 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttendNets: Tiny Deep Image Recognition Neural Networks for the Edge via Visual Attention Condensers
Sep 30, 2020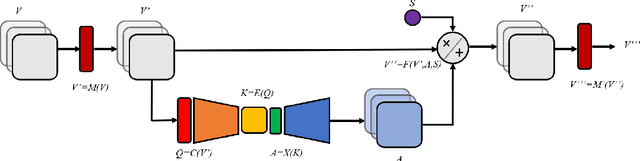
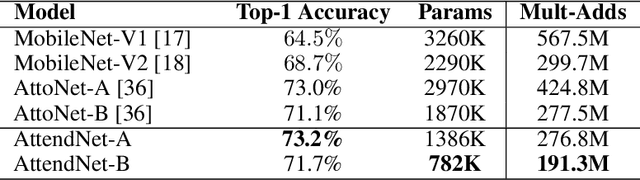
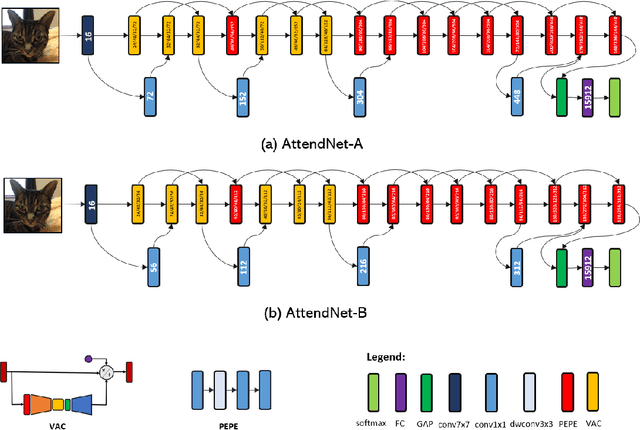
While significant advances in deep learning has resulted in state-of-the-art performance across a large number of complex visual perception tasks, the widespread deployment of deep neural networks for TinyML applications involving on-device, low-power image recognition remains a big challenge given the complexity of deep neural networks. In this study, we introduce AttendNets, low-precision, highly compact deep neural networks tailored for on-device image recognition. More specifically, AttendNets possess deep self-attention architectures based on visual attention condensers, which extends on the recently introduced stand-alone attention condensers to improve spatial-channel selective attention. Furthermore, AttendNets have unique machine-designed macroarchitecture and microarchitecture designs achieved via a machine-driven design exploration strategy. Experimental results on ImageNet$_{50}$ benchmark dataset for the task of on-device image recognition showed that AttendNets have significantly lower architectural and computational complexity when compared to several deep neural networks in research literature designed for efficiency while achieving highest accuracies (with the smallest AttendNet achieving $\sim$7.2% higher accuracy, while requiring $\sim$3$\times$ fewer multiply-add operations, $\sim$4.17$\times$ fewer parameters, and $\sim$16.7$\times$ lower weight memory requirements than MobileNet-V1). Based on these promising results, AttendNets illustrate the effectiveness of visual attention condensers as building blocks for enabling various on-device visual perception tasks for TinyML applications.
Vulnerability Under Adversarial Machine Learning: Bias or Variance?
