 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Model for Spoken Language Recognition
Jan 04, 2022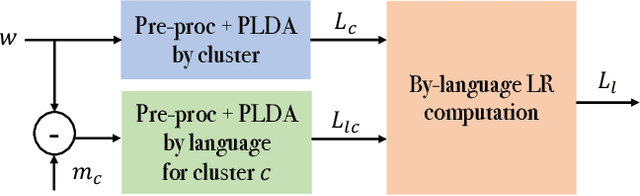
