 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsunami: A Learned Multi-dimensional Index for Correlated Data and Skewed Workloads
Jun 23, 2020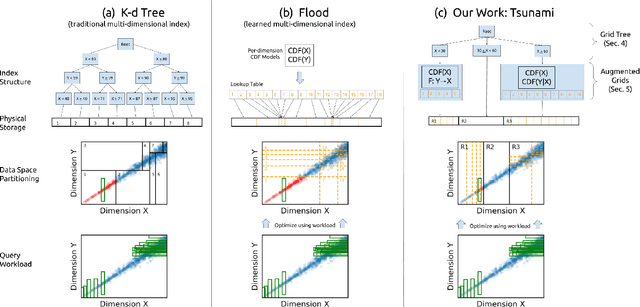

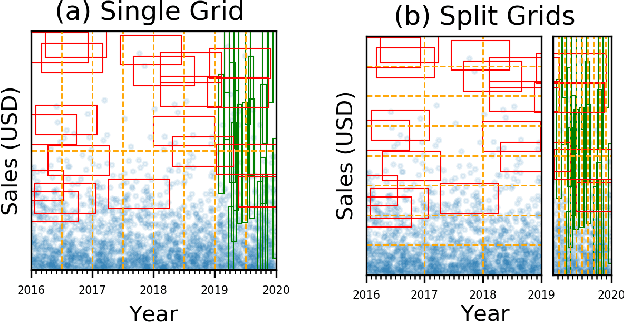

Filtering data based on predicates is one of the most fundamental operations for any modern data warehouse. Techniques to accelerate the execution of filter expressions include clustered indexes, specialized sort orders (e.g., Z-order), multi-dimensional indexes, and, for high selectivity queries, secondary indexes. However, these schemes are hard to tune and their performance is inconsistent. Recent work on learned multi-dimensional indexes has introduced the idea of automatically optimizing an index for a particular dataset and workload. However, the performance of that work suffers in the presence of correlated data and skewed query workloads, both of which are common in real applications. In this paper, we introduce Tsunami, which addresses these limitations to achieve up to 6X faster query performance and up to 8X smaller index size than existing learned multi-dimensional indexes, in addition to up to 11X faster query performance and 170X smaller index size than optimally-tuned traditional indexes.
Real-Time Video Inference on Edge Devices via Adaptive Model Streaming
Jun 11, 2020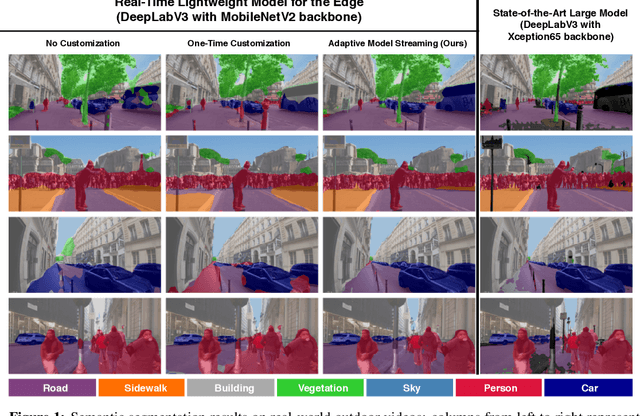

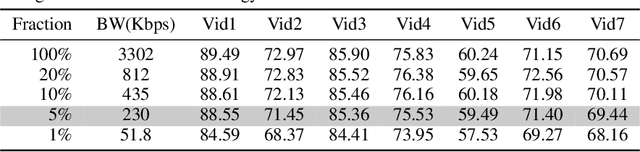
Real-time video inference on compute-limited edge devices like mobile phones and drones is challenging due to the high computation cost of Deep Neural Network models. In this paper we propose Adaptive Model Streaming (AMS), a cloud-assisted approach to real-time video inference on edge devices. The key idea in AMS is to use online learning to continually adapt a lightweight model running on an edge device to boost its performance on the video scenes in real-time. The model is trained in a cloud server and is periodically sent to the edge device. We discuss the challenges of online learning for video and present a practical design that takes into account the edge device, cloud server, and network bandwidth resource limitations. On the task of video semantic segmentation, our experimental results show 5.1--17.0 percent mean Intersection-over-Union improvement compared to a pre-trained model on several real-world videos. Our prototype can perform video segmentation at 30 frames-per-second with 40 milliseconds camera-to-label latency on a Samsung Galaxy S10+ mobile phone, using less than 400Kbps uplink and downlink bandwidth on the device.
