 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeL3iTC at the FinLLM Challenge Task: Quantization for Financial Text Classification & Summarization
Aug 06, 2024



This article details our participation (L3iTC) in the FinLLM Challenge Task 2024, focusing on two key areas: Task 1, financial text classification, and Task 2, financial text summarization. To address these challenges, we fine-tuned several large language models (LLMs) to optimize performance for each task. Specifically, we used 4-bit quantization and LoRA to determine which layers of the LLMs should be trained at a lower precision. This approach not only accelerated the fine-tuning process on the training data provided by the organizers but also enabled us to run the models on low GPU memory. Our fine-tuned models achieved third place for the financial classification task with an F1-score of 0.7543 and secured sixth place in the financial summarization task on the official test datasets.
Forecasting Four Business Cycle Phases Using Machine Learning: A Case Study of US and EuroZone
May 27, 2024



Understanding the business cycle is crucial for building economic stability, guiding business planning, and informing investment decisions. The business cycle refers to the recurring pattern of expansion and contraction in economic activity over time. Economic analysis is inherently complex, incorporating a myriad of factors (such as macroeconomic indicators, political decisions). This complexity makes it challenging to fully account for all variables when determining the current state of the economy and predicting its future trajectory in the upcoming months. The objective of this study is to investigate the capacity of machine learning models in automatically analyzing the state of the economic, with the goal of forecasting business phases (expansion, slowdown, recession and recovery) in the United States and the EuroZone. We compared three different machine learning approaches to classify the phases of the business cycle, and among them, the Multinomial Logistic Regression (MLR) achieved the best results. Specifically, MLR got the best results by achieving the accuracy of 65.25% (Top1) and 84.74% (Top2) for the EuroZone and 75% (Top1) and 92.14% (Top2) for the United States. These results demonstrate the potential of machine learning techniques to predict business cycles accurately, which can aid in making informed decisions in the fields of economics and finance.
Leveraging BERT Language Models for Multi-Lingual ESG Issue Identification
Sep 05, 2023



Environmental, Social, and Governance (ESG) has been used as a metric to measure the negative impacts and enhance positive outcomes of companies in areas such as the environment, society, and governance. Recently, investors have increasingly recognized the significance of ESG criteria in their investment choices, leading businesses to integrate ESG principles into their operations and strategies. The Multi-Lingual ESG Issue Identification (ML-ESG) shared task encompasses the classification of news documents into 35 distinct ESG issue labels. In this study, we explored multiple strategies harnessing BERT language models to achieve accurate classification of news documents across these labels. Our analysis revealed that the RoBERTa classifier emerged as one of the most successful approaches, securing the second-place position for the English test dataset, and sharing the fifth-place position for the French test dataset. Furthermore, our SVM-based binary model tailored for the Chinese language exhibited exceptional performance, earning the second-place rank on the test dataset.
Using contextual sentence analysis models to recognize ESG concepts
Jul 04, 2022


