 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Foundational Models and Simple Fusion for Multi-modal Physiological Signal Analysis
Dec 17, 2025Physiological signals such as electrocardiograms (ECG) and electroencephalograms (EEG) provide complementary insights into human health and cognition, yet multi-modal integration is challenging due to limited multi-modal labeled data, and modality-specific differences . In this work, we adapt the CBraMod encoder for large-scale self-supervised ECG pretraining, introducing a dual-masking strategy to capture intra- and inter-lead dependencies. To overcome the above challenges, we utilize a pre-trained CBraMod encoder for EEG and pre-train a symmetric ECG encoder, equipping each modality with a rich foundational representation. These representations are then fused via simple embedding concatenation, allowing the classification head to learn cross-modal interactions, together enabling effective downstream learning despite limited multi-modal supervision. Evaluated on emotion recognition, our approach achieves near state-of-the-art performance, demonstrating that carefully designed physiological encoders, even with straightforward fusion, substantially improve downstream performance. These results highlight the potential of foundation-model approaches to harness the holistic nature of physiological signals, enabling scalable, label-efficient, and generalizable solutions for healthcare and affective computing.
Choose Settings Carefully: Comparing Action Unit detection at Different Settings Using a Large-Scale Dataset
Nov 16, 2021

In this paper, we investigate the impact of some of the commonly used settings for (a) preprocessing face images, and (b) classification and training, on Action Unit (AU) detection performance and complexity. We use in our investigation a large-scale dataset, consisting of ~55K videos collected in the wild for participants watching commercial ads. The preprocessing settings include scaling the face to a fixed resolution, changing the color information (RGB to gray-scale), aligning the face, and cropping AU regions, while the classification and training settings include the kind of classifier (multi-label vs. binary) and the amount of data used for training models. To the best of our knowledge, no work had investigated the effect of those settings on AU detection. In our analysis we use CNNs as our baseline classification model.
Which CNNs and Training Settings to Choose for Action Unit Detection? A Study Based on a Large-Scale Dataset
Nov 16, 2021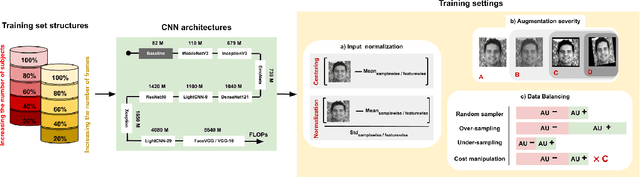
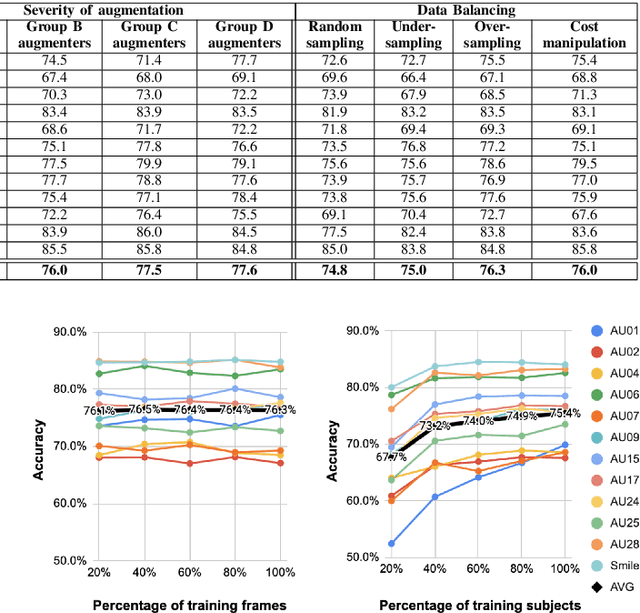
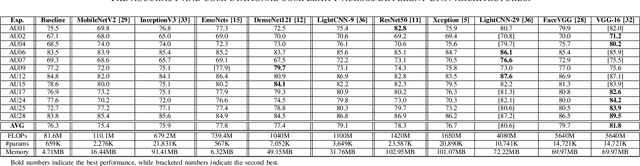
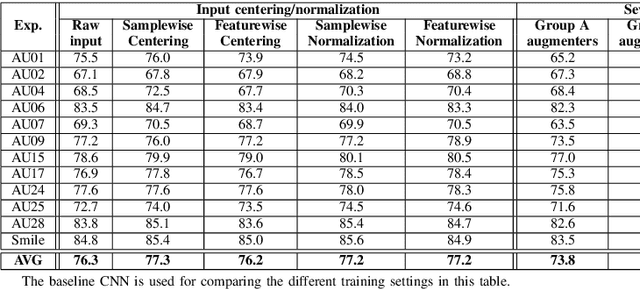
In this paper we explore the influence of some frequently used Convolutional Neural Networks (CNNs), training settings, and training set structures, on Action Unit (AU) detection. Specifically, we first compare 10 different shallow and deep CNNs in AU detection. Second, we investigate how the different training settings (i.e. centering/normalizing the inputs, using different augmentation severities, and balancing the data) impact the performance in AU detection. Third, we explore the effect of increasing the number of labelled subjects and frames in the training set on the AU detection performance. These comparisons provide the research community with useful tips about the choice of different CNNs and training settings in AU detection. In our analysis, we use a large-scale naturalistic dataset, consisting of ~55K videos captured in the wild. To the best of our knowledge, there is no work that had investigated the impact of such settings on a large-scale AU dataset.