Aug 01, 2020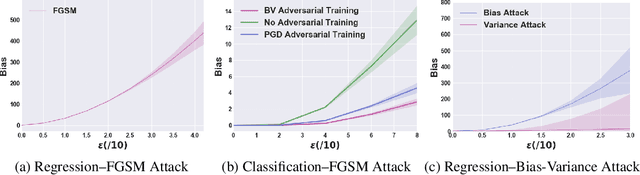
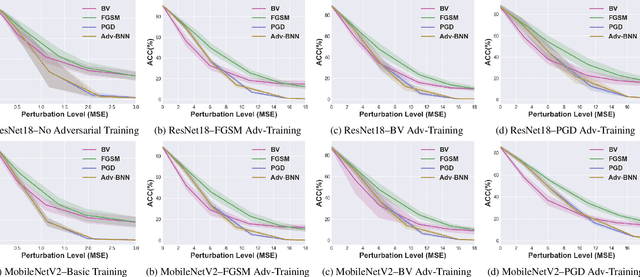
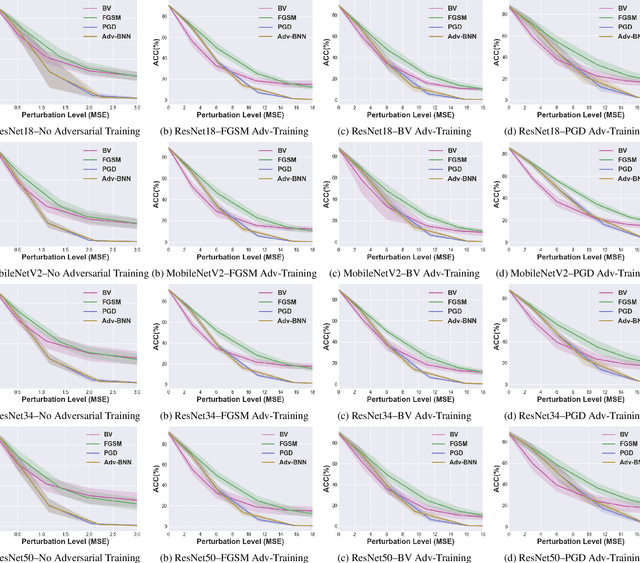
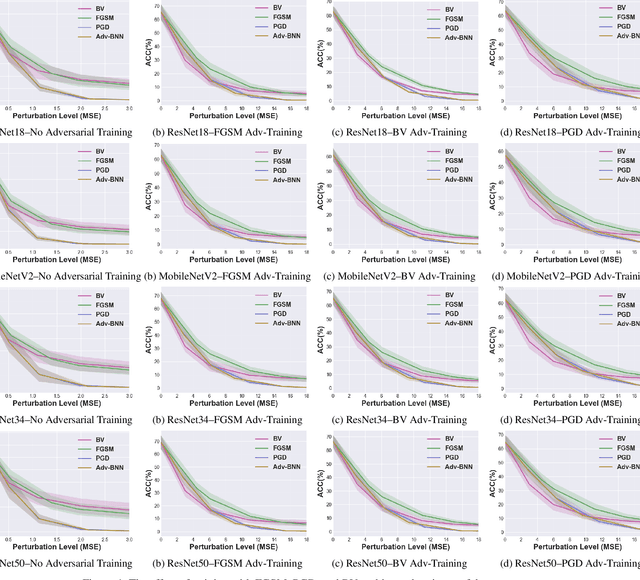
Prior studies have unveiled the vulnerability of the deep neural networks in the context of adversarial machine learning, leading to great recent attention into this area. One interesting question that has yet to be fully explored is the bias-variance relationship of adversarial machine learning, which can potentially provide deeper insights into this behaviour. The notion of bias and variance is one of the main approaches to analyze and evaluate the generalization and reliability of a machine learning model. Although it has been extensively used in other machine learning models, it is not well explored in the field of deep learning and it is even less explored in the area of adversarial machine learning. In this study, we investigate the effect of adversarial machine learning on the bias and variance of a trained deep neural network and analyze how adversarial perturbations can affect the generalization of a network. We derive the bias-variance trade-off for both classification and regression applications based on two main loss functions: (i) mean squared error (MSE), and (ii) cross-entropy. Furthermore, we perform quantitative analysis with both simulated and real data to empirically evaluate consistency with the derived bias-variance tradeoffs. Our analysis sheds light on why the deep neural networks have poor performance under adversarial perturbation from a bias-variance point of view and how this type of perturbation would change the performance of a network. Moreover, given these new theoretical findings, we introduce a new adversarial machine learning algorithm with lower computational complexity than well-known adversarial machine learning strategies (e.g., PGD) while providing a high success rate in fooling deep neural networks in lower perturbation magnitudes.
