 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVID-Net Biochem: An Explainability-driven Framework to Building Machine Learning Models for Predicting Survival and Kidney Injury of COVID-19 Patients from Clinical and Biochemistry Data
Apr 24, 2022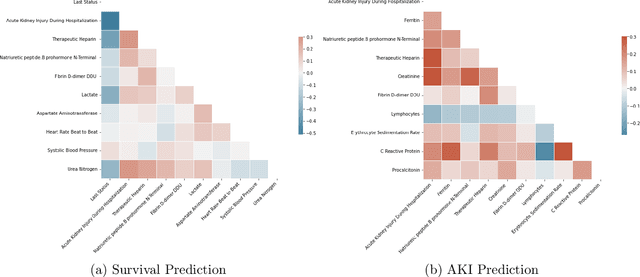
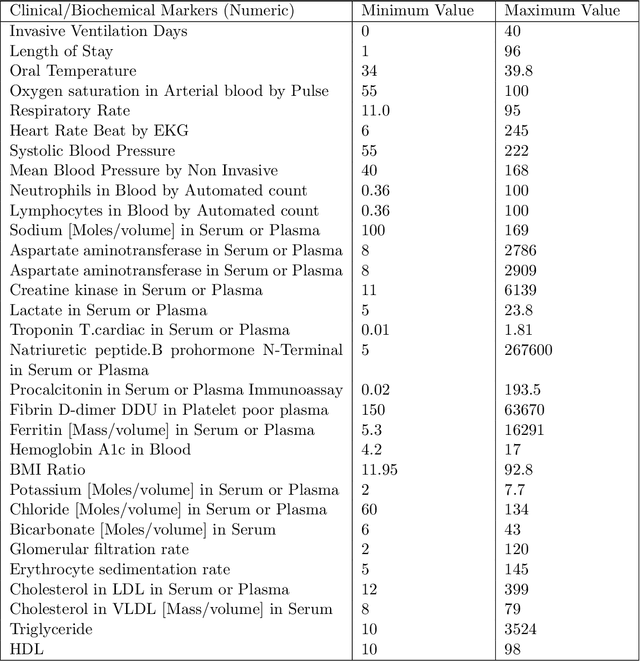
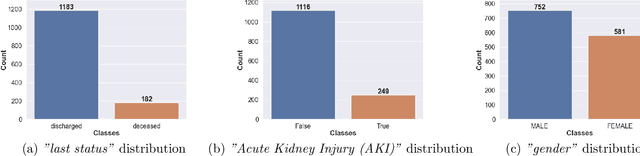
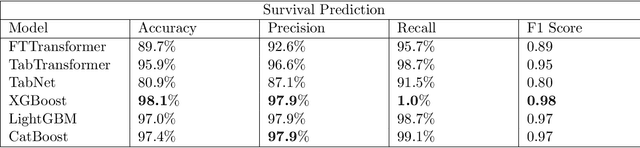
Ever since the declaration of COVID-19 as a pandemic by the World Health Organization in 2020, the world has continued to struggle in controlling and containing the spread of the COVID-19 pandemic caused by the SARS-CoV-2 virus. This has been especially challenging with the rise of the Omicron variant and its subvariants and recombinants, which has led to a significant increase in patients seeking treatment and has put a tremendous burden on hospitals and healthcare systems. A major challenge faced during the pandemic has been the prediction of survival and the risk for additional injuries in individual patients, which requires significant clinical expertise and additional resources to avoid further complications. In this study we propose COVID-Net Biochem, an explainability-driven framework for building machine learning models to predict patient survival and the chance of developing kidney injury during hospitalization from clinical and biochemistry data in a transparent and systematic manner. In the first "clinician-guided initial design" phase, we prepared a benchmark dataset of carefully selected clinical and biochemistry data based on clinician assessment, which were curated from a patient cohort of 1366 patients at Stony Brook University. A collection of different machine learning models with a diversity of gradient based boosting tree architectures and deep transformer architectures was designed and trained specifically for survival and kidney injury prediction based on the carefully selected clinical and biochemical markers.
