 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Domain-Invariant Adversarial Network for Deep Domain Generalization
Aug 20, 2021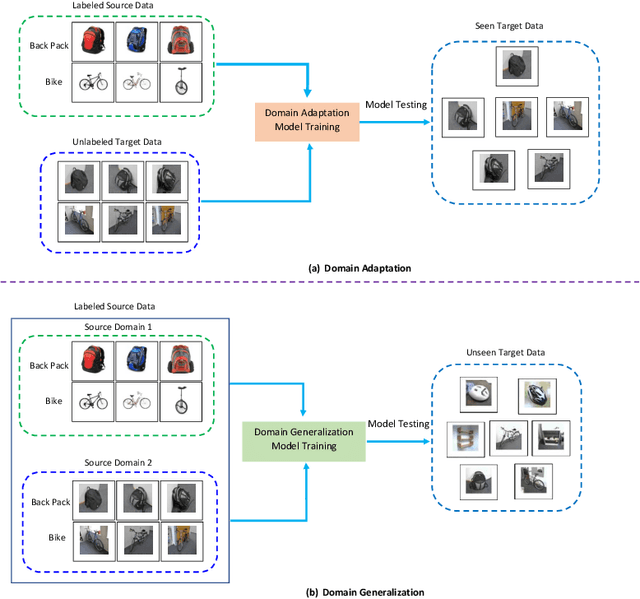
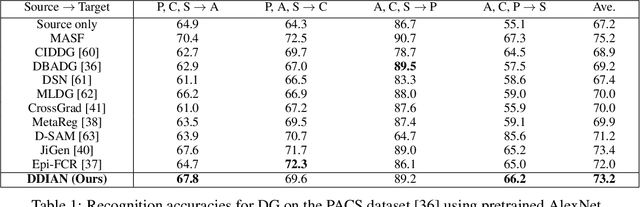
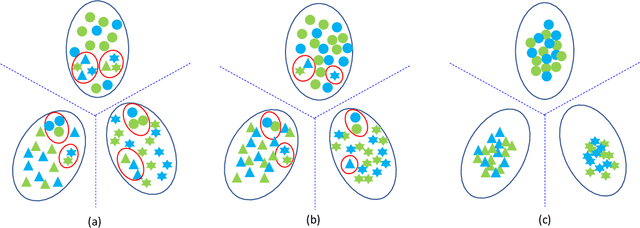
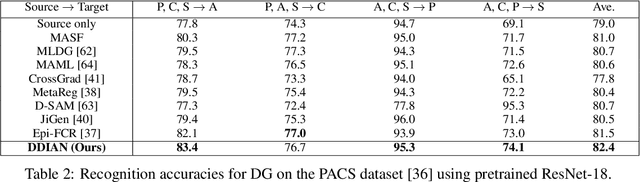
Domain generalization approaches aim to learn a domain invariant prediction model for unknown target domains from multiple training source domains with different distributions. Significant efforts have recently been committed to broad domain generalization, which is a challenging and topical problem in machine learning and computer vision communities. Most previous domain generalization approaches assume that the conditional distribution across the domains remain the same across the source domains and learn a domain invariant model by minimizing the marginal distributions. However, the assumption of a stable conditional distribution of the training source domains does not really hold in practice. The hyperplane learned from the source domains will easily misclassify samples scattered at the boundary of clusters or far from their corresponding class centres. To address the above two drawbacks, we propose a discriminative domain-invariant adversarial network (DDIAN) for domain generalization. The discriminativeness of the features are guaranteed through a discriminative feature module and domain-invariant features are guaranteed through the global domain and local sub-domain alignment modules. Extensive experiments on several benchmarks show that DDIAN achieves better prediction on unseen target data during training compared to state-of-the-art domain generalization approaches.