Deep Neural Network Perception Models and Robust Autonomous Driving Systems
Mar 04, 2020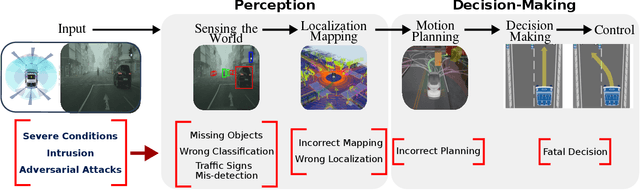


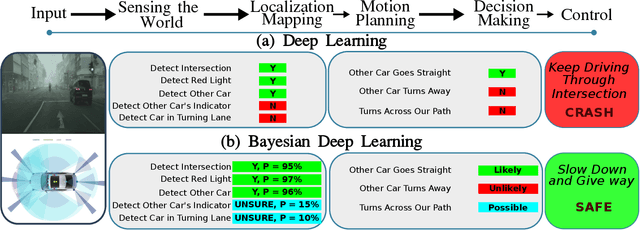
This paper analyzes the robustness of deep learning models in autonomous driving applications and discusses the practical solutions to address that.
Learn2Perturb: an End-to-end Feature Perturbation Learning to Improve Adversarial Robustness
Mar 03, 2020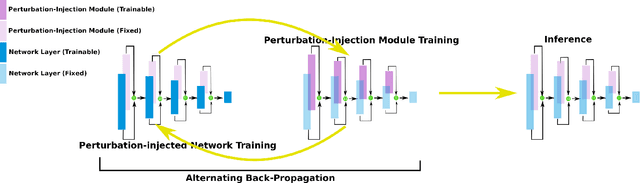

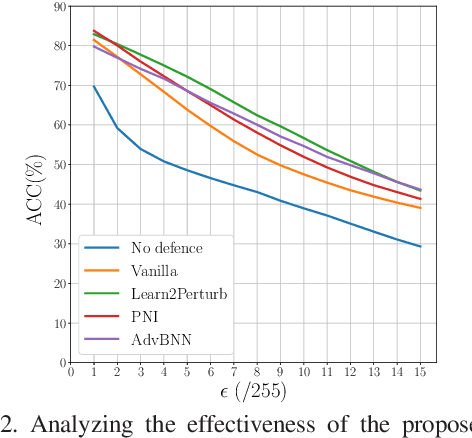
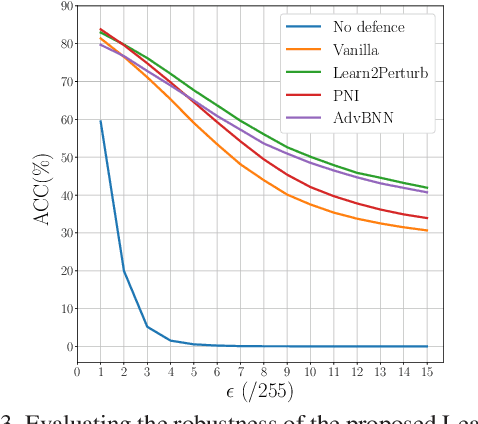
While deep neural networks have been achieving state-of-the-art performance across a wide variety of applications, their vulnerability to adversarial attacks limits their widespread deployment for safety-critical applications. Alongside other adversarial defense approaches being investigated, there has been a very recent interest in improving adversarial robustness in deep neural networks through the introduction of perturbations during the training process. However, such methods leverage fixed, pre-defined perturbations and require significant hyper-parameter tuning that makes them very difficult to leverage in a general fashion. In this study, we introduce Learn2Perturb, an end-to-end feature perturbation learning approach for improving the adversarial robustness of deep neural networks. More specifically, we introduce novel perturbation-injection modules that are incorporated at each layer to perturb the feature space and increase uncertainty in the network. This feature perturbation is performed at both the training and the inference stages. Furthermore, inspired by the Expectation-Maximization, an alternating back-propagation training algorithm is introduced to train the network and noise parameters consecutively. Experimental results on CIFAR-10 and CIFAR-100 datasets show that the proposed Learn2Perturb method can result in deep neural networks which are $4-7\%$ more robust on $l_{\infty}$ FGSM and PDG adversarial attacks and significantly outperforms the state-of-the-art against $l_2$ $C\&W$ attack and a wide range of well-known black-box attacks.
