 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiv: Framework For Measuring Geographical Diversity In Text-To-Image Models
Feb 25, 2026Text-to-image (T2I) models are rapidly gaining popularity, yet their outputs often lack geographical diversity, reinforce stereotypes, and misrepresent regions. Given their broad reach, it is critical to rigorously evaluate how these models portray the world. Existing diversity metrics either rely on curated datasets or focus on surface-level visual similarity, limiting interpretability. We introduce GeoDiv, a framework leveraging large language and vision-language models to assess geographical diversity along two complementary axes: the Socio-Economic Visual Index (SEVI), capturing economic and condition-related cues, and the Visual Diversity Index (VDI), measuring variation in primary entities and backgrounds. Applied to images generated by models such as Stable Diffusion and FLUX.1-dev across $10$ entities and $16$ countries, GeoDiv reveals a consistent lack of diversity and identifies fine-grained attributes where models default to biased portrayals. Strikingly, depictions of countries like India, Nigeria, and Colombia are disproportionately impoverished and worn, reflecting underlying socio-economic biases. These results highlight the need for greater geographical nuance in generative models. GeoDiv provides the first systematic, interpretable framework for measuring such biases, marking a step toward fairer and more inclusive generative systems. Project page: https://abhipsabasu.github.io/geodiv
Learning-Based Practical Light Field Image Compression Using A Disparity-Aware Model
Jun 23, 2021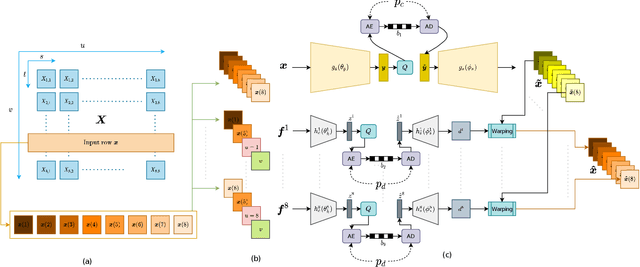
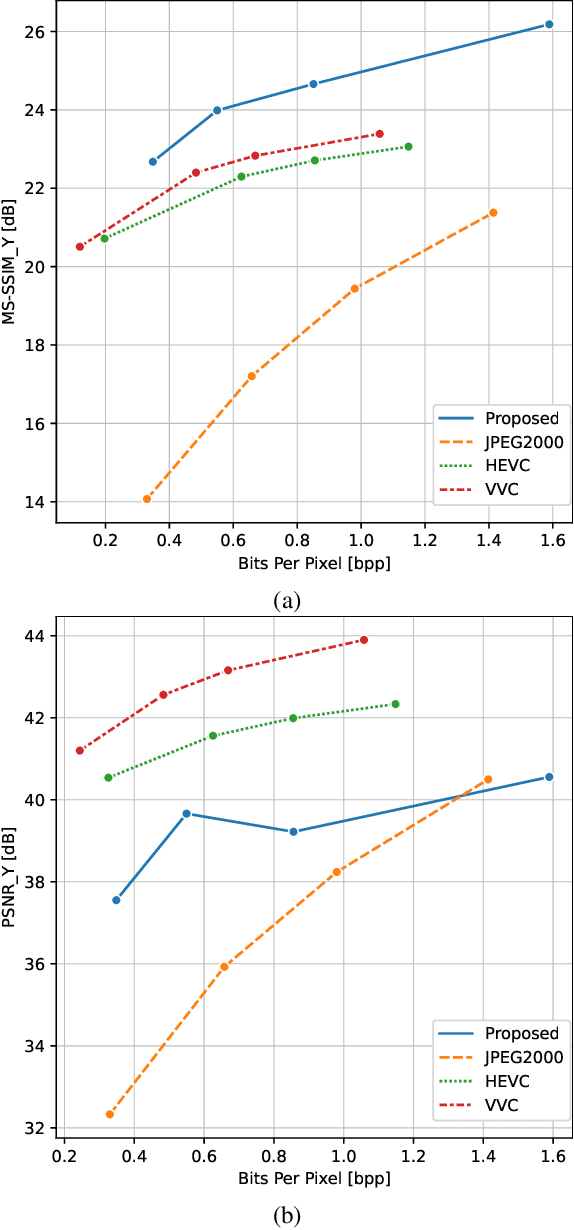

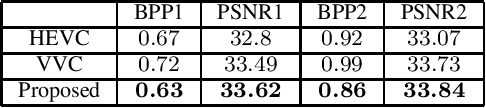
Light field technology has increasingly attracted the attention of the research community with its many possible applications. The lenslet array in commercial plenoptic cameras helps capture both the spatial and angular information of light rays in a single exposure. While the resulting high dimensionality of light field data enables its superior capabilities, it also impedes its extensive adoption. Hence, there is a compelling need for efficient compression of light field images. Existing solutions are commonly composed of several separate modules, some of which may not have been designed for the specific structure and quality of light field data. This increases the complexity of the codec and results in impractical decoding runtimes. We propose a new learning-based, disparity-aided model for compression of 4D light field images capable of parallel decoding. The model is end-to-end trainable, eliminating the need for hand-tuning separate modules and allowing joint learning of rate and distortion. The disparity-aided approach ensures the structural integrity of the reconstructed light fields. Comparisons with the state of the art show encouraging performance in terms of PSNR and MS-SSIM metrics. Also, there is a notable gain in the encoding and decoding runtimes. Source code is available at https://moha23.github.io/LF-DAAE.