MAPLE: Microprocessor A Priori for Latency Estimation
Nov 30, 2021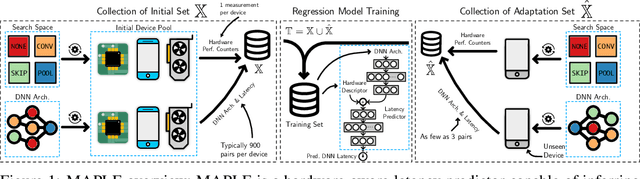

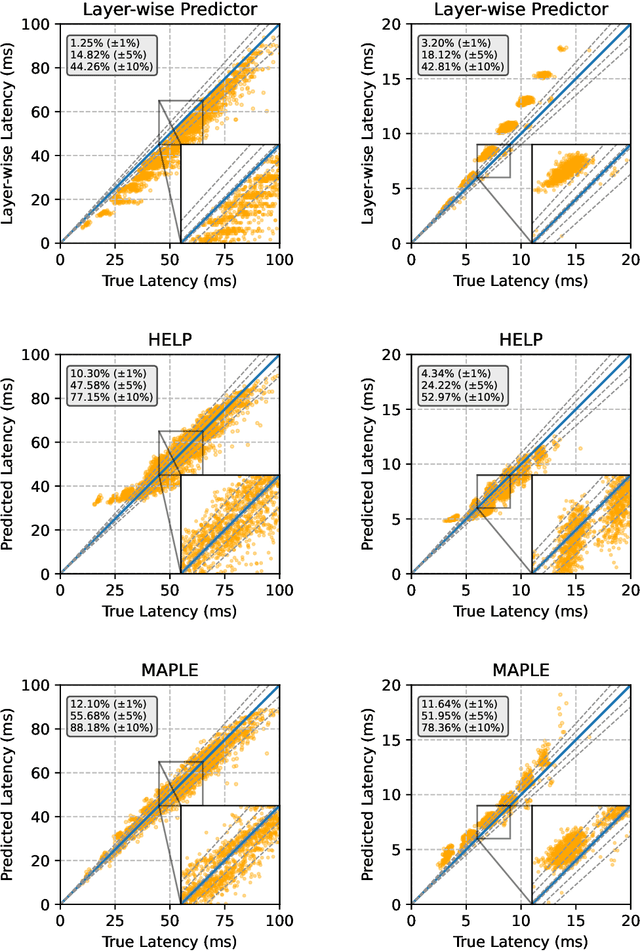
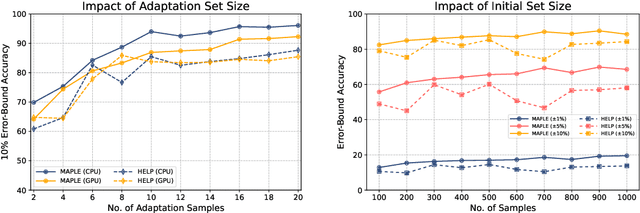
Modern deep neural networks must demonstrate state-of-the-art accuracy while exhibiting low latency and energy consumption. As such, neural architecture search (NAS) algorithms take these two constraints into account when generating a new architecture. However, efficiency metrics such as latency are typically hardware dependent requiring the NAS algorithm to either measure or predict the architecture latency. Measuring the latency of every evaluated architecture adds a significant amount of time to the NAS process. Here we propose Microprocessor A Priori for Latency Estimation MAPLE that does not rely on transfer learning or domain adaptation but instead generalizes to new hardware by incorporating a prior hardware characteristics during training. MAPLE takes advantage of a novel quantitative strategy to characterize the underlying microprocessor by measuring relevant hardware performance metrics, yielding a fine-grained and expressive hardware descriptor. Moreover, the proposed MAPLE benefits from the tightly coupled I/O between the CPU and GPU and their dependency to predict DNN latency on GPUs while measuring microprocessor performance hardware counters from the CPU feeding the GPU hardware. Through this quantitative strategy as the hardware descriptor, MAPLE can generalize to new hardware via a few shot adaptation strategy where with as few as 3 samples it exhibits a 3% improvement over state-of-the-art methods requiring as much as 10 samples. Experimental results showed that, increasing the few shot adaptation samples to 10 improves the accuracy significantly over the state-of-the-art methods by 12%. Furthermore, it was demonstrated that MAPLE exhibiting 8-10% better accuracy, on average, compared to relevant baselines at any number of adaptation samples.