Do Explanations Reflect Decisions? A Machine-centric Strategy to Quantify the Performance of Explainability Algorithms
Oct 29, 2019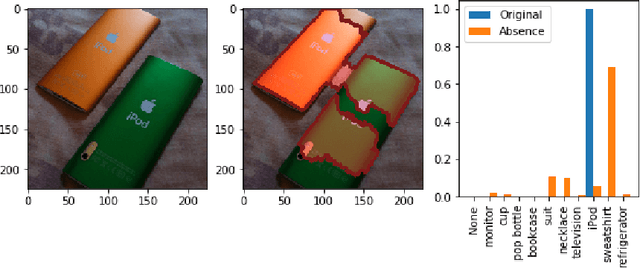
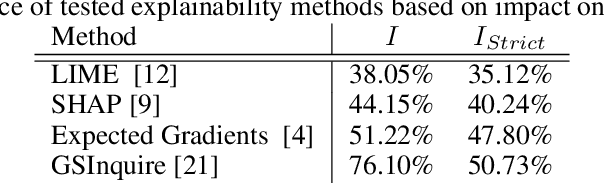
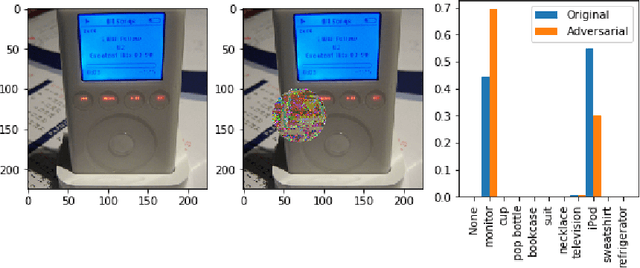

There has been a significant surge of interest recently around the concept of explainable artificial intelligence (XAI), where the goal is to produce an interpretation for a decision made by a machine learning algorithm. Of particular interest is the interpretation of how deep neural networks make decisions, given the complexity and `black box' nature of such networks. Given the infancy of the field, there has been very limited exploration into the assessment of the performance of explainability methods, with most evaluations centered around subjective visual interpretation of the produced interpretations. In this study, we explore a more machine-centric strategy for quantifying the performance of explainability methods on deep neural networks via the notion of decision-making impact analysis. We introduce two quantitative performance metrics: i) Impact Score, which assesses the percentage of critical factors with either strong confidence reduction impact or decision changing impact, and ii) Impact Coverage, which assesses the percentage coverage of adversarially impacted factors in the input. A comprehensive analysis using this approach was conducted on several state-of-the-art explainability methods (LIME, SHAP, Expected Gradients, GSInquire) on a ResNet-50 deep convolutional neural network using a subset of ImageNet for the task of image classification. Experimental results show that the critical regions identified by LIME within the tested images had the lowest impact on the decision-making process of the network (~38%), with progressive increase in decision-making impact for SHAP (~44%), Expected Gradients (~51%), and GSInquire (~76%). While by no means perfect, the hope is that the proposed machine-centric strategy helps push the conversation forward towards better metrics for evaluating explainability methods and improve trust in deep neural networks.
State of Compact Architecture Search For Deep Neural Networks
Oct 15, 2019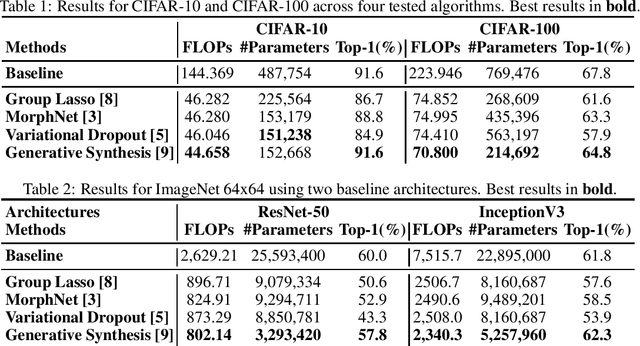
The design of compact deep neural networks is a crucial task to enable widespread adoption of deep neural networks in the real-world, particularly for edge and mobile scenarios. Due to the time-consuming and challenging nature of manually designing compact deep neural networks, there has been significant recent research interest into algorithms that automatically search for compact network architectures. A particularly interesting class of compact architecture search algorithms are those that are guided by baseline network architectures. Such algorithms have been shown to be significantly more computationally efficient than unguided methods. In this study, we explore the current state of compact architecture search for deep neural networks through both theoretical and empirical analysis of four different state-of-the-art compact architecture search algorithms: i) group lasso regularization, ii) variational dropout, iii) MorphNet, and iv) Generative Synthesis. We examine these methods in detail based on a number of different factors such as efficiency, effectiveness, and scalability. Furthermore, empirical evaluations are conducted to compare the efficacy of these compact architecture search algorithms across three well-known benchmark datasets. While by no means an exhaustive exploration, we hope that this study helps provide insights into the interesting state of this relatively new area of research in terms of diversity and real, tangible gains already achieved in architecture design improvements. Furthermore, the hope is that this study would help in pushing the conversation forward towards a deeper theoretical and empirical understanding where the research community currently stands in the landscape of compact architecture search for deep neural networks, and the practical challenges and considerations in leveraging such approaches for operational usage.