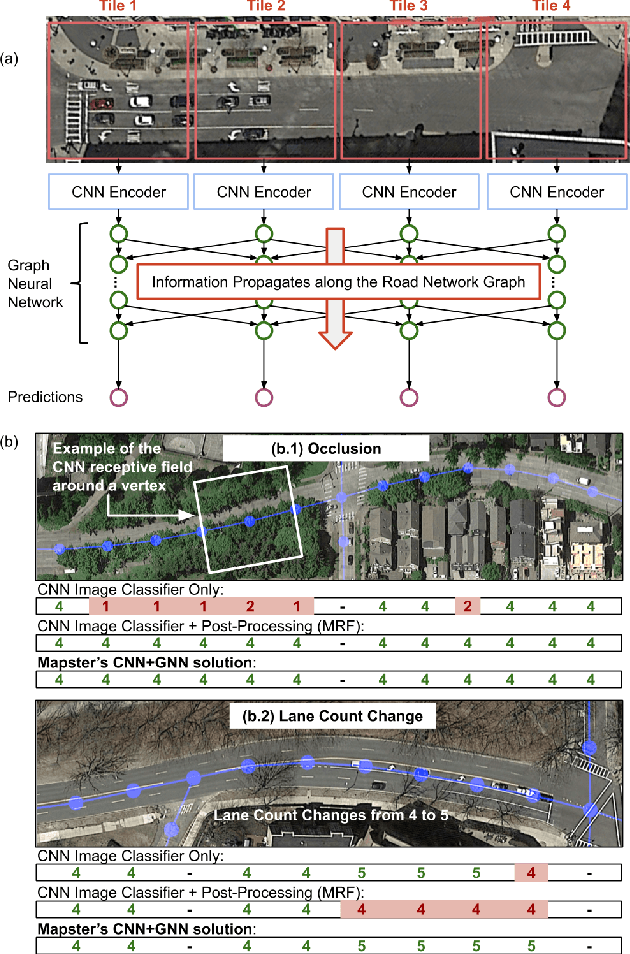
RoadTagger: Robust Road Attribute Inference with Graph Neural Networks
Dec 28, 2019
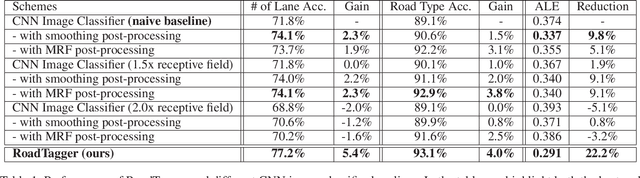
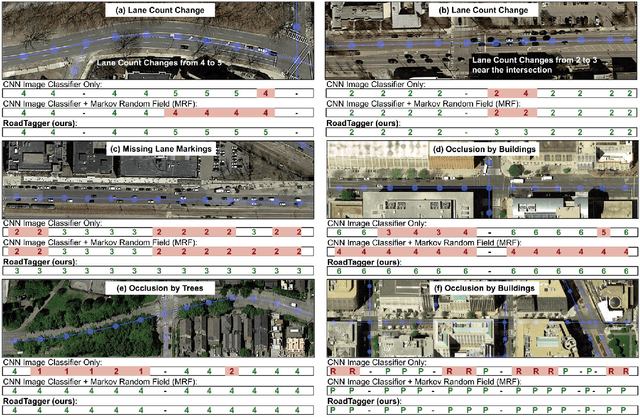
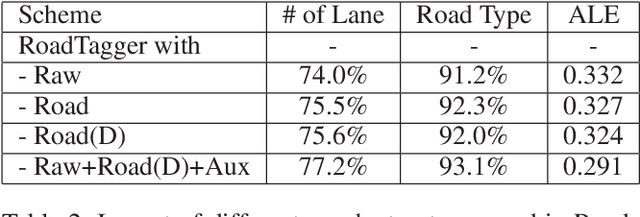
Inferring road attributes such as lane count and road type from satellite imagery is challenging. Often, due to the occlusion in satellite imagery and the spatial correlation of road attributes, a road attribute at one position on a road may only be apparent when considering far-away segments of the road. Thus, to robustly infer road attributes, the model must integrate scattered information and capture the spatial correlation of features along roads. Existing solutions that rely on image classifiers fail to capture this correlation, resulting in poor accuracy. We find this failure is caused by a fundamental limitation -- the limited effective receptive field of image classifiers. To overcome this limitation, we propose RoadTagger, an end-to-end architecture which combines both Convolutional Neural Networks (CNNs) and Graph Neural Networks (GNNs) to infer road attributes. The usage of graph neural networks allows information propagation on the road network graph and eliminates the receptive field limitation of image classifiers. We evaluate RoadTagger on both a large real-world dataset covering 688 km^2 area in 20 U.S. cities and a synthesized micro-dataset. In the