TinyDefectNet: Highly Compact Deep Neural Network Architecture for High-Throughput Manufacturing Visual Quality Inspection
Nov 29, 2021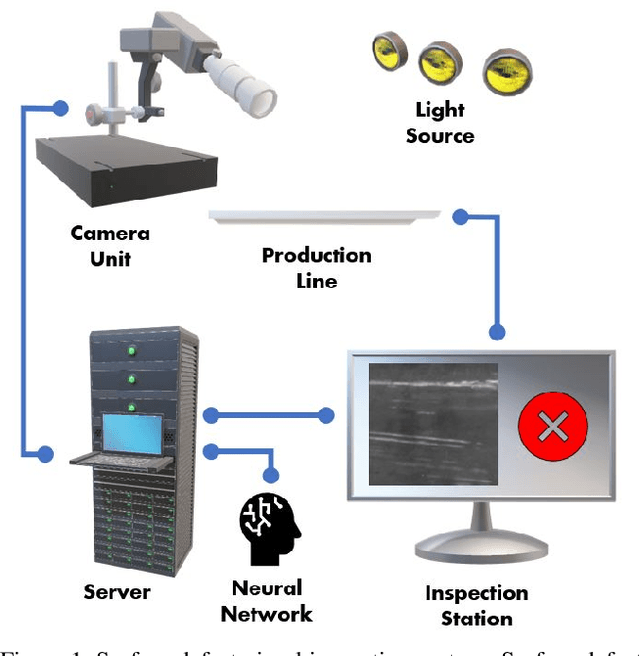
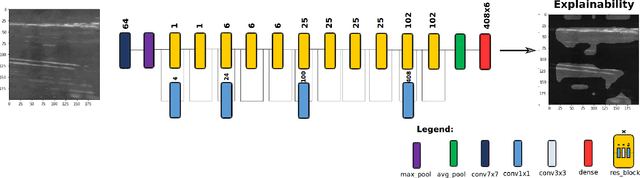

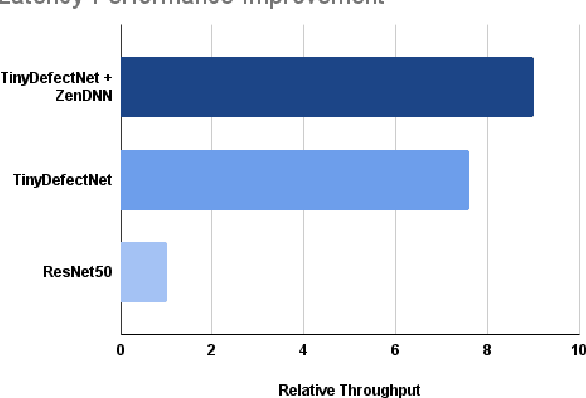
A critical aspect in the manufacturing process is the visual quality inspection of manufactured components for defects and flaws. Human-only visual inspection can be very time-consuming and laborious, and is a significant bottleneck especially for high-throughput manufacturing scenarios. Given significant advances in the field of deep learning, automated visual quality inspection can lead to highly efficient and reliable detection of defects and flaws during the manufacturing process. However, deep learning-driven visual inspection methods often necessitate significant computational resources, thus limiting throughput and act as a bottleneck to widespread adoption for enabling smart factories. In this study, we investigated the utilization of a machine-driven design exploration approach to create TinyDefectNet, a highly compact deep convolutional network architecture tailored for high-throughput manufacturing visual quality inspection. TinyDefectNet comprises of just ~427K parameters and has a computational complexity of ~97M FLOPs, yet achieving a detection accuracy of a state-of-the-art architecture for the task of surface defect detection on the NEU defect benchmark dataset. As such, TinyDefectNet can achieve the same level of detection performance at 52$\times$ lower architectural complexity and 11x lower computational complexity. Furthermore, TinyDefectNet was deployed on an AMD EPYC 7R32, and achieved 7.6x faster throughput using the native Tensorflow environment and 9x faster throughput using AMD ZenDNN accelerator library. Finally, explainability-driven performance validation strategy was conducted to ensure correct decision-making behaviour was exhibited by TinyDefectNet to improve trust in its usage by operators and inspectors.
MEDUSA: Multi-scale Encoder-Decoder Self-Attention Deep Neural Network Architecture for Medical Image Analysis
Oct 12, 2021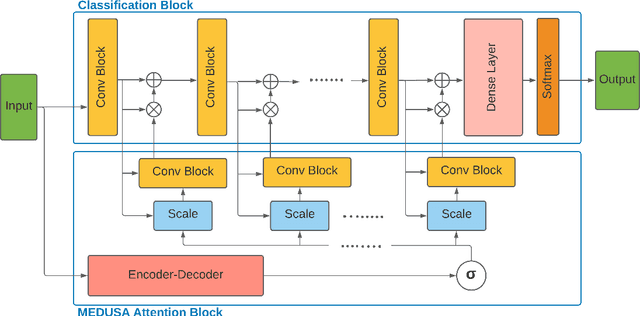
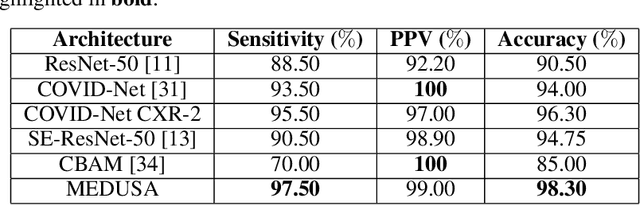
Medical image analysis continues to hold interesting challenges given the subtle characteristics of certain diseases and the significant overlap in appearance between diseases. In this work, we explore the concept of self-attention for tackling such subtleties in and between diseases. To this end, we introduce MEDUSA, a multi-scale encoder-decoder self-attention mechanism tailored for medical image analysis. While self-attention deep convolutional neural network architectures in existing literature center around the notion of multiple isolated lightweight attention mechanisms with limited individual capacities being incorporated at different points in the network architecture, MEDUSA takes a significant departure from this notion by possessing a single, unified self-attention mechanism with significantly higher capacity with multiple attention heads feeding into different scales in the network architecture. To the best of the authors' knowledge, this is the first "single body, multi-scale heads" realization of self-attention and enables explicit global context amongst selective attention at different levels of representational abstractions while still enabling differing local attention context at individual levels of abstractions. With MEDUSA, we obtain state-of-the-art performance on multiple challenging medical image analysis benchmarks including COVIDx, RSNA RICORD, and RSNA Pneumonia Challenge when compared to previous work. Our MEDUSA model is publicly available.