YOLO Nano: a Highly Compact You Only Look Once Convolutional Neural Network for Object Detection
Oct 03, 2019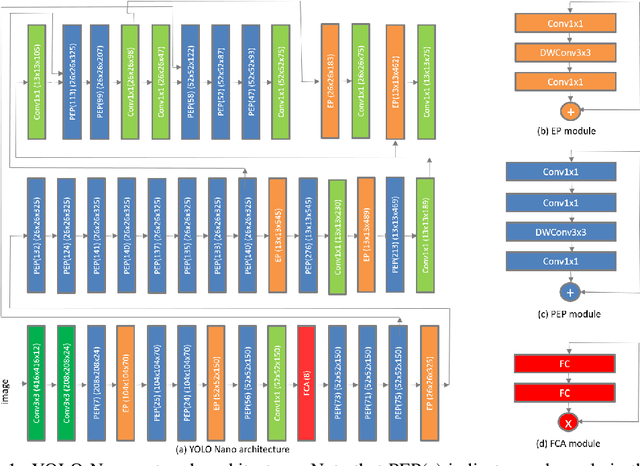
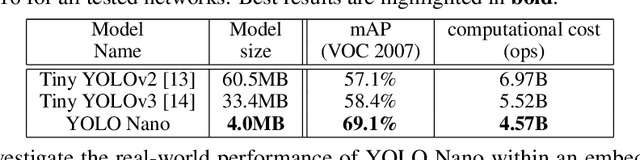
Object detection remains an active area of research in the field of computer vision, and considerable advances and successes has been achieved in this area through the design of deep convolutional neural networks for tackling object detection. Despite these successes, one of the biggest challenges to widespread deployment of such object detection networks on edge and mobile scenarios is the high computational and memory requirements. As such, there has been growing research interest in the design of efficient deep neural network architectures catered for edge and mobile usage. In this study, we introduce YOLO Nano, a highly compact deep convolutional neural network for the task of object detection. A human-machine collaborative design strategy is leveraged to create YOLO Nano, where principled network design prototyping, based on design principles from the YOLO family of single-shot object detection network architectures, is coupled with machine-driven design exploration to create a compact network with highly customized module-level macroarchitecture and microarchitecture designs tailored for the task of embedded object detection. The proposed YOLO Nano possesses a model size of ~4.0MB (>15.1x and >8.3x smaller than Tiny YOLOv2 and Tiny YOLOv3, respectively) and requires 4.57B operations for inference (>34% and ~17% lower than Tiny YOLOv2 and Tiny YOLOv3, respectively) while still achieving an mAP of ~69.1% on the VOC 2007 dataset (~12% and ~10.7% higher than Tiny YOLOv2 and Tiny YOLOv3, respectively). Experiments on inference speed and power efficiency on a Jetson AGX Xavier embedded module at different power budgets further demonstrate the efficacy of YOLO Nano for embedded scenarios.
