 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Elicitation of Collective Disagreements
May 19, 2026We analyze the structure of the disagreement among a population of voters over a set of alternatives. Surveys typically ask either for pairwise comparisons, simple and intuitive for participants, or full rankings over alternatives, eliciting the entire voters' preferences. Building on the observation that pairwise comparisons cannot distinguish structural disagreement from noise, we propose a stratified framework to identify the minimal aggregated preference information needed to compute a number of disagreement measures from the literature. Specifically, we introduce the plurality matrix, a generalization of pairwise comparisons that records, for every subset $S$ of alternatives, the probability that each $a \in S$ ranks first in $S$. We define the level of a disagreement measure as the smallest subset size needed to express it, showing that many existing notions, including rank-variance and divisiveness, sit at level $3$, proving that pairwise comparisons are not enough. In addition, we demonstrate the interest of going beyond level $3$ both theoretically and experimentally. To make these results actionable, we design two elicitation protocols to estimate the plurality matrix, exploring the trade-off between the number of required participants and the cognitive load requested to each of them.
Robust Ordinal Regression for Subsets Comparisons with Interactions
Aug 07, 2023This paper is dedicated to a robust ordinal method for learning the preferences of a decision maker between subsets. The decision model, derived from Fishburn and LaValle (1996) and whose parameters we learn, is general enough to be compatible with any strict weak order on subsets, thanks to the consideration of possible interactions between elements. Moreover, we accept not to predict some preferences if the available preference data are not compatible with a reliable prediction. A predicted preference is considered reliable if all the simplest models (Occam's razor) explaining the preference data agree on it. Following the robust ordinal regression methodology, our predictions are based on an uncertainty set encompassing the possible values of the model parameters. We define a robust ordinal dominance relation between subsets and we design a procedure to determine whether this dominance relation holds. Numerical tests are provided on synthetic and real-world data to evaluate the richness and reliability of the preference predictions made.
Cautious Learning of Multiattribute Preferences
Jun 15, 2022
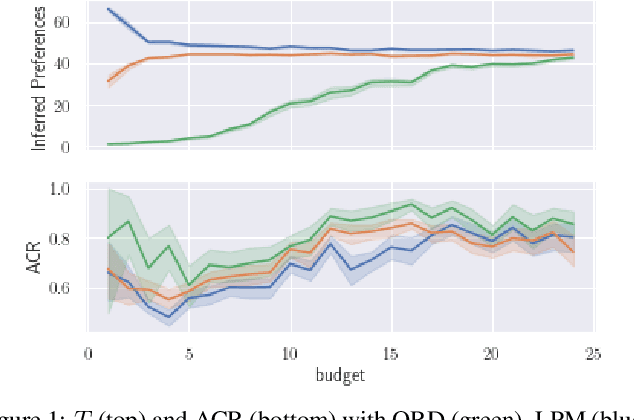
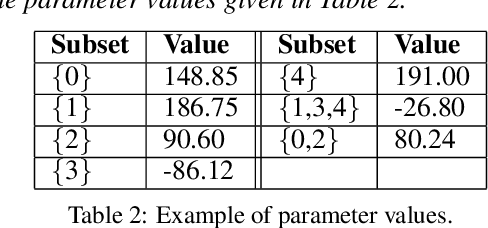
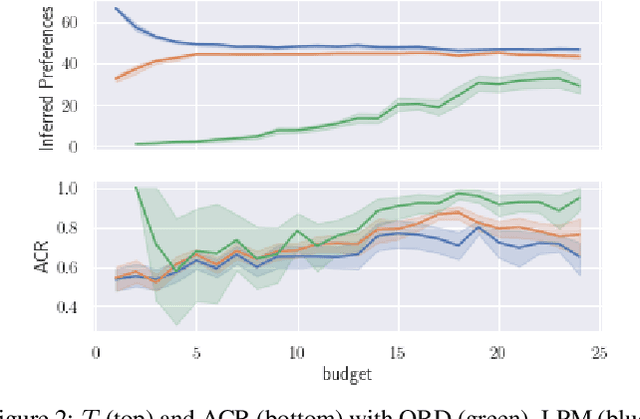
This paper is dedicated to a cautious learning methodology for predicting preferences between alternatives characterized by binary attributes (formally, each alternative is seen as a subset of attributes). By "cautious", we mean that the model learned to represent the multi-attribute preferences is general enough to be compatible with any strict weak order on the alternatives, and that we allow ourselves not to predict some preferences if the data collected are not compatible with a reliable prediction. A predicted preference will be considered reliable if all the simplest models (following Occam's razor principle) explaining the training data agree on it. Predictions are based on an ordinal dominance relation between alternatives [Fishburn and LaValle, 1996]. The dominance relation relies on an uncertainty set encompassing the possible values of the parameters of the multi-attribute utility function. Numerical tests are provided to evaluate the richness and the reliability of the predictions made.