evaluation, RoadTagger improves inference accuracy over the CNN image classifier based approaches. RoadTagger also demonstrates strong robustness against different disruptions in the satellite imagery and the ability to learn complicated inductive rules for aggregating scattered information along the road network.
Learning Multi-dimensional Indexes
Dec 03, 2019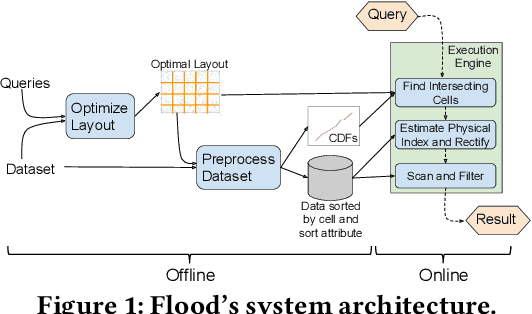
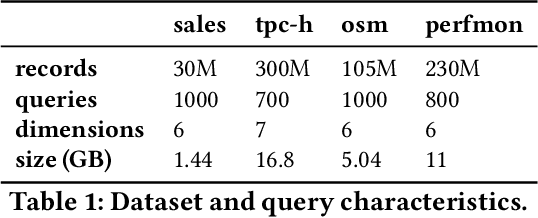
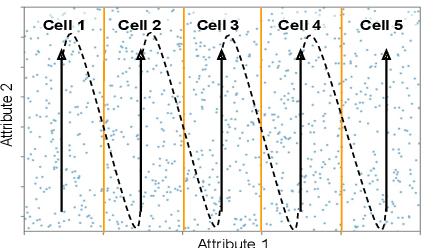
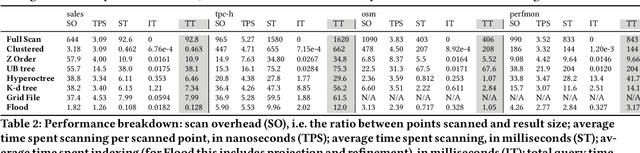
Scanning and filtering over multi-dimensional tables are key operations in modern analytical database engines. To optimize the performance of these operations, databases often create clustered indexes over a single dimension or multi-dimensional indexes such as R-trees, or use complex sort orders (e.g., Z-ordering). However, these schemes are often hard to tune and their performance is inconsistent across different datasets and queries. In this paper, we introduce Flood, a multi-dimensional in-memory index that automatically adapts itself to a particular dataset and workload by jointly optimizing the index structure and data storage. Flood achieves up to three orders of magnitude faster performance for range scans with predicates than state-of-the-art multi-dimensional indexes or sort orders on real-world datasets and workloads. Our work serves as a building block towards an end-to-end learned database system.
