 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferent Strokes for Different Folks: Writer Identification for Historical Arabic Manuscripts
Apr 24, 2026Handwritten Arabic manuscripts preserve the Arab world's intellectual and cultural heritage, and writer identification supports provenance, authenticity verification, and historical analysis. Using the Muharaf dataset of historical Arabic manuscripts, we evaluate writer identification from individual line images and, to the best of our knowledge, provide the first baselines reported under both line-level and page-disjoint evaluation protocols. Since the dataset is only partially labeled for writer identification, we manually verified and expanded writer labels in the public portion from 6,858 (28.00%) to 21,249 lines (86.75%) out of 24,495 line images, correcting inconsistencies and removing non-handwritten text. After further filtering, we retained 18,987 lines (77.51%). We propose a Convolutional Neural Network (CNN)-based model with attention mechanisms for closed-set writer identification, including rare two-writer lines modeled as composite writer-pair classes. We benchmark fourteen configurations and conduct ablations across different feature extractors and training regimes. To assess generalization to unseen pages, the page-disjoint protocol assigns all lines from each page to a single split. Under the line-level protocol, a fine-tuned DenseNet201 with attention achieves 99.05% Top-1 accuracy, 99.73% Top-5 accuracy, and 97.44% F1-score. Under the more challenging page-disjoint protocol, the best observed results are 78.61% Top-1 accuracy, 87.79% Top-5 accuracy, and 66.55% F1-score, thus quantifying the impact of page-level cues. By expanding the Muharaf dataset's labeled subset and reporting both protocols, we provide a clearer benchmark and a practical resource for historians and linguists engaged with culturally and historically significant documents. The code and implementation details are available on GitHub.
Quantized Neural Networks for Microcontrollers: A Comprehensive Review of Methods, Platforms, and Applications
Aug 20, 2025



The deployment of Quantized Neural Networks (QNNs) on resource-constrained devices, such as microcontrollers, has introduced significant challenges in balancing model performance, computational complexity and memory constraints. Tiny Machine Learning (TinyML) addresses these issues by integrating advancements across machine learning algorithms, hardware acceleration, and software optimization to efficiently run deep neural networks on embedded systems. This survey presents a hardware-centric introduction to quantization, systematically reviewing essential quantization techniques employed to accelerate deep learning models for embedded applications. In particular, further emphasis is put on critical trade-offs among model performance and hardware capabilities. The survey further evaluates existing software frameworks and hardware platforms designed specifically for supporting QNN execution on microcontrollers. Moreover, we provide an analysis of the current challenges and an outline of promising future directions in the rapidly evolving domain of QNN deployment.
Indoor Localization Under Limited Measurements: A Cross-Environment Joint Semi-Supervised and Transfer Learning Approach
Aug 04, 2021
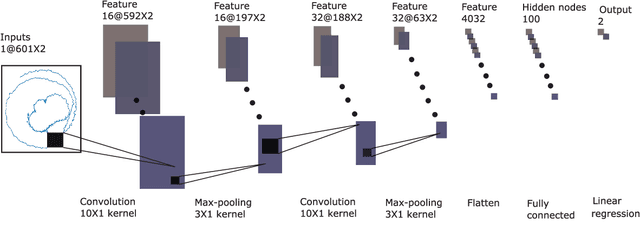
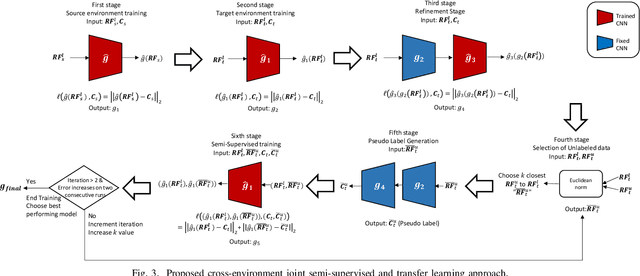
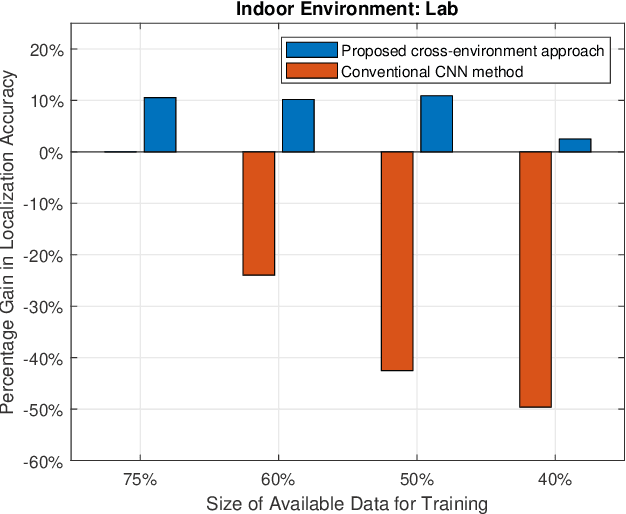
The development of highly accurate deep learning methods for indoor localization is often hindered by the unavailability of sufficient data measurements in the desired environment to perform model training. To overcome the challenge of collecting costly measurements, this paper proposes a cross-environment approach that compensates for insufficient labelled measurements via a joint semi-supervised and transfer learning technique to transfer, in an appropriate manner, the model obtained from a rich-data environment to the desired environment for which data is limited. This is achieved via a sequence of operations that exploit the similarity across environments to enhance unlabelled data model training of the desired environment. Numerical experiments demonstrate that the proposed cross-environment approach outperforms the conventional method, convolutional neural network (CNN), with a significant increase in localization accuracy, up to 43%. Moreover, with only 40% data measurements, the proposed cross-environment approach compensates for data inadequacy and replicates the localization accuracy of the conventional method, CNN, which uses 75% data measurements.