Does Form Follow Function? An Empirical Exploration of the Impact of Deep Neural Network Architecture Design on Hardware-Specific Acceleration
Jul 08, 2021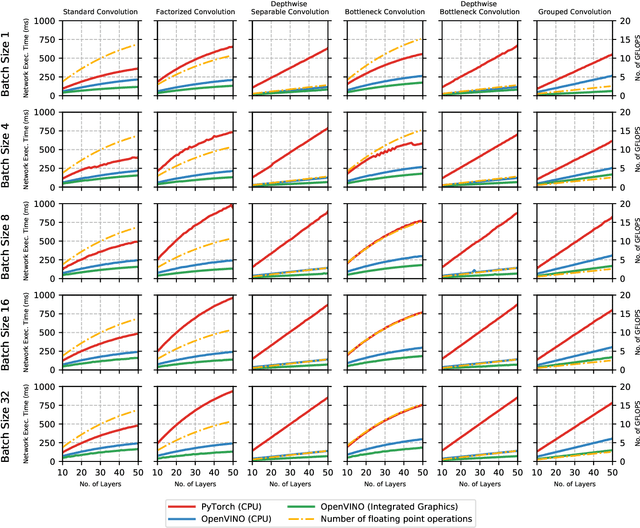
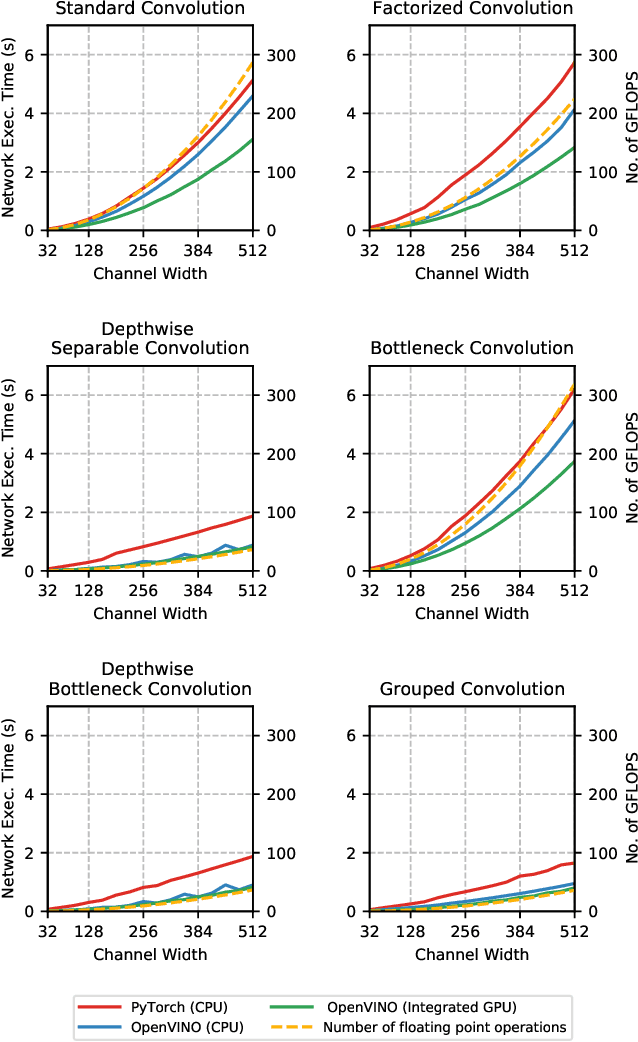
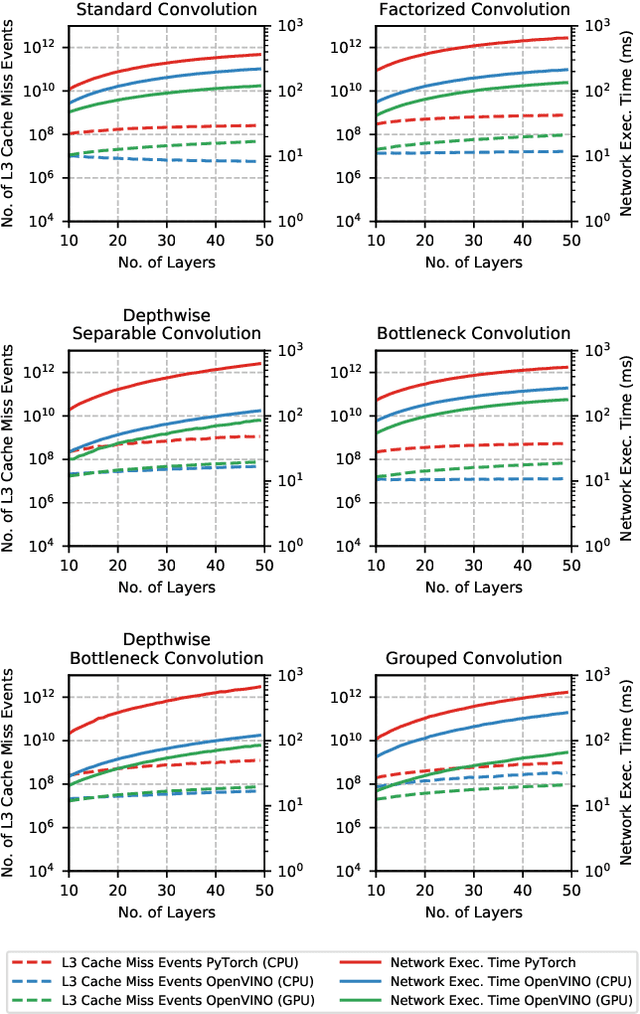
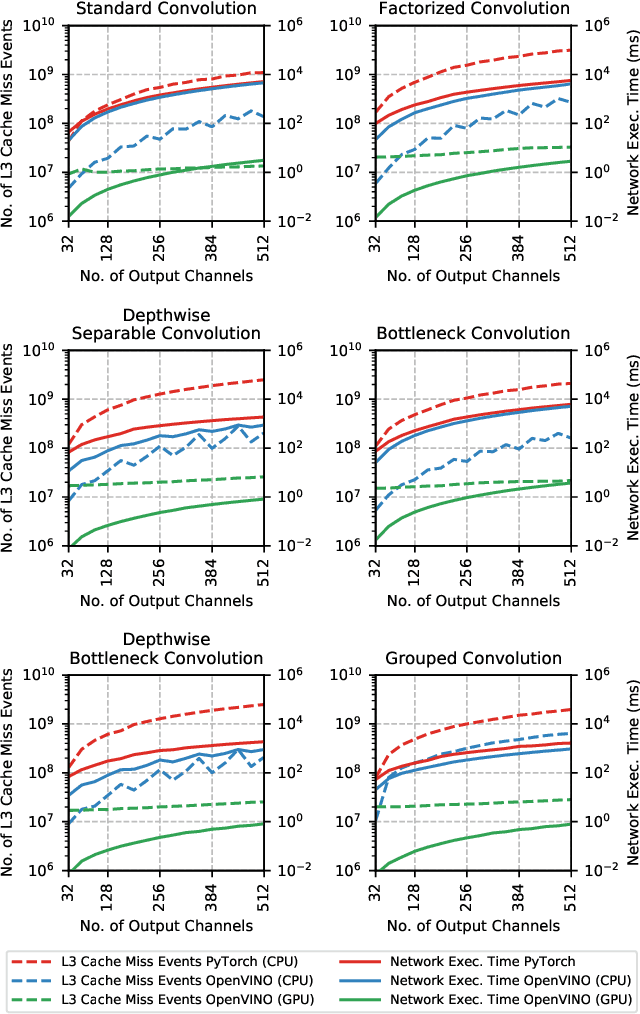
The fine-grained relationship between form and function with respect to deep neural network architecture design and hardware-specific acceleration is one area that is not well studied in the research literature, with form often dictated by accuracy as opposed to hardware function. In this study, a comprehensive empirical exploration is conducted to investigate the impact of deep neural network architecture design on the degree of inference speedup that can be achieved via hardware-specific acceleration. More specifically, we empirically study the impact of a variety of commonly used macro-architecture design patterns across different architectural depths through the lens of OpenVINO microprocessor-specific and GPU-specific acceleration. Experimental results showed that while leveraging hardware-specific acceleration achieved an average inference speed-up of 380%, the degree of inference speed-up varied drastically depending on the macro-architecture design pattern, with the greatest speedup achieved on the depthwise bottleneck convolution design pattern at 550%. Furthermore, we conduct an in-depth exploration of the correlation between FLOPs requirement, level 3 cache efficacy, and network latency with increasing architectural depth and width. Finally, we analyze the inference time reductions using hardware-specific acceleration when compared to native deep learning frameworks across a wide variety of hand-crafted deep convolutional neural network architecture designs as well as ones found via neural architecture search strategies. We found that the DARTS-derived architecture to benefit from the greatest improvement from hardware-specific software acceleration (1200%) while the depthwise bottleneck convolution-based MobileNet-V2 to have the lowest overall inference time of around 2.4 ms.