Inferring and Improving Street Maps with Data-Driven Automation
Nov 06, 2019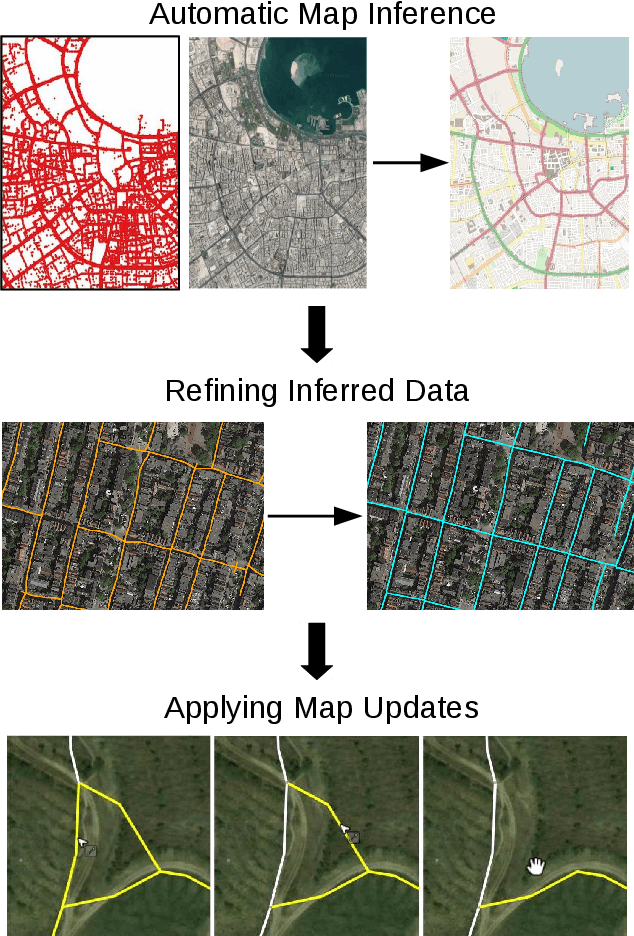
Street maps are a crucial data source that help to inform a wide range of decisions, from navigating a city to disaster relief and urban planning. However, in many parts of the world, street maps are incomplete or lag behind new construction. Editing maps today involves a tedious process of manually tracing and annotating roads, buildings, and other map features. Over the past decade, many automatic map inference systems have been proposed to automatically extract street map data from satellite imagery, aerial imagery, and GPS trajectory datasets. However, automatic map inference has failed to gain traction in practice due to two key limitations: high error rates (low precision), which manifest in noisy inference outputs, and a lack of end-to-end system design to leverage inferred data to update existing street maps. At MIT and QCRI, we have developed a number of algorithms and approaches to address these challenges, which we combined into a new system we call Mapster. Mapster is a human-in-the-loop street map editing system that incorporates three components to robustly accelerate the mapping process over traditional tools and workflows: high-precision automatic map inference, data refinement, and machine-assisted map editing. Through an evaluation on a large-scale dataset including satellite imagery, GPS trajectories, and ground-truth map data in forty cities, we show that Mapster makes automation practical for map editing, and enables the curation of map datasets that are more complete and up-to-date at less cost.
