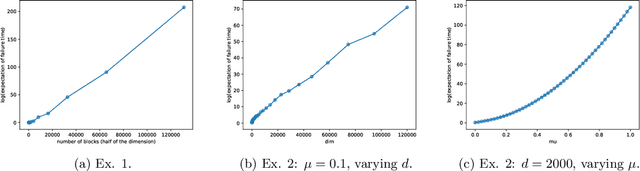
Multi-armed bandit (MAB) algorithms are efficient approaches to reduce the opportunity cost of online experimentation and are used by companies to find the best product from periodically refreshed product catalogs. However, these algorithms face the so-called cold-start at the onset of the experiment due to a lack of knowledge of customer preferences for new products, requiring an initial data collection phase known as the burning period. During this period, MAB algorithms operate like randomized experiments, incurring large burning costs which scale with the large number of products. We attempt to reduce the burning by identifying that many products can be cast into two-sided products, and then naturally model the rewards of the products with a matrix, whose rows and columns represent the two sides respectively. Next, we design two-phase bandit algorithms that first use subsampling and low-rank matrix estimation to obtain a substantially smaller targeted set of products and then apply a UCB procedure on the target products to find the best one. We theoretically show that the proposed algorithms lower costs and expedite the experiment in cases when there is limited experimentation time along with a large product set. Our analysis also reveals three regimes of long, short, and ultra-short horizon experiments, depending on dimensions of the matrix. Empirical evidence from both synthetic data and a real-world dataset on music streaming services validates this superior performance.
Thompson Sampling Efficiently Learns to Control Diffusion Processes
Jun 20, 2022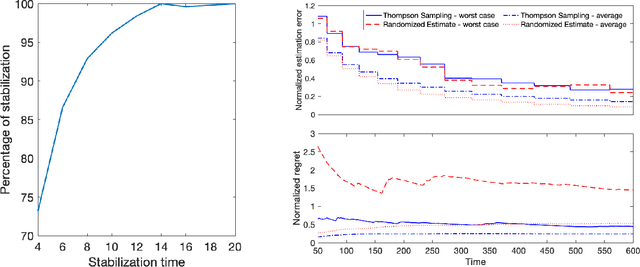
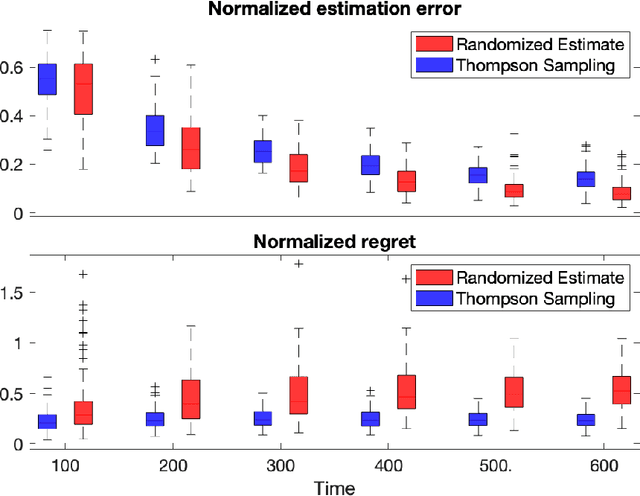
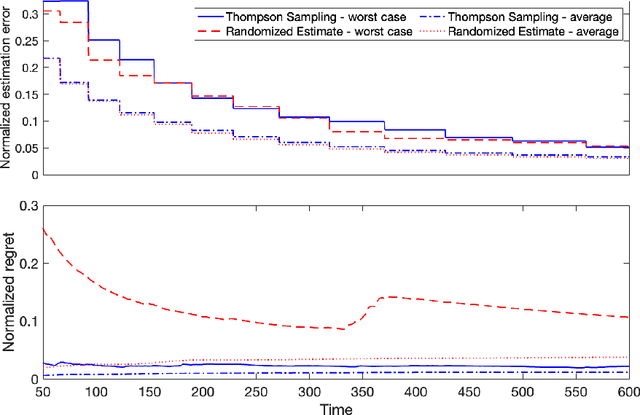
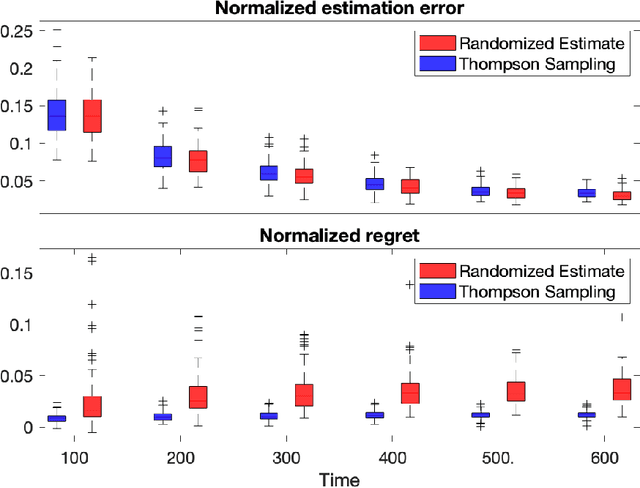
Diffusion processes that evolve according to linear stochastic differential equations are an important family of continuous-time dynamic decision-making models. Optimal policies are well-studied for them, under full certainty about the drift matrices. However, little is known about data-driven control of diffusion processes with uncertain drift matrices as conventional discrete-time analysis techniques are not applicable. In addition, while the task can be viewed as a reinforcement learning problem involving exploration and exploitation trade-off, ensuring system stability is a