Residual Error: a New Performance Measure for Adversarial Robustness
Jun 18, 2021
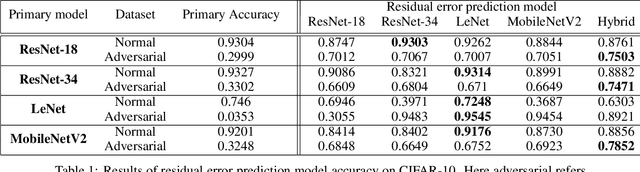
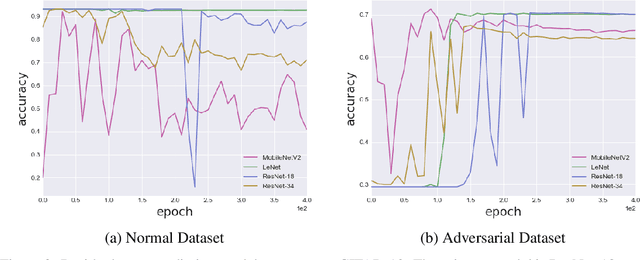
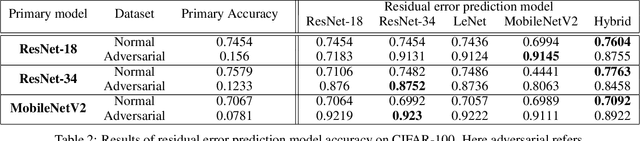
Despite the significant advances in deep learning over the past decade, a major challenge that limits the wide-spread adoption of deep learning has been their fragility to adversarial attacks. This sensitivity to making erroneous predictions in the presence of adversarially perturbed data makes deep neural networks difficult to adopt for certain real-world, mission-critical applications. While much of the research focus has revolved around adversarial example creation and adversarial hardening, the area of performance measures for assessing adversarial robustness is not well explored. Motivated by this, this study presents the concept of residual error, a new performance measure for not only assessing the adversarial robustness of a deep neural network at the individual sample level, but also can be used to differentiate between adversarial and non-adversarial examples to facilitate for adversarial example detection. Furthermore, we introduce a hybrid model for approximating the residual error in a tractable manner. Experimental results using the case of image classification demonstrates the effectiveness and efficacy of the proposed residual error metric for assessing several well-known deep neural network architectures. These results thus illustrate that the proposed measure could be a useful tool for not only assessing the robustness of deep neural networks used in mission-critical scenarios, but also in the design of adversarially robust models.
COVID-Net CT-S: 3D Convolutional Neural Network Architectures for COVID-19 Severity Assessment using Chest CT Images
May 04, 2021

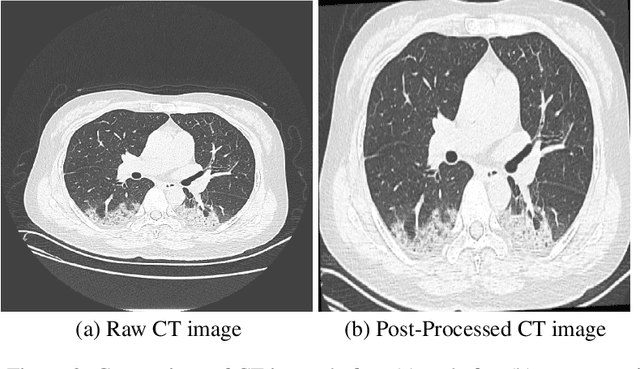
The health and socioeconomic difficulties caused by the COVID-19 pandemic continues to cause enormous tensions around the world. In particular, this extraordinary surge in the number of cases has put considerable strain on health care systems around the world. A critical step in the treatment and management of COVID-19 positive patients is severity assessment, which is challenging even for expert radiologists given the subtleties at different stages of lung disease severity. Motivated by this challenge, we introduce COVID-Net CT-S, a suite of deep convolutional neural networks for predicting lung disease severity due to COVID-19 infection. More specifically, a 3D residual architecture design is leveraged to learn volumetric visual indicators characterizing the degree of COVID-19 lung disease severity. Experimental results using the patient cohort collected by the China National Center for Bioinformation (CNCB) showed that the proposed COVID-Net CT-S networks, by leveraging volumetric features, can achieve significantly improved severity assessment performance when compared to traditional severity assessment networks that learn and leverage 2D visual features to characterize COVID-19 severity.