Human-Machine Collaborative Design for Accelerated Design of Compact Deep Neural Networks for Autonomous Driving
Sep 12, 2019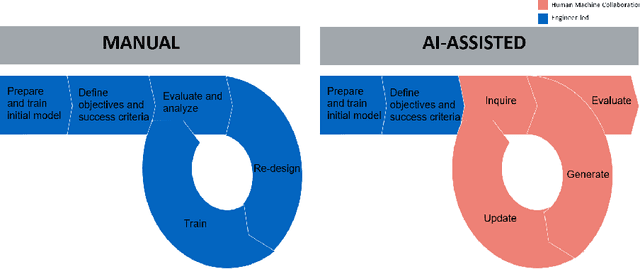

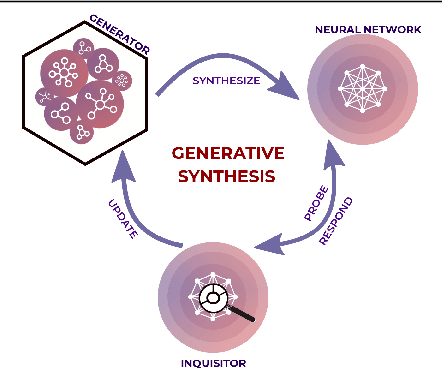
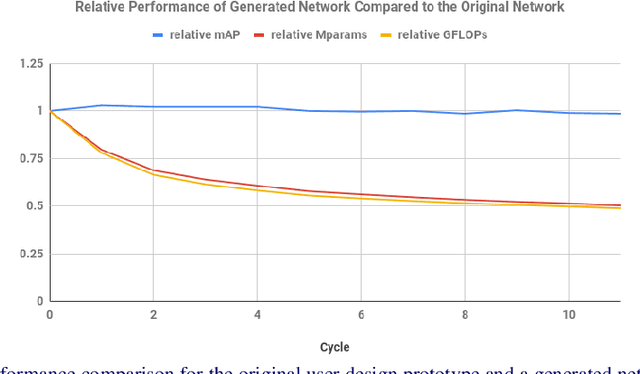
An effective deep learning development process is critical for widespread industrial adoption, particularly in the automotive sector. A typical industrial deep learning development cycle involves customizing and re-designing an off-the-shelf network architecture to meet the operational requirements of the target application, leading to considerable trial and error work by a machine learning practitioner. This approach greatly impedes development with a long turnaround time and the unsatisfactory quality of the created models. As a result, a development platform that can aid engineers in greatly accelerating the design and production of compact, optimized deep neural networks is highly desirable. In this joint industrial case study, we study the efficacy of the GenSynth AI-assisted AI design platform for accelerating the design of custom, optimized deep neural networks for autonomous driving through human-machine collaborative design. We perform a quantitative examination by evaluating 10 different compact deep neural networks produced by GenSynth for the purpose of object detection via a NASNet-based user network prototype design, targeted at a low-cost GPU-based accelerated embedded system. Furthermore, we quantitatively assess the talent hours and GPU processing hours used by the GenSynth process and three other approaches based on the typical industrial development process. In addition, we quantify the annual cloud cost savings for comprehensive testing using networks produced by GenSynth. Finally, we assess the usability and merits of the GenSynth process through user feedback. The findings of this case study showed that GenSynth is easy to use and can be effective at accelerating the design and production of compact, customized deep neural network.
Efficient Inference on Deep Neural Networks by Dynamic Representations and Decision Gates
Nov 06, 2018
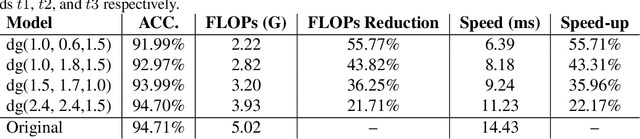
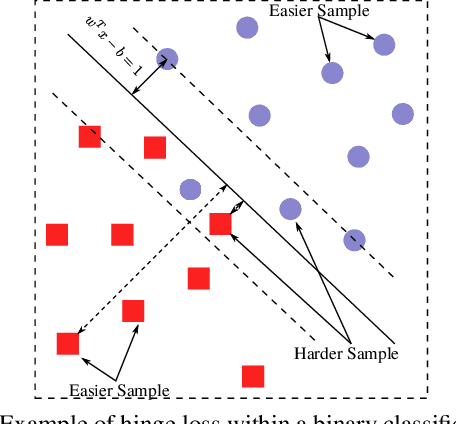
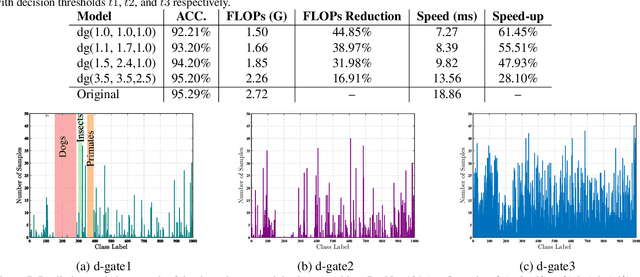
The current trade-off between depth and computational cost makes it difficult to adopt deep neural networks for many industrial applications, especially when computing power is limited. Here, we are inspired by the idea that, while deeper embeddings are needed to discriminate difficult samples, a large number of samples can be well discriminated via much shallower embeddings. In this study, we introduce the concept of decision gates (d-gate), modules trained to decide whether a sample needs to be projected into a deeper embedding or if an early prediction can be made at the d-gate, thus enabling the computation of dynamic representations at different depths. The proposed d-gate modules can be integrated with any deep neural network and reduces the average computational cost of the deep neural networks while maintaining modeling accuracy. Experimental results show that leveraging the proposed d-gate modules led to a ~38% speed-up and ~39% FLOPS reduction on ResNet-101 and ~46% speed-up and ~36% FLOPS reduction on DenseNet-201 trained on the CIFAR10 dataset with only ~2\% drop in accuracy.