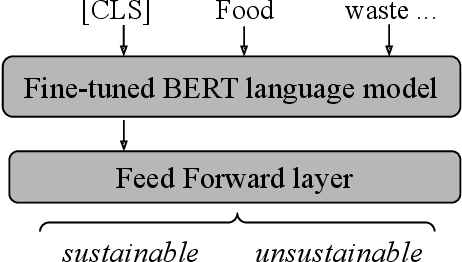
This paper summarizes the joint participation of the Trading Central Labs and the L3i laboratory of the University of La Rochelle on both sub-tasks of the Shared Task FinSim-4 evaluation campaign. The first sub-task aims to enrich the 'Fortia ESG taxonomy' with new lexicon entries while the second one aims to classify sentences to either 'sustainable' or 'unsustainable' with respect to ESG (Environment, Social and Governance) related factors. For the first sub-task, we proposed a model based on pre-trained Sentence-BERT models to project sentences and concepts in a common space in order to better represent ESG concepts. The official task results show that our system yields a significant performance improvement compared to the baseline and outperforms all other submissions on the first sub-task. For the second sub-task, we combine the RoBERTa model with a feed-forward multi-layer perceptron in order to extract the context of sentences and classify them. Our model achieved high accuracy scores (over 92%) and was ranked among the top 5 systems.
Contextual Sentence Analysis for the Sentiment Prediction on Financial Data
Dec 27, 2021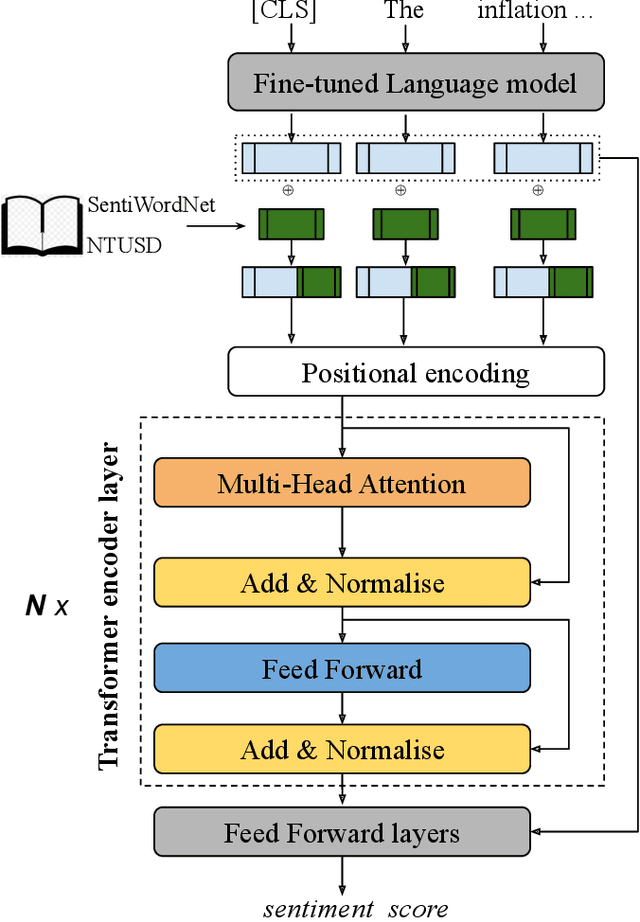
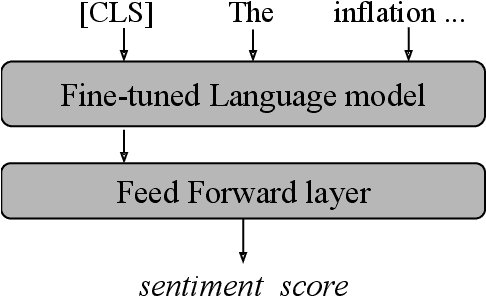

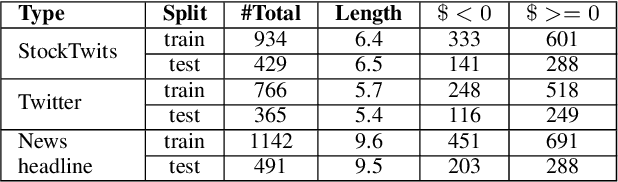
Newsletters and social networks can reflect the opinion about the market and specific stocks from the perspective of analysts and the general public on products and/or services provided by a company. Therefore, sentiment analysis of these texts can provide useful information to help investors trade in the market. In this paper, a hierarchical stack of Transformers model is proposed to identify the sentiment associated with companies and stocks, by predicting a score (of data type real) in a range between -1 and +1. Specifically, we fine-tuned a RoBERTa model to process headlines and microblogs and combined it with additional Transformer layers to process the sentence analysis with sentiment dictionaries to improve the sentiment analysis. We evaluated it on financial data released by SemEval-2017 task 5 and our proposition outperformed the best systems of SemEval-2017 task 5 and strong baselines. Indeed, the combination of contextual sentence analysis with the financial and general sentiment dictionaries provided useful information to our model and allowed it to generate more reliable sentiment scores.