fundamental component of designing optimal policies. We establish that the popular Thompson sampling algorithm learns optimal actions fast, incurring only a square-root of time regret, and also stabilizes the system in a short time period. To the best of our knowledge, this is the first such result for Thompson sampling in a diffusion process control problem. We validate our theoretical results through empirical simulations with real parameter matrices from two settings of airplane and blood glucose control. Moreover, we observe that Thompson sampling significantly improves (worst-case) regret, compared to the state-of-the-art algorithms, suggesting Thompson sampling explores in a more guarded fashion. Our theoretical analysis involves characterization of a certain optimality manifold that ties the local geometry of the drift parameters to the optimal control of the diffusion process. We expect this technique to be of broader interest.
Learning to Recommend Using Non-Uniform Data
Oct 21, 2021
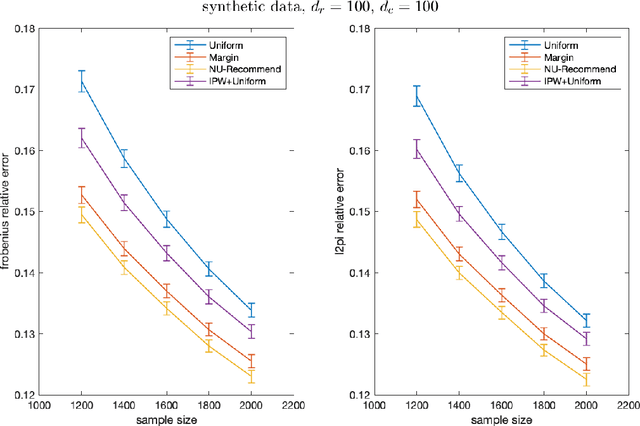
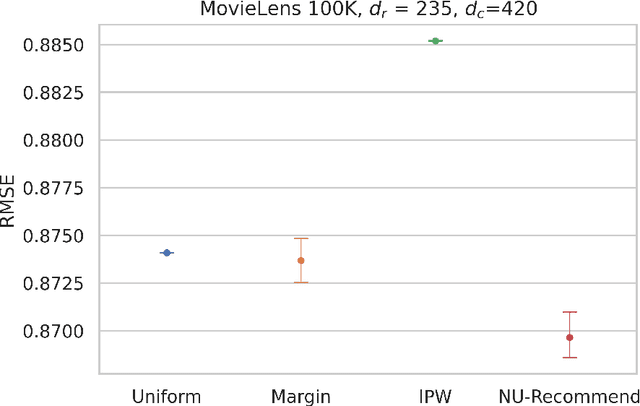
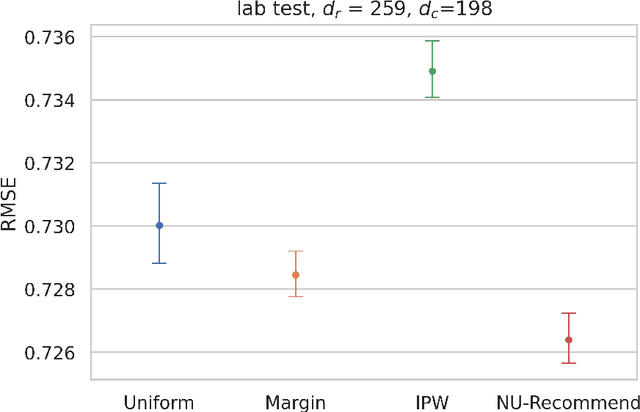
Learning user preferences for products based on their past purchases or reviews is at the cornerstone of modern recommendation engines. One complication in this learning task is that some users are more likely to purchase products or review them, and some products are more likely to be purchased or reviewed by the users. This non-uniform pattern degrades the power of many existing recommendation algorithms, as they assume that the observed data is sampled uniformly at random among user-product pairs. In addition, existing literature on modeling non-uniformity either assume user interests are independent of the products, or lack theoretical understanding. In this paper, we first model the user-product preferences as a partially observed matrix with non-uniform observation pattern. Next, building on the literature about low-rank matrix estimation, we introduce a new weighted trace-norm penalized regression to predict unobserved values of the matrix. We then prove an upper bound for the prediction error of our proposed approach. Our upper bound is a function of a number of parameters that are based on a certain weight matrix that depends on the joint distribution of users and products. Utilizing this observation, we introduce a new optimization problem to select a weight matrix that minimizes the upper bound on the prediction error. The final product is a new estimator, NU-Recommend, that outperforms existing methods in both synthetic and real datasets.