Preserving Semantic Consistency in Unsupervised Domain Adaptation Using Generative Adversarial Networks
Apr 28, 2021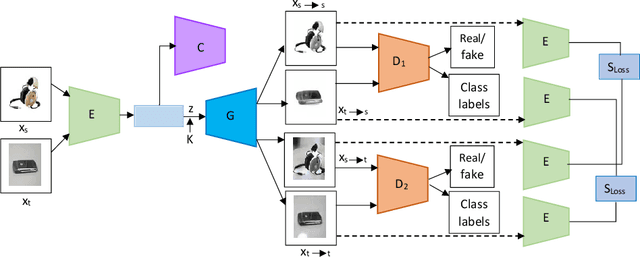
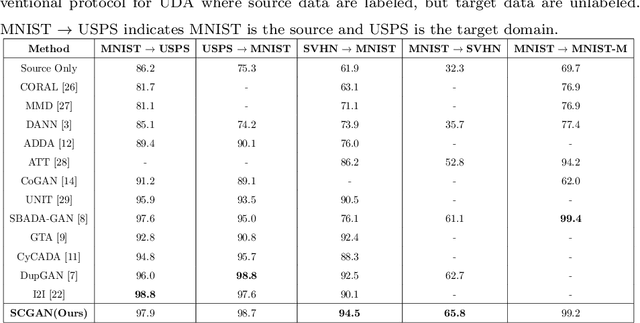

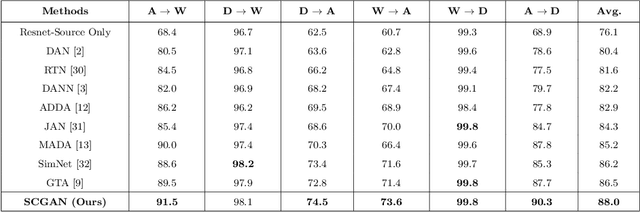
Unsupervised domain adaptation seeks to mitigate the distribution discrepancy between source and target domains, given labeled samples of the source domain and unlabeled samples of the target domain. Generative adversarial networks (GANs) have demonstrated significant improvement in domain adaptation by producing images which are domain specific for training. However, most of the existing GAN based techniques for unsupervised domain adaptation do not consider semantic information during domain matching, hence these methods degrade the performance when the source and target domain data are semantically different. In this paper, we propose an end-to-end novel semantic consistent generative adversarial network (SCGAN). This network can achieve source to target domain matching by capturing semantic information at the feature level and producing images for unsupervised domain adaptation from both the source and the target domains. We demonstrate the robustness of our proposed method which exceeds the state-of-the-art performance in unsupervised domain adaptation settings by performing experiments on digit and object classification tasks.
Deep Domain Generalization with Feature-norm Network
Apr 28, 2021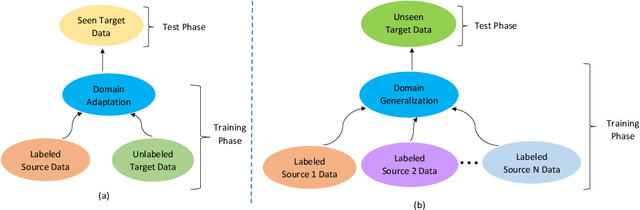
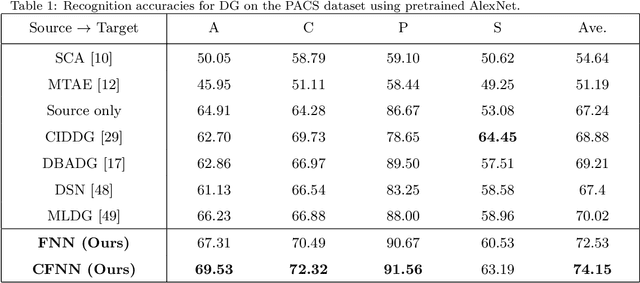

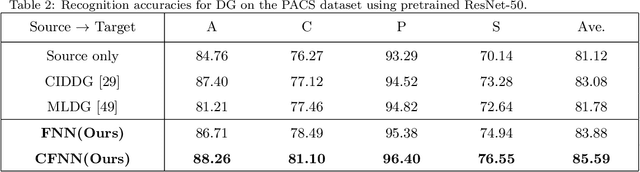
In this paper, we tackle the problem of training with multiple source domains with the aim to generalize to new domains at test time without an adaptation step. This is known as domain generalization (DG). Previous works on DG assume identical categories or label space across the source domains. In the case of category shift among the source domains, previous methods on DG are vulnerable to negative transfer due to the large mismatch among label spaces, decreasing the target classification accuracy. To tackle the aforementioned problem, we introduce an end-to-end feature-norm network (FNN) which is robust to negative transfer as it does not need to match the feature distribution among the source domains. We also introduce a collaborative feature-norm network (CFNN) to further improve the generalization capability of FNN. The CFNN matches the predictions of the next most likely categories for each training sample which increases each network's posterior entropy. We apply the proposed FNN and CFNN networks to the problem of DG for image classification tasks and demonstrate significant improvement over the state-of-the-art.