MicronNet: A Highly Compact Deep Convolutional Neural Network Architecture for Real-time Embedded Traffic Sign Classification
Oct 03, 2018
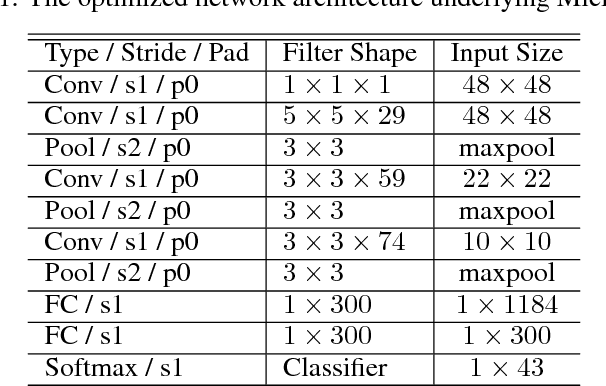

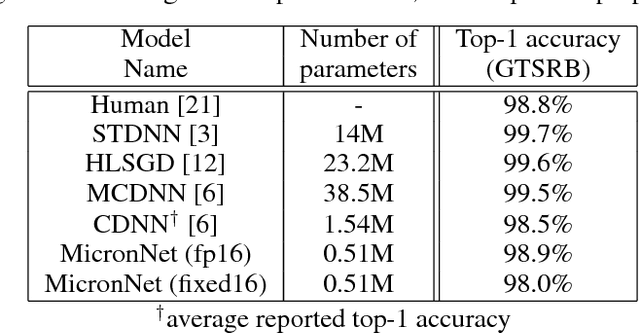
Traffic sign recognition is a very important computer vision task for a number of real-world applications such as intelligent transportation surveillance and analysis. While deep neural networks have been demonstrated in recent years to provide state-of-the-art performance traffic sign recognition, a key challenge for enabling the widespread deployment of deep neural networks for embedded traffic sign recognition is the high computational and memory requirements of such networks. As a consequence, there are significant benefits in investigating compact deep neural network architectures for traffic sign recognition that are better suited for embedded devices. In this paper, we introduce MicronNet, a highly compact deep convolutional neural network for real-time embedded traffic sign recognition designed based on macroarchitecture design principles (e.g., spectral macroarchitecture augmentation, parameter precision optimization, etc.) as well as numerical microarchitecture optimization strategies. The resulting overall architecture of MicronNet is thus designed with as few parameters and computations as possible while maintaining recognition performance, leading to optimized information density of the proposed network. The resulting MicronNet possesses a model size of just ~1MB and ~510,000 parameters (~27x fewer parameters than state-of-the-art) while still achieving a human performance level top-1 accuracy of 98.9% on the German traffic sign recognition benchmark. Furthermore, MicronNet requires just ~10 million multiply-accumulate operations to perform inference, and has a time-to-compute of just 32.19 ms on a Cortex-A53 high efficiency processor. These experimental results show that highly compact, optimized deep neural network architectures can be designed for real-time traffic sign recognition that are well-suited for embedded scenarios.