Placeto: Learning Generalizable Device Placement Algorithms for Distributed Machine Learning
Jun 20, 2019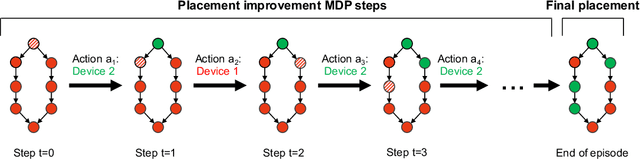
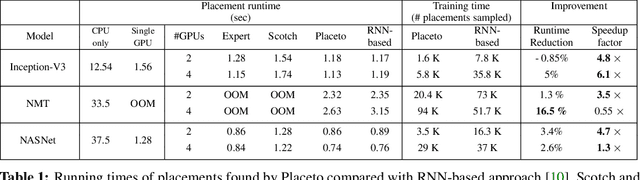
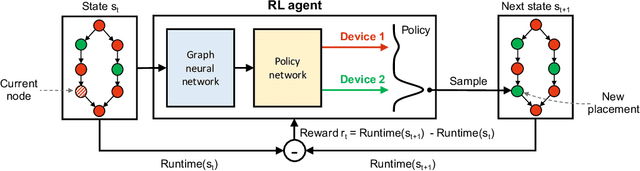
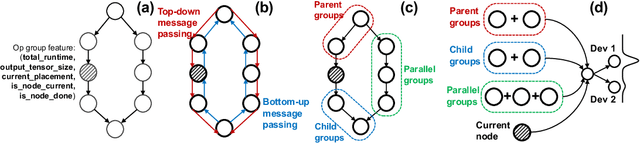
We present Placeto, a reinforcement learning (RL) approach to efficiently find device placements for distributed neural network training. Unlike prior approaches that only find a device placement for a specific computation graph, Placeto can learn generalizable device placement policies that can be applied to any graph. We propose two key ideas in our approach: (1) we represent the policy as performing iterative placement improvements, rather than outputting a placement in one shot; (2) we use graph embeddings to capture relevant information about the structure of the computation graph, without relying on node labels for indexing. These ideas allow Placeto to train efficiently and generalize to unseen graphs. Our experiments show that Placeto requires up to 6.1x fewer training steps to find placements that are on par with or better than the best placements found by prior approaches. Moreover, Placeto is able to learn a generalizable placement policy for any given family of graphs, which can then be used without any retraining to predict optimized placements for unseen graphs from the same family. This eliminates the large overhead incurred by prior RL approaches whose lack of generalizability necessitates re-training from scratch every time a new graph is to be placed.