COVID-Net CXR-S: Deep Convolutional Neural Network for Severity Assessment of COVID-19 Cases from Chest X-ray Images
May 01, 2021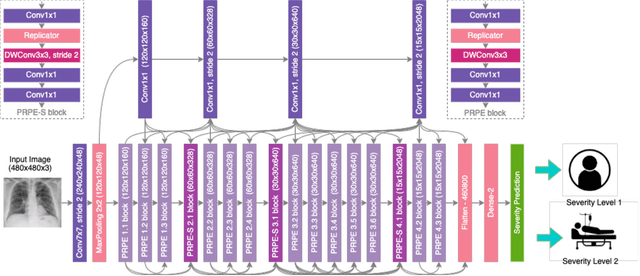
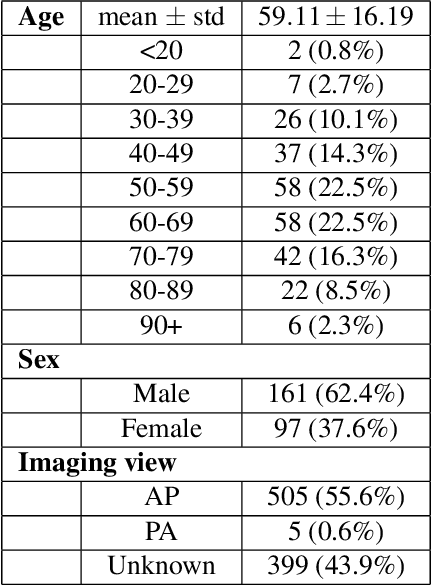
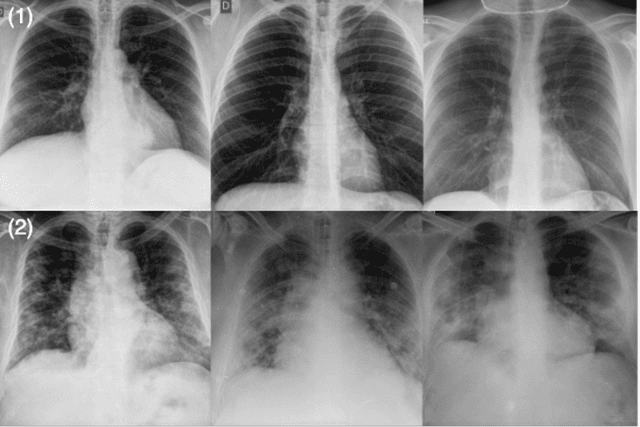
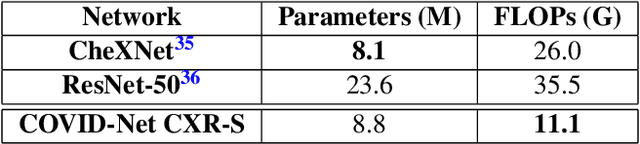
The world is still struggling in controlling and containing the spread of the COVID-19 pandemic caused by the SARS-CoV-2 virus. The medical conditions associated with SARS-CoV-2 infections have resulted in a surge in the number of patients at clinics and hospitals, leading to a significantly increased strain on healthcare resources. As such, an important part of managing and handling patients with SARS-CoV-2 infections within the clinical workflow is severity assessment, which is often conducted with the use of chest x-ray (CXR) images. In this work, we introduce COVID-Net CXR-S, a convolutional neural network for predicting the airspace severity of a SARS-CoV-2 positive patient based on a CXR image of the patient's chest. More specifically, we leveraged transfer learning to transfer representational knowledge gained from over 16,000 CXR images from a multinational cohort of over 15,000 patient cases into a custom network architecture for severity assessment. Experimental results with a multi-national patient cohort curated by the Radiological Society of North America (RSNA) RICORD initiative showed that the proposed COVID-Net CXR-S has potential to be a powerful tool for computer-aided severity assessment of CXR images of COVID-19 positive patients. Furthermore, radiologist validation on select cases by two board-certified radiologists with over 10 and 19 years of experience, respectively, showed consistency between radiologist interpretation and critical factors leveraged by COVID-Net CXR-S for severity assessment. While not a production-ready solution, the ultimate goal for the open source release of COVID-Net CXR-S is to act as a catalyst for clinical scientists, machine learning researchers, as well as citizen scientists to develop innovative new clinical decision support solutions for helping clinicians around the world manage the continuing pandemic.
