 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Form Follow Function? An Empirical Exploration of the Impact of Deep Neural Network Architecture Design on Hardware-Specific Acceleration
Paper and Code
Jul 08, 2021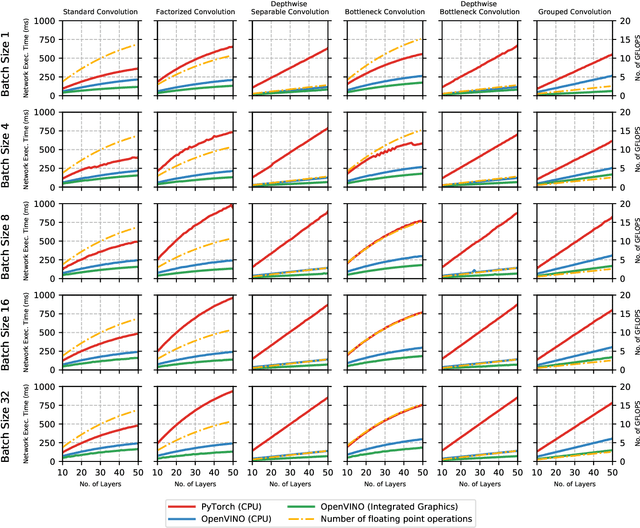
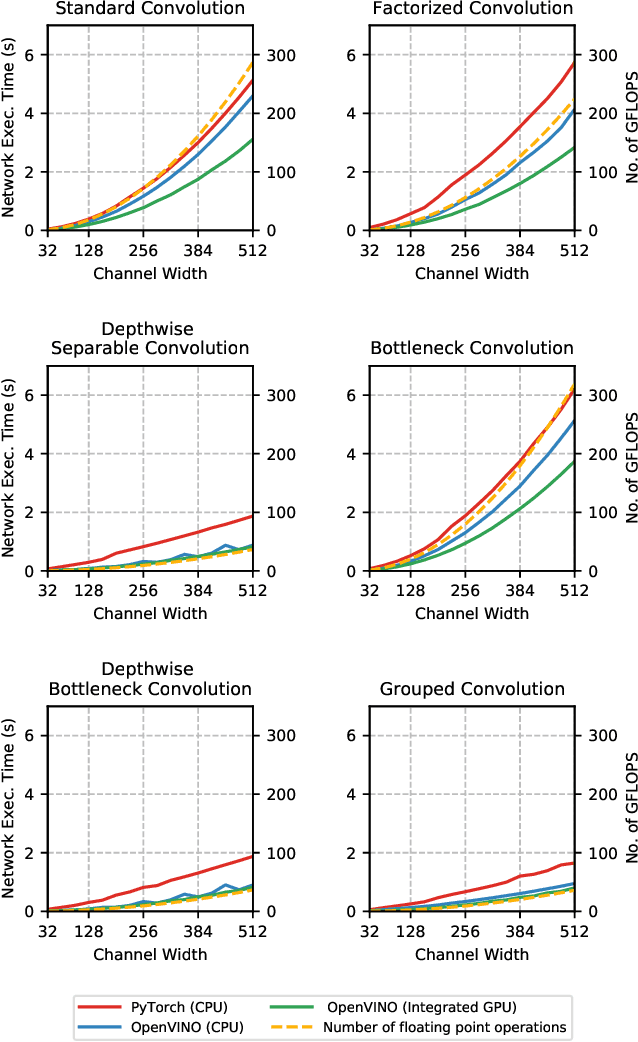
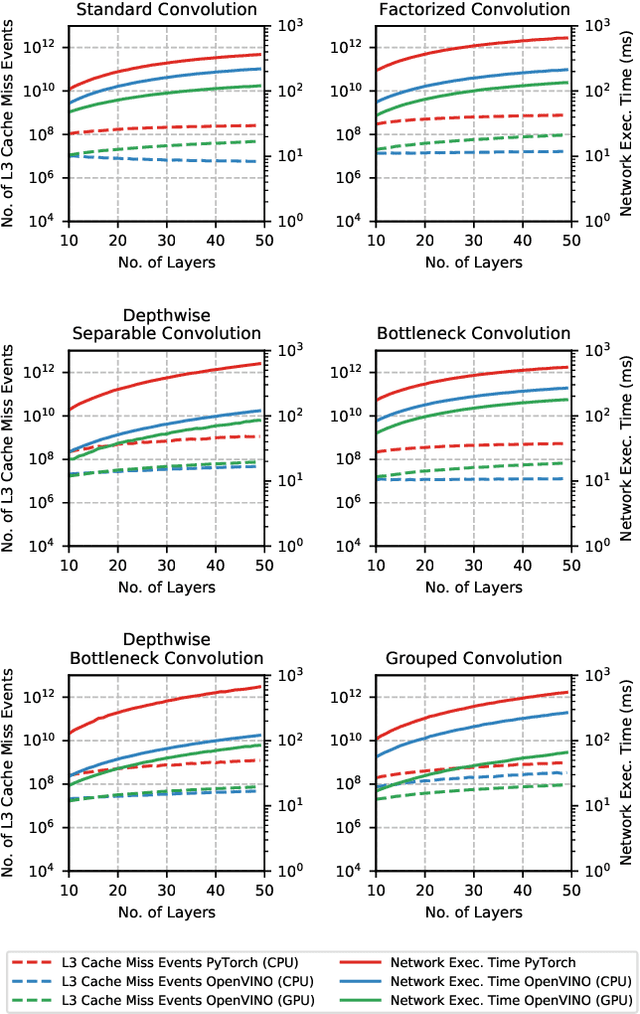
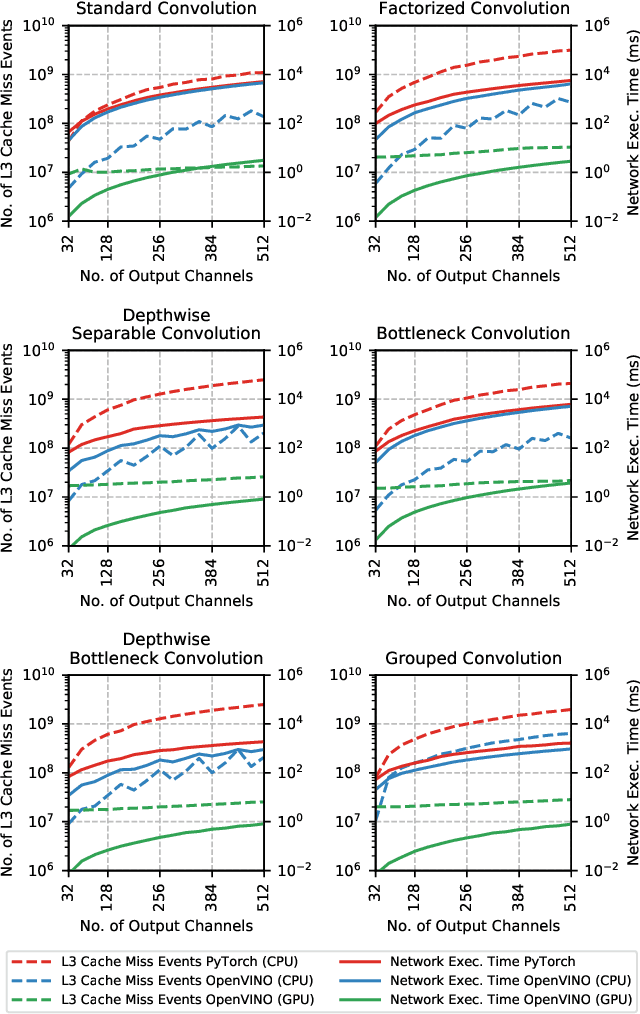
The fine-grained relationship between form and function with respect to deep neural network architecture design and hardware-specific acceleration is one area that is not well studied in the research literature, with form often dictated by accuracy as opposed to hardware function. In this study, a comprehensive empirical exploration is conducted to investigate the impact of deep neural network architecture design on the degree of inference speedup that can be achieved via hardware-specific acceleration. More specifically, we empirically study the impact of a variety of commonly used macro-architecture design patterns across different architectural depths through the lens of OpenVINO microprocessor-specific and GPU-specific acceleration. Experimental results showed that while leveraging hardware-specific acceleration achieved an average inference speed-up of 380%, the degree of inference speed-up varied drastically depending on the macro-architecture design pattern, with the greatest speedup achieved on the depthwise bottleneck convolution design pattern at 550%. Furthermore, we conduct an in-depth exploration of the correlation between FLOPs requirement, level 3 cache efficacy, and network latency with increasing architectural depth and width. Finally, we analyze the inference time reductions using hardware-specific acceleration when compared to native deep learning frameworks across a wide variety of hand-crafted deep convolutional neural network architecture designs as well as ones found via neural architecture search strategies. We found that the DARTS-derived architecture to benefit from the greatest improvement from hardware-specific software acceleration (1200%) while the depthwise bottleneck convolution-based MobileNet-V2 to have the lowest overall inference time of around 2.4 ms.