 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Chest X-ray Diagnosis Models Across Multinational Datasets
May 21, 2025



Foundation models leveraging vision-language pretraining have shown promise in chest X-ray (CXR) interpretation, yet their real-world performance across diverse populations and diagnostic tasks remains insufficiently evaluated. This study benchmarks the diagnostic performance and generalizability of foundation models versus traditional convolutional neural networks (CNNs) on multinational CXR datasets. We evaluated eight CXR diagnostic models - five vision-language foundation models and three CNN-based architectures - across 37 standardized classification tasks using six public datasets from the USA, Spain, India, and Vietnam, and three private datasets from hospitals in China. Performance was assessed using AUROC, AUPRC, and other metrics across both shared and dataset-specific tasks. Foundation models outperformed CNNs in both accuracy and task coverage. MAVL, a model incorporating knowledge-enhanced prompts and structured supervision, achieved the highest performance on public (mean AUROC: 0.82; AUPRC: 0.32) and private (mean AUROC: 0.95; AUPRC: 0.89) datasets, ranking first in 14 of 37 public and 3 of 4 private tasks. All models showed reduced performance on pediatric cases, with average AUROC dropping from 0.88 +/- 0.18 in adults to 0.57 +/- 0.29 in children (p = 0.0202). These findings highlight the value of structured supervision and prompt design in radiologic AI and suggest future directions including geographic expansion and ensemble modeling for clinical deployment. Code for all evaluated models is available at https://drive.google.com/drive/folders/1B99yMQm7bB4h1sVMIBja0RfUu8gLktCE
HyMNet: a Multimodal Deep Learning System for Hypertension Classification using Fundus Photographs and Cardiometabolic Risk Factors
Oct 02, 2023In recent years, deep learning has shown promise in predicting hypertension (HTN) from fundus images. However, most prior research has primarily focused on analyzing a single type of data, which may not capture the full complexity of HTN risk. To address this limitation, this study introduces a multimodal deep learning (MMDL) system, dubbed HyMNet, which combines fundus images and cardiometabolic risk factors, specifically age and gender, to improve hypertension detection capabilities. Our MMDL system uses the DenseNet-201 architecture, pre-trained on ImageNet, for the fundus imaging path and a fully connected neural network for the age and gender path. The two paths are jointly trained by concatenating 64 features output from each path that are then fed into a fusion network. The system was trained on 1,143 retinal images from 626 individuals collected from the Saudi Ministry of National Guard Health Affairs. The results show that the multimodal model that integrates fundus images along with age and gender achieved an AUC of 0.791 [CI: 0.735, 0.848], which outperforms the unimodal model trained solely on fundus photographs that yielded an AUC of 0.766 [CI: 0.705, 0.828] for hypertension detection.
Integration of Domain Knowledge using Medical Knowledge Graph Deep Learning for Cancer Phenotyping
Jan 05, 2021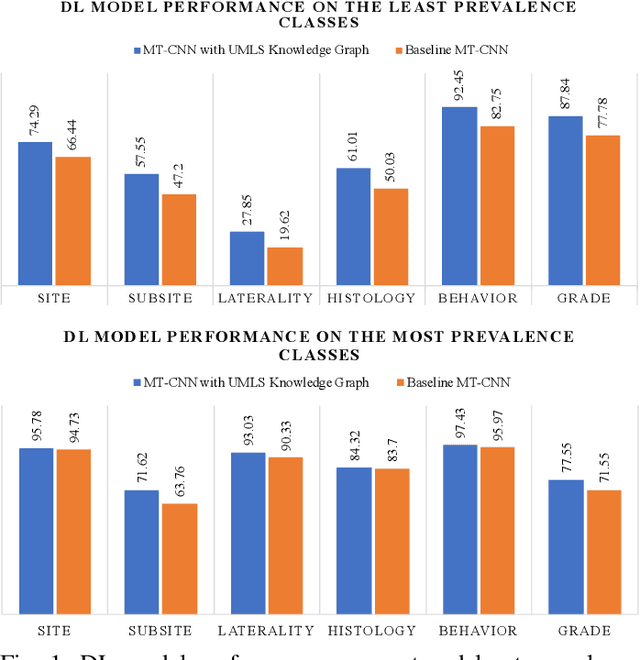
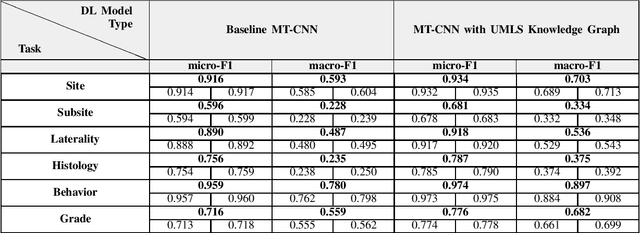
A key component of deep learning (DL) for natural language processing (NLP) is word embeddings. Word embeddings that effectively capture the meaning and context of the word that they represent can significantly improve the performance of downstream DL models for various NLP tasks. Many existing word embeddings techniques capture the context of words based on word co-occurrence in documents and text; however, they often cannot capture broader domain-specific relationships between concepts that may be crucial for the NLP task at hand. In this paper, we propose a method to integrate external knowledge from medical terminology ontologies into the context captured by word embeddings. Specifically, we use a medical knowledge graph, such as the unified medical language system (UMLS), to find connections between clinical terms in cancer pathology reports. This approach aims to minimize the distance between connected clinical concepts. We evaluate the proposed approach using a Multitask Convolutional Neural Network (MT-CNN) to extract six cancer characteristics -- site, subsite, laterality, behavior, histology, and grade -- from a dataset of ~900K cancer pathology reports. The results show that the MT-CNN model which uses our domain informed embeddings outperforms the same MT-CNN using standard word2vec embeddings across all tasks, with an improvement in the overall micro- and macro-F1 scores by 4.97\%and 22.5\%, respectively.