Correlation-aware Adversarial Domain Adaptation and Generalization
Nov 29, 2019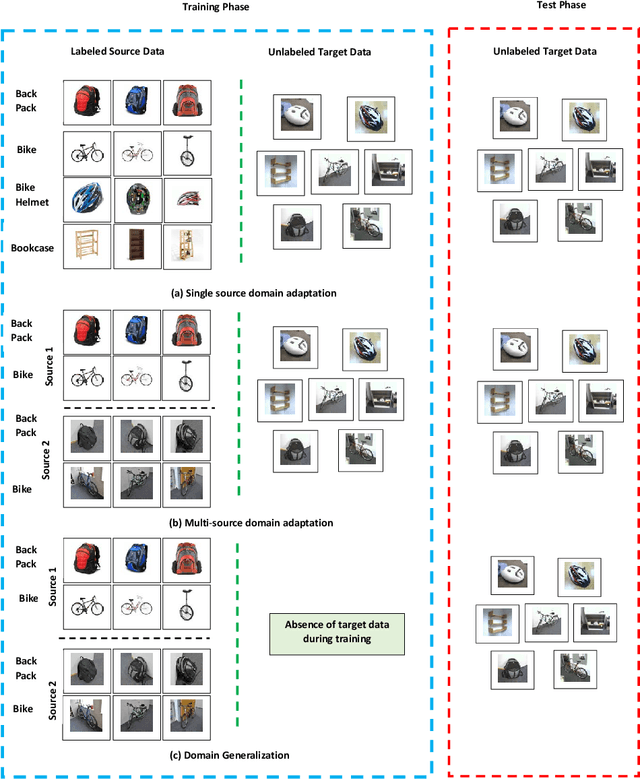
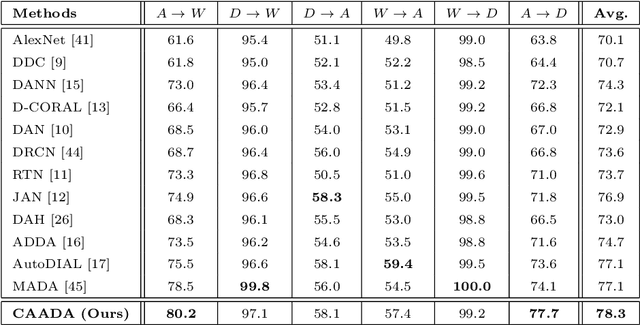
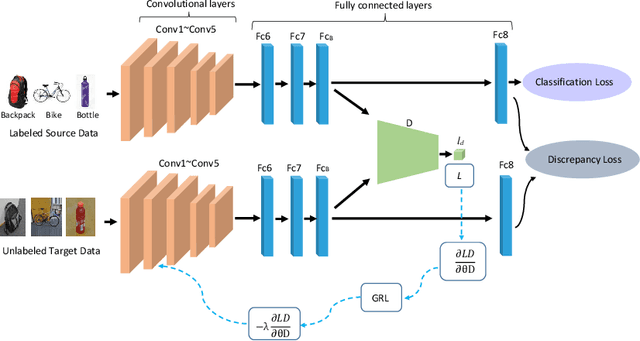
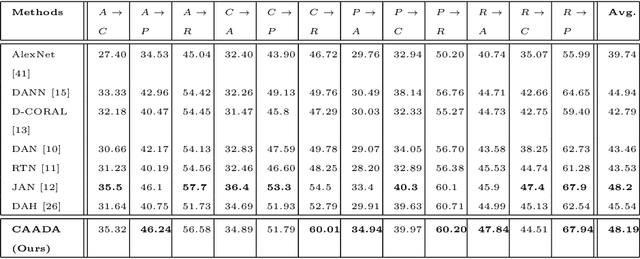
Domain adaptation (DA) and domain generalization (DG) have emerged as a solution to the domain shift problem where the distribution of the source and target data is different. The task of DG is more challenging than DA as the target data is totally unseen during the training phase in DG scenarios. The current state-of-the-art employs adversarial techniques, however, these are rarely considered for the DG problem. Furthermore, these approaches do not consider correlation alignment which has been proven highly beneficial for minimizing domain discrepancy. In this paper, we propose a correlation-aware adversarial DA and DG framework where the features of the source and target data are minimized using correlation alignment along with adversarial learning. Incorporating the correlation alignment module along with adversarial learning helps to achieve a more domain agnostic model due to the improved ability to reduce domain discrepancy with unlabeled target data more effectively. Experiments on benchmark datasets serve as evidence that our proposed method yields improved state-of-the-art performance.
