 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArabic Morphosyntactic Tagging and Dependency Parsing with Large Language Models
Mar 17, 2026Large language models (LLMs) perform strongly on many NLP tasks, but their ability to produce explicit linguistic structure remains unclear. We evaluate instruction-tuned LLMs on two structured prediction tasks for Standard Arabic: morphosyntactic tagging and labeled dependency parsing. Arabic provides a challenging testbed due to its rich morphology and orthographic ambiguity, which create strong morphology-syntax interactions. We compare zero-shot prompting with retrieval-based in-context learning (ICL) using examples from Arabic treebanks. Results show that prompt design and demonstration selection strongly affect performance: proprietary models approach supervised baselines for feature-level tagging and become competitive with specialized dependency parsers. In raw-text settings, tokenization remains challenging, though retrieval-based ICL improves both parsing and tokenization. Our analysis highlights which aspects of Arabic morphosyntax and syntax LLMs capture reliably and which remain difficult.
Text-Independent Speaker Verification Based on Deep Neural Networks and Segmental Dynamic Time Warping
Jun 26, 2018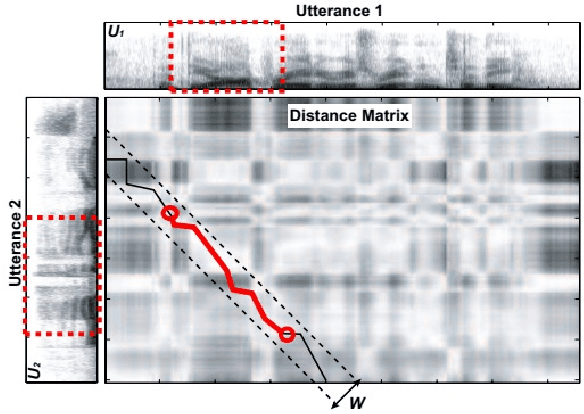
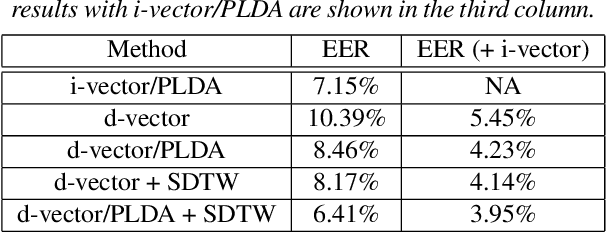
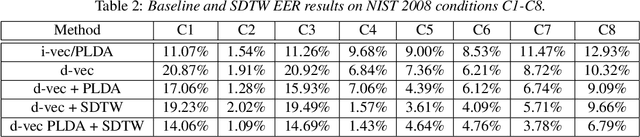
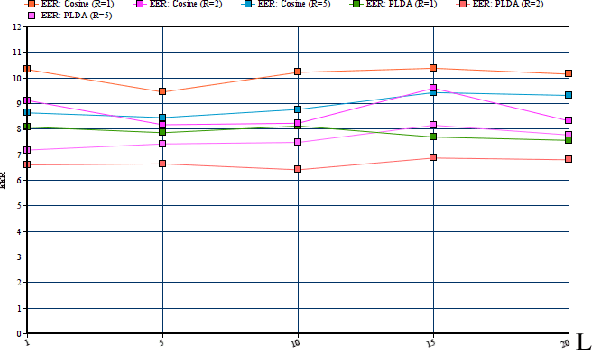
In this paper we present a new method for text-independent speaker verification that combines segmental dynamic time warping (SDTW) and the d-vector approach. The d-vectors, generated from a feed forward deep neural network trained to distinguish between speakers, are used as features to perform alignment and hence calculate the overall distance between the enrolment and test utterances.We present results on the NIST 2008 data set for speaker verification where the proposed method outperforms the conventional i-vector baseline with PLDA scores and outperforms d-vector approach with local distances based on cosine and PLDA scores. Also score combination with the i-vector/PLDA baseline leads to significant gains over both methods.