Indoor Localization for IoT Using Adaptive Feature Selection: A Cascaded Machine Learning Approach
May 03, 2019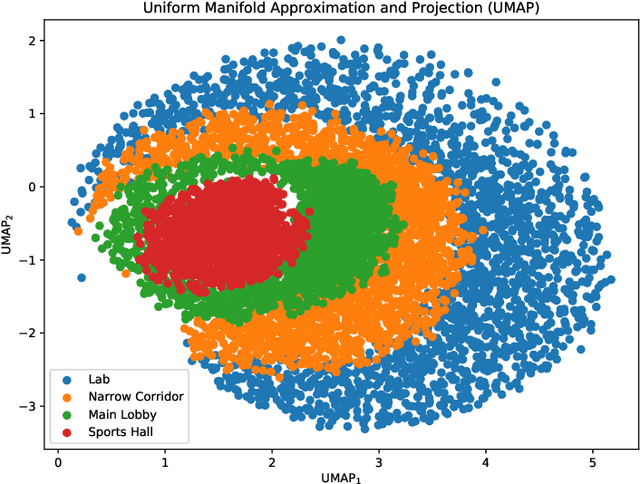
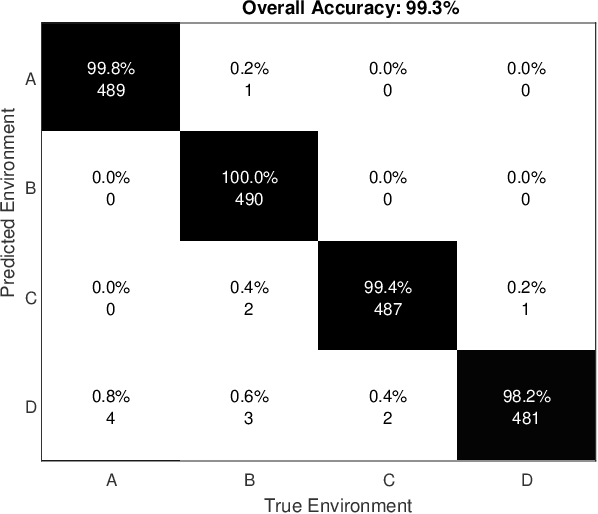
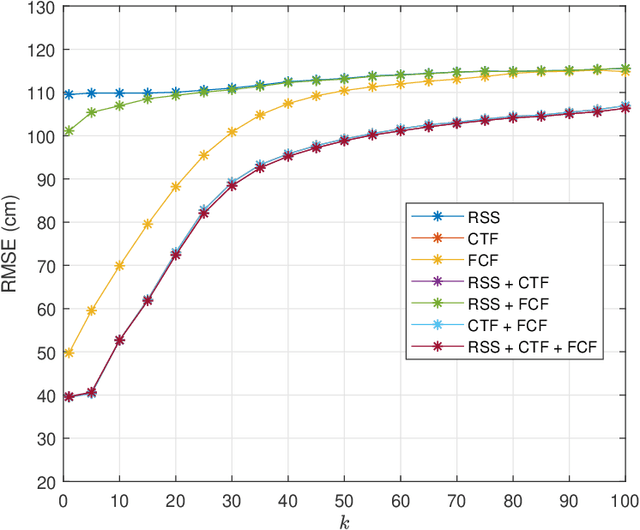
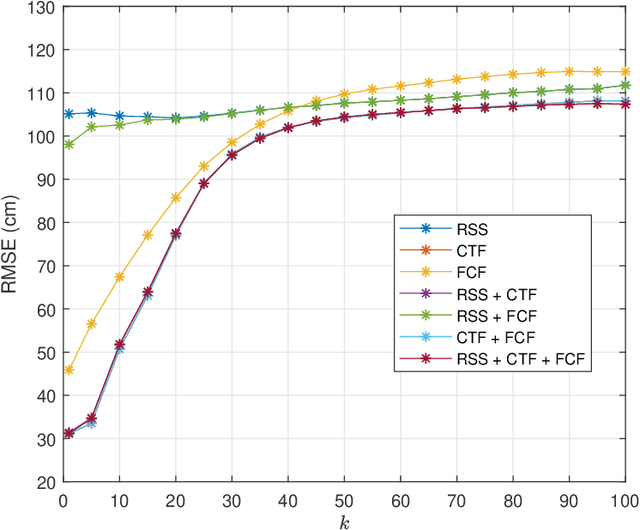
Evolving Internet-of-Things (IoT) applications often require the use of sensor-based indoor tracking and positioning, for which the performance is significantly improved by identifying the type of the surrounding indoor environment. This identification is of high importance since it leads to higher localization accuracy. This paper presents a novel method based on a cascaded two-stage machine learning approach for highly-accurate and robust localization in indoor environments using adaptive selection and combination of RF features. In the proposed method, machine learning is first used to identify the type of the surrounding indoor environment. Then, in the second stage, machine learning is employed to identify the most appropriate selection and combination of RF features that yield the highest localization accuracy. Analysis is based on k-Nearest Neighbor (k-NN) machine learning algorithm applied on a real dataset generated from practical measurements of the RF signal in realistic indoor environments. Received Signal Strength, Channel Transfer Function, and Frequency Coherence Function are the primary RF features being explored and combined. Numerical investigations demonstrate that prediction based on the concatenation of primary RF features enhanced significantly as the localization accuracy improved by at least 50% to more than 70%.