The Randomized Elliptical Potential Lemma with an Application to Linear Thompson Sampling
Feb 16, 2021In this note, we introduce a randomized version of the well-known elliptical potential lemma that is widely used in the analysis of algorithms in sequential learning and decision-making problems such as stochastic linear bandits. Our randomized elliptical potential lemma relaxes the Gaussian assumption on the observation noise and on the prior distribution of the problem parameters. We then use this generalization to prove an improved Bayesian regret bound for Thompson sampling for the linear stochastic bandits with changing action sets where prior and noise distributions are general. This bound is minimax optimal up to constants.
On Worst-case Regret of Linear Thompson Sampling
Jun 11, 2020
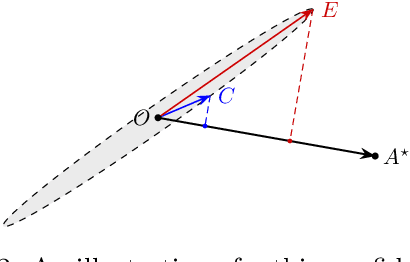
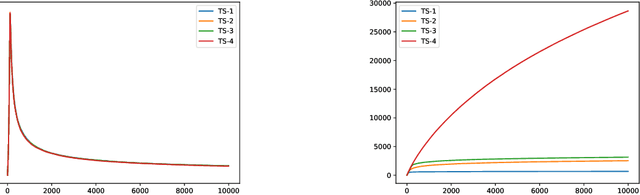
In this paper, we consider the worst-case regret of Linear Thompson Sampling (LinTS) for the linear bandit problem. Russo and Van Roy (2014) show that the Bayesian regret of LinTS is bounded above by $\widetilde{\mathcal{O}}(d\sqrt{T})$ where $T$ is the time horizon and $d$ is the number of parameters. While this bound matches the minimax lower-bounds for this problem up to logarithmic factors, the existence of a similar worst-case regret bound is still unknown. The only known worst-case regret bound for LinTS, due to Agrawal and Goyal (2013b); Abeille et al. (2017), is $\widetilde{\mathcal{O}}(d\sqrt{dT})$ which requires the posterior variance to be inflated by a factor of $\widetilde{\mathcal{O}}(\sqrt{d})$. While this bound is far from the minimax optimal rate by a factor of $\sqrt{d}$, in this paper we show that it is the best possible one can get, settling an open problem stated in Russo et al. (2018). Specifically, we construct examples to show that, without the inflation, LinTS can incur linear regret up to time $\exp(\mathcal{O}(d))$. We then demonstrate that, under mild conditions, a slightly modified version of LinTS requires only an $\widetilde{\mathcal{O}}(1)$ inflation where the constant depends on the diversity of the optimal arm.