On Minimum Discrepancy Estimation for Deep Domain Adaptation
Jan 02, 2019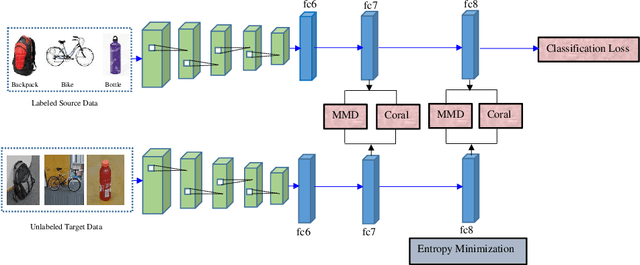
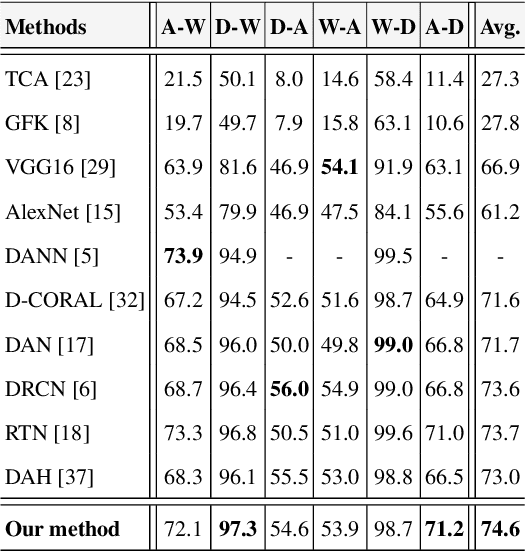

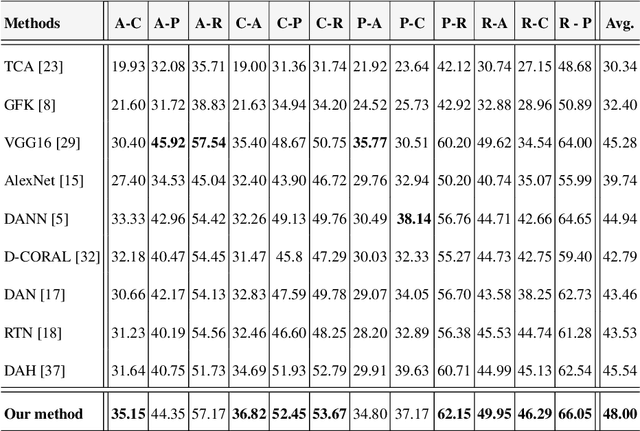
In the presence of large sets of labeled data, Deep Learning (DL) has accomplished extraordinary triumphs in the avenue of computer vision, particularly in object classification and recognition tasks. However, DL cannot always perform well when the training and testing images come from different distributions or in the presence of domain shift between training and testing images. They also suffer in the absence of labeled input data. Domain adaptation (DA) methods have been proposed to make up the poor performance due to domain shift. In this paper, we present a new unsupervised deep domain adaptation method based on the alignment of second order statistics (covariances) as well as maximum mean discrepancy of the source and target data with a two stream Convolutional Neural Network (CNN). We demonstrate the ability of the proposed approach to achieve state-of the-art performance for image classification on three benchmark domain adaptation datasets: Office-31 [27], Office-Home [37] and Office-Caltech [8].
