 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouC: Dual-Branch CLIP for Training-Free Open-Vocabulary Segmentation
Apr 27, 2026Open-vocabulary semantic segmentation requires assigning pixel-level semantic labels while supporting an open and unrestricted set of categories. Training-free CLIP-based approaches preserve strong zero-shot generalization but typically rely on a single inference mechanism, limiting their ability to jointly address unreliable local tokens and insufficient spatial coherence. We propose DouC, a training-free dual-branch CLIP framework that decomposes dense prediction into two complementary components. OG-CLIP improves patch-level reliability via lightweight, inference-time token gating, while FADE-CLIP injects external structural priors through proxy attention guided by frozen vision foundation models. The two branches are fused at the logit level, enabling local token reliability and structure-aware patch interactions to jointly influence final predictions, with optional instance-aware correction applied as post-processing. DouC introduces no additional learnable parameters, requires no retraining, and preserves CLIP's zero-shot generalization. Extensive experiments across eight benchmarks and multiple CLIP backbones demonstrate that DouC consistently outperforms prior training-free methods and scales favorably with model capacity.
Delta-LLaVA: Base-then-Specialize Alignment for Token-Efficient Vision-Language Models
Dec 21, 2025Multimodal Large Language Models (MLLMs) combine visual and textual representations to enable rich reasoning capabilities. However, the high computational cost of processing dense visual tokens remains a major bottleneck. A critical component in this pipeline is the visual projector, which bridges the vision encoder and the language model. Standard designs often employ a simple multi-layer perceptron for direct token mapping, but this approach scales poorly with high-resolution inputs, introducing significant redundancy. We present Delta-LLaVA, a token-efficient projector that employs a low-rank DeltaProjection to align multi-level vision features into a compact subspace before further interaction. On top of this base alignment, lightweight Transformer blocks act as specialization layers, capturing both global and local structure under constrained token budgets. Extensive experiments and ablations demonstrate that this base-then-specialize design yields consistent gains across multiple benchmarks with only 144 tokens, highlighting the importance of token formation prior to scaling interaction capacity. With Delta-LLaVA, inference throughput improves by up to 55%, while end-to-end training accelerates by nearly 4-5x in pretraining and over 1.5x in finetuning, highlighting the dual benefits of our design in both efficiency and scalability.
A Review of Knowledge Graph Completion
Aug 24, 2022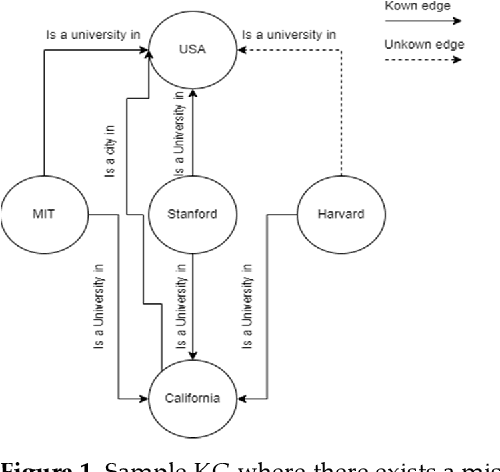



Information extraction methods proved to be effective at triple extraction from structured or unstructured data. The organization of such triples in the form of (head entity, relation, tail entity) is called the construction of Knowledge Graphs (KGs). Most of the current knowledge graphs are incomplete. In order to use KGs in downstream tasks, it is desirable to predict missing links in KGs. Different approaches have been recently proposed for representation learning of KGs by embedding both entities and relations into a low-dimensional vector space aiming to predict unknown triples based on previously visited triples. According to how the triples will be treated independently or dependently, we divided the task of knowledge graph completion into conventional and graph neural network representation learning and we discuss them in more detail. In conventional approaches, each triple will be processed independently and in GNN-based approaches, triples also consider their local neighborhood. View Full-Text
A Survey on Computational Intelligence-based Transfer Learning
Jun 17, 2022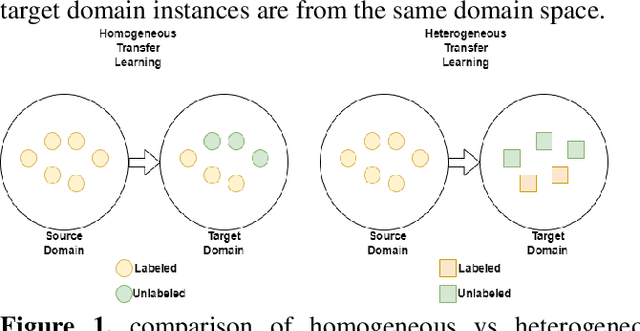
The goal of transfer learning (TL) is providing a framework for exploiting acquired knowledge from source to target data. Transfer learning approaches compared to traditional machine learning approaches are capable of modeling better data patterns from the current domain. However, vanilla TL needs performance improvements by using computational intelligence-based TL. This paper studies computational intelligence-based transfer learning techniques and categorizes them into neural network-based, evolutionary algorithm-based, swarm intelligence-based and fuzzy logic-based transfer learning.