Optimal and Greedy Algorithms for Multi-Armed Bandits with Many Arms
Feb 24, 2020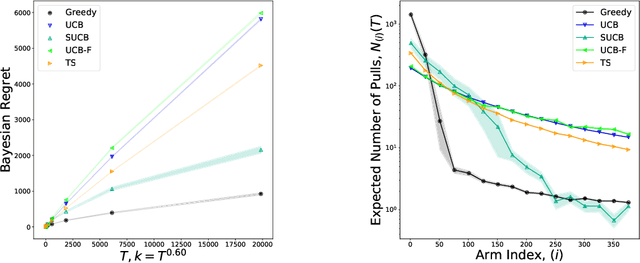
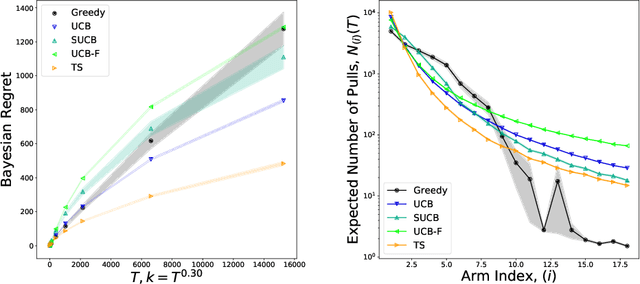
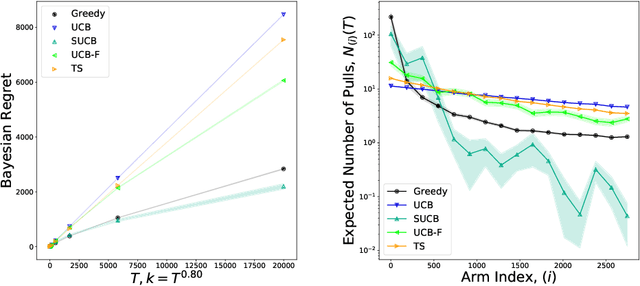
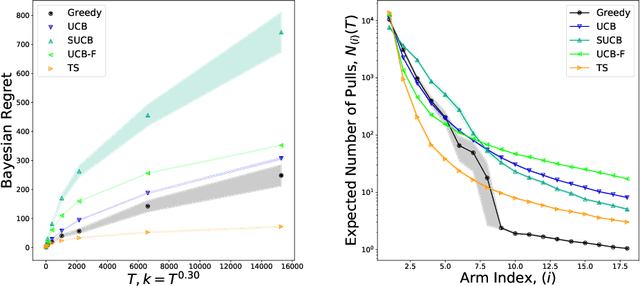
We characterize Bayesian regret in a stochastic multi-armed bandit problem with a large but finite number of arms. In particular, we assume the number of arms $k$ is $T^{\alpha}$, where $T$ is the time-horizon and $\alpha$ is in $(0,1)$. We consider a Bayesian setting where the reward distribution of each arm is drawn independently from a common prior, and provide a complete analysis of expected regret with respect to this prior. Our results exhibit a sharp distinction around $\alpha = 1/2$. When $\alpha < 1/2$, the fundamental lower bound on regret is $\Omega(k)$; and it is achieved by a standard UCB algorithm. When $\alpha > 1/2$, the fundamental lower bound on regret is $\Omega(\sqrt{T})$, and it is achieved by an algorithm that first subsamples $\sqrt{T}$ arms uniformly at random, then runs UCB on just this subset. Interestingly, we also find that a sufficiently large number of arms allows the decision-maker to benefit from "free" exploration if she simply uses a greedy algorithm. In particular, this greedy algorithm exhibits a regret of $\tilde{O}(\max(k,T/\sqrt{k}))$, which translates to a {\em sublinear} (though not optimal) regret in the time horizon. We show empirically that this is because the greedy algorithm rapidly disposes of underperforming arms, a beneficial trait in the many-armed regime. Technically, our analysis of the greedy algorithm involves a novel application of the Lundberg inequality, an upper bound for the ruin probability of a random walk; this approach may be of independent interest.