Machine-Assisted Map Editing
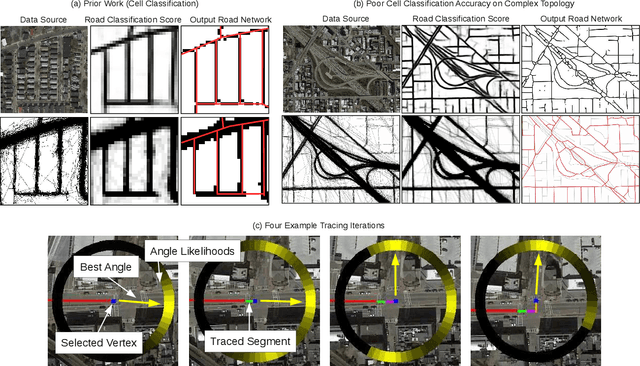
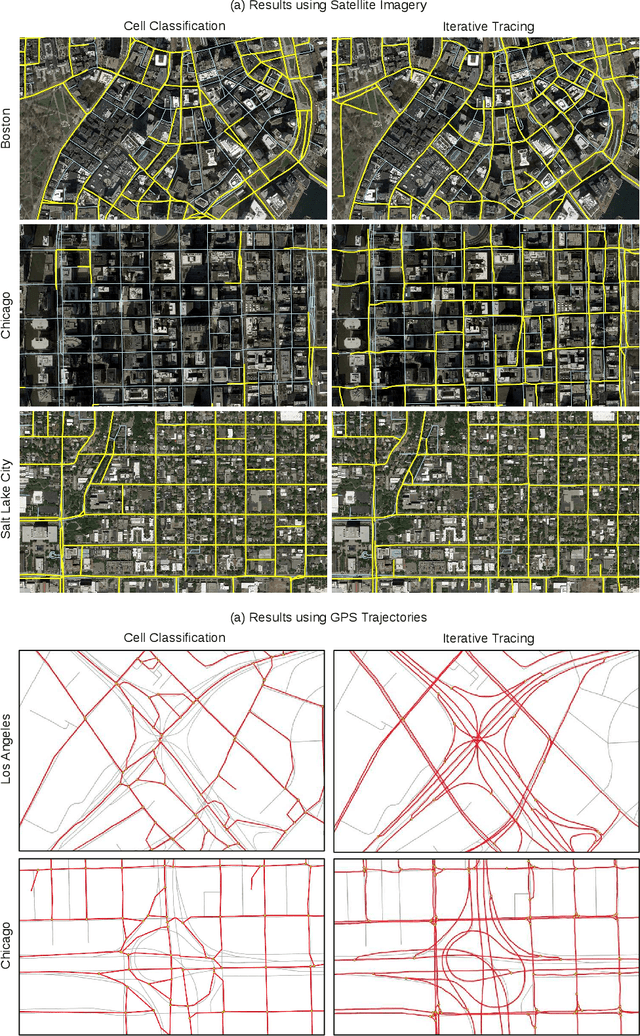
Jun 17, 2019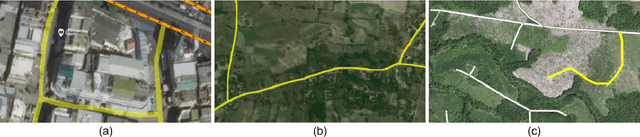
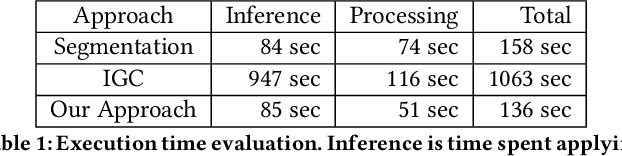

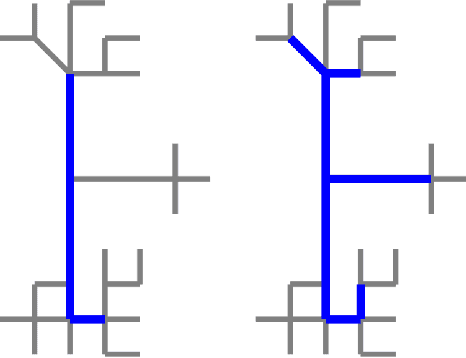
Mapping road networks today is labor-intensive. As a result, road maps have poor coverage outside urban centers in many countries. Systems to automatically infer road network graphs from aerial imagery and GPS trajectories have been proposed to improve coverage of road maps. However, because of high error rates, these systems have not been adopted by mapping communities. We propose machine-assisted map editing, where automatic map inference is integrated into existing, human-centric map editing workflows. To realize this, we build Machine-Assisted iD (MAiD), where we extend the web-based OpenStreetMap editor, iD, with machine-assistance functionality. We complement MAiD with a novel approach for inferring road topology from aerial imagery that combines the speed of prior segmentation approaches with the accuracy of prior iterative graph construction methods. We design MAiD to tackle the addition of major, arterial roads in regions where existing maps have poor coverage, and the incremental improvement of coverage in regions where major roads are already mapped. We conduct two user studies and find that, when participants are given a fixed time to map roads, they are able to add as much as 3.5x more roads with MAiD.