Multi-component Image Translation for Deep Domain Generalization
Dec 21, 2018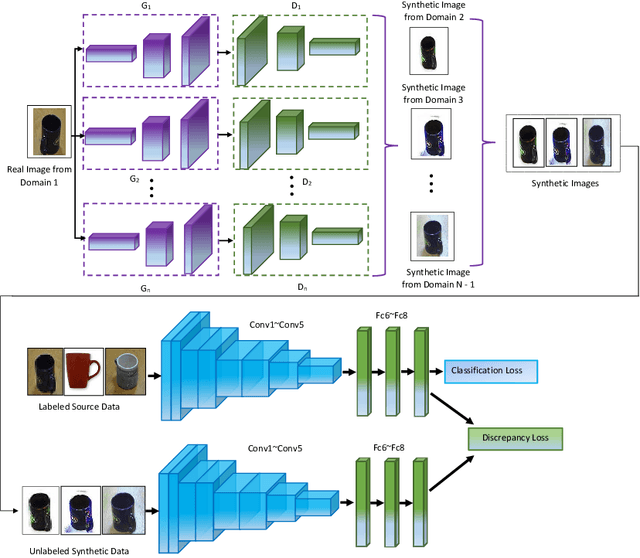
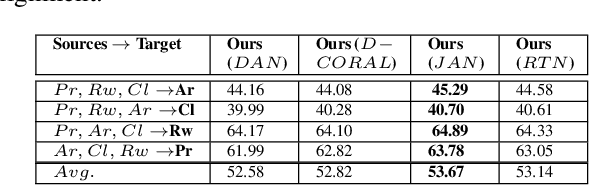
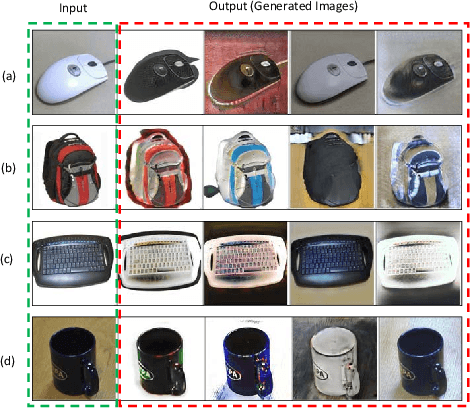
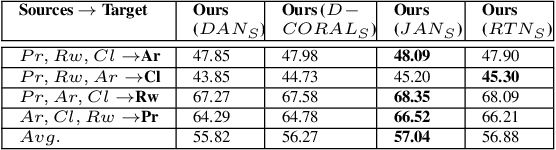
Domain adaption (DA) and domain generalization (DG) are two closely related methods which are both concerned with the task of assigning labels to an unlabeled data set. The only dissimilarity between these approaches is that DA can access the target data during the training phase, while the target data is totally unseen during the training phase in DG. The task of DG is challenging as we have no earlier knowledge of the target samples. If DA methods are applied directly to DG by a simple exclusion of the target data from training, poor performance will result for a given task. In this paper, we tackle the domain generalization challenge in two ways. In our first approach, we propose a novel deep domain generalization architecture utilizing synthetic data generated by a Generative Adversarial Network (GAN). The discrepancy between the generated images and synthetic images is minimized using existing domain discrepancy metrics such as maximum mean discrepancy or correlation alignment. In our second approach, we introduce a protocol for applying DA methods to a DG scenario by excluding the target data from the training phase, splitting the source data to training and validation parts, and treating the validation data as target data for DA. We conduct extensive experiments on four cross-domain benchmark datasets. Experimental results signify our proposed model outperforms the current state-of-the-art methods for DG.