OutlierNets: Highly Compact Deep Autoencoder Network Architectures for On-Device Acoustic Anomaly Detection
Apr 19, 2021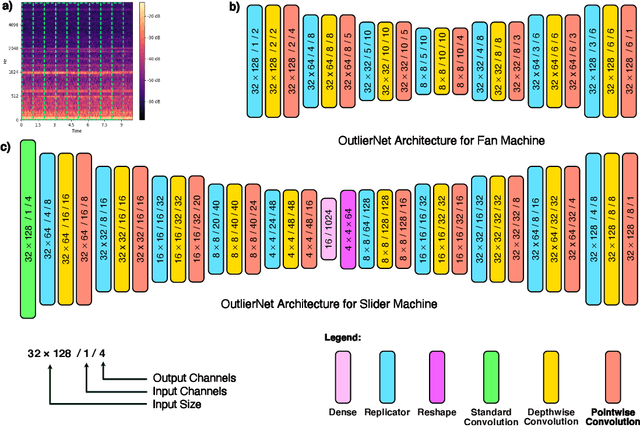
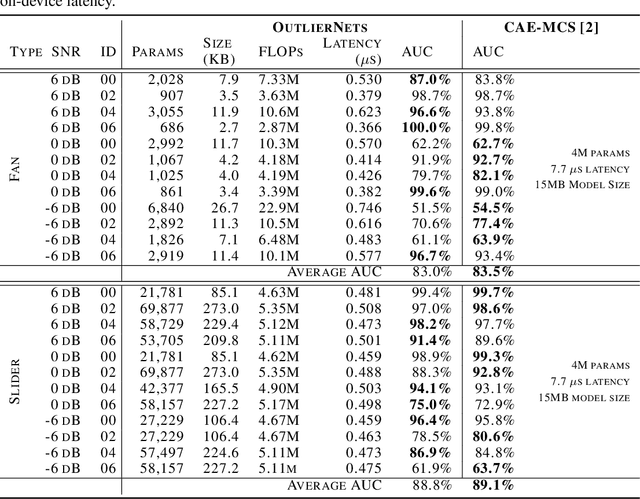
Human operators often diagnose industrial machinery via anomalous sounds. Automated acoustic anomaly detection can lead to reliable maintenance of machinery. However, deep learning-driven anomaly detection methods often require an extensive amount of computational resources which prohibits their deployment in factories. Here we explore a machine-driven design exploration strategy to create OutlierNets, a family of highly compact deep convolutional autoencoder network architectures featuring as few as 686 parameters, model sizes as small as 2.7 KB, and as low as 2.8 million FLOPs, with a detection accuracy matching or exceeding published architectures with as many as 4 million parameters. Furthermore, CPU-accelerated latency experiments show that the OutlierNet architectures can achieve as much as 21x lower latency than published networks.
A Simple Fine-tuning Is All You Need: Towards Robust Deep Learning Via Adversarial Fine-tuning
Dec 25, 2020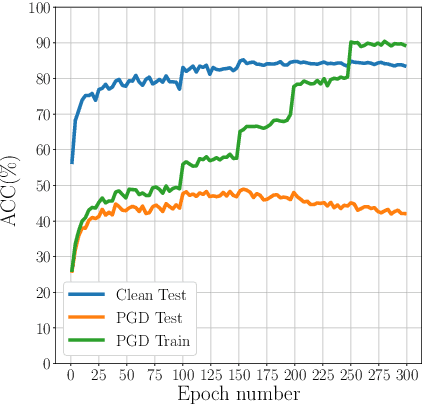
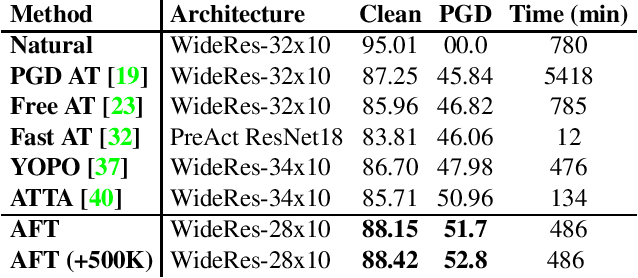
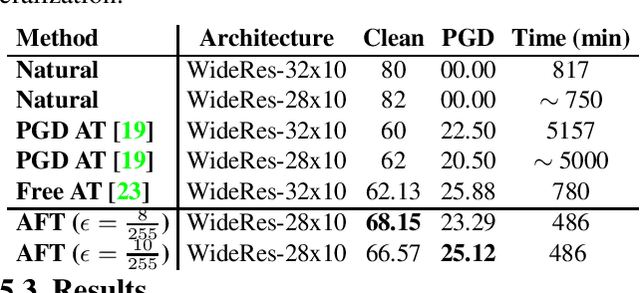
Adversarial Training (AT) with Projected Gradient Descent (PGD) is an effective approach for improving the robustness of the deep neural networks. However, PGD AT has been shown to suffer from two main limitations: i) high computational cost, and ii) extreme overfitting during training that leads to reduction in model generalization. While the effect of factors such as model capacity and scale of training data on adversarial robustness have been extensively studied, little attention has been paid to the effect of a very important parameter in every network optimization on adversarial robustness: the learning rate. In particular, we hypothesize that effective learning rate scheduling during adversarial training can significantly reduce the overfitting issue, to a degree where one does not even need to adversarially train a model from scratch but can instead simply adversarially fine-tune a pre-trained model. Motivated by this hypothesis, we propose a simple yet very effective adversarial fine-tuning approach based on a $\textit{slow start, fast decay}$ learning rate scheduling strategy which not only significantly decreases computational cost required, but also greatly improves the accuracy and robustness of a deep neural network. Experimental results show that the proposed adversarial fine-tuning approach outperforms the state-of-the-art methods on CIFAR-10, CIFAR-100 and ImageNet datasets in both test accuracy and the robustness, while reducing the computational cost by 8-10$\times$. Furthermore, a very important benefit of the proposed adversarial fine-tuning approach is that it enables the ability to improve the robustness of any pre-trained deep neural network without needing to train the model from scratch, which to the best of the authors' knowledge has not been previously demonstrated in research literature.