Adaptive Neural Signal Detection for Massive MIMO
Jun 11, 2019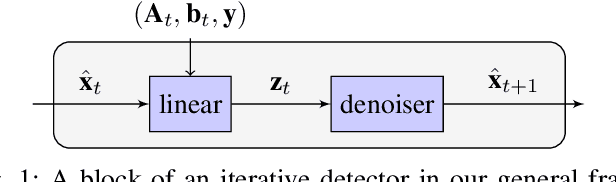
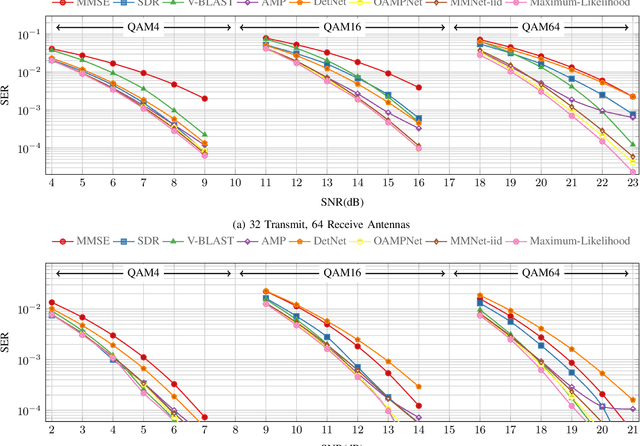
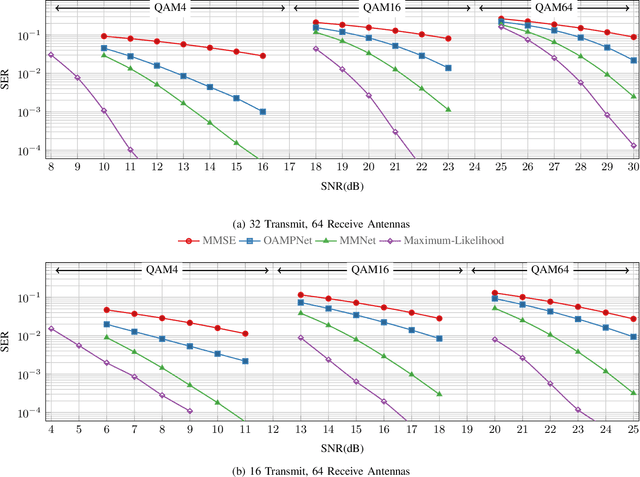
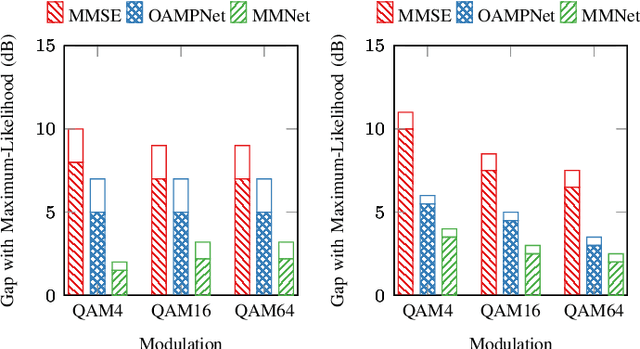
Symbol detection for Massive Multiple-Input Multiple-Output (MIMO) is a challenging problem for which traditional algorithms are either impractical or suffer from performance limitations. Several recently proposed learning-based approaches achieve promising results on simple channel models (e.g., i.i.d. Gaussian). However, their performance degrades significantly on real-world channels with spatial correlation. We propose MMNet, a deep learning MIMO detection scheme that significantly outperforms existing approaches on realistic channels with the same or lower computational complexity. MMNet's design builds on the theory of iterative soft-thresholding algorithms and uses a novel training algorithm that leverages temporal and spectral correlation to accelerate training. Together, these innovations allow MMNet to train online for every realization of the channel. On i.i.d. Gaussian channels, MMNet requires two orders of magnitude fewer operations than existing deep learning schemes but achieves near-optimal performance. On spatially-correlated channels, it achieves the same error rate as the next-best learning scheme (OAMPNet) at 2.5dB lower SNR and with at least 10x less computational complexity. MMNet is also 4--8dB better overall than a classic linear scheme like the minimum mean square error (MMSE) detector.
Learning Scheduling Algorithms for Data Processing Clusters
Oct 12, 2018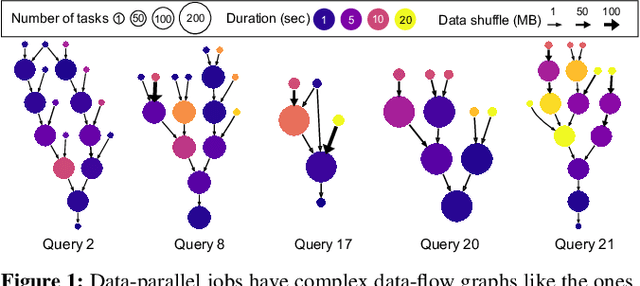

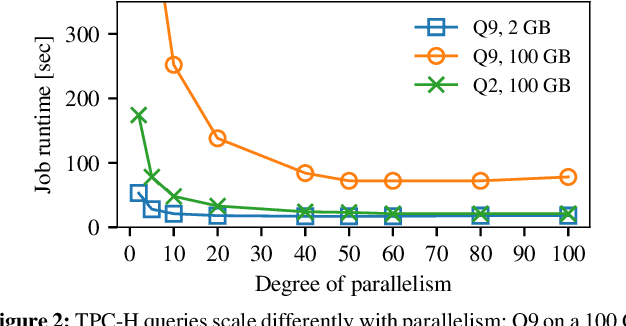

Efficiently scheduling data processing jobs on distributed compute clusters requires complex algorithms. Current systems, however, use simple generalized heuristics and ignore workload structure, since developing and tuning a bespoke heuristic for each workload is infeasible. In this paper, we show that modern machine learning techniques can generate highly-efficient policies automatically. Decima uses reinforcement learning (RL) and neural networks to learn workload-specific scheduling algorithms without any human instruction beyond specifying a high-level objective such as minimizing average job completion time. Off-the-shelf RL techniques, however, cannot handle the complexity and scale of the scheduling problem. To build Decima, we had to develop new representations for jobs' dependency graphs, design scalable RL models, and invent new RL training methods for continuous job arrivals. Our prototype integration with Spark on a 25-node cluster shows that Decima outperforms several heuristics, including hand-tuned ones, by at least 21%. Further experiments with an industrial production workload trace demonstrate that Decima delivers up to a 17% reduction in average job completion time and scales to large clusters.
Graph2Seq: Scalable Learning Dynamics for Graphs
Oct 09, 2018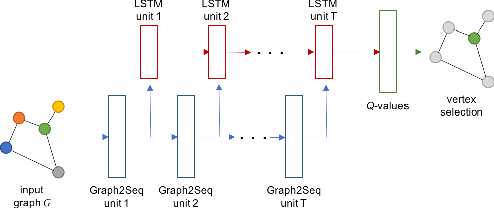
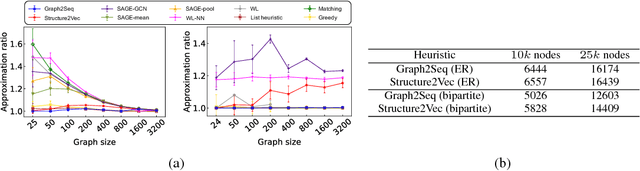
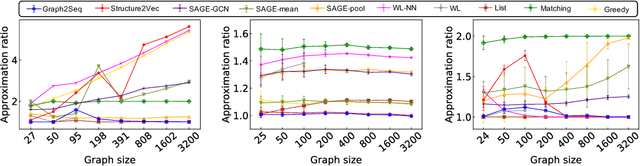
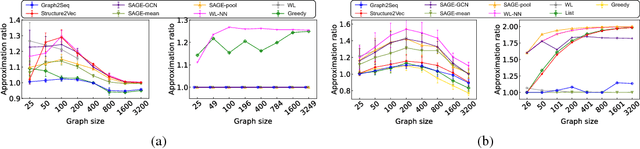
Neural networks have been shown to be an effective tool for learning algorithms over graph-structured data. However, graph representation techniques---that convert graphs to real-valued vectors for use with neural networks---are still in their infancy. Recent works have proposed several approaches (e.g., graph convolutional networks), but these methods have difficulty scaling and generalizing to graphs with different sizes and shapes. We present Graph2Seq, a new technique that represents vertices of graphs as infinite time-series. By not limiting the representation to a fixed dimension, Graph2Seq scales naturally to graphs of arbitrary sizes and shapes. Graph2Seq is also reversible, allowing full recovery of the graph structure from the sequences. By analyzing a formal computational model for graph representation, we show that an unbounded sequence is necessary for scalability. Our experimental results with Graph2Seq show strong generalization and new state-of-the-art performance on a variety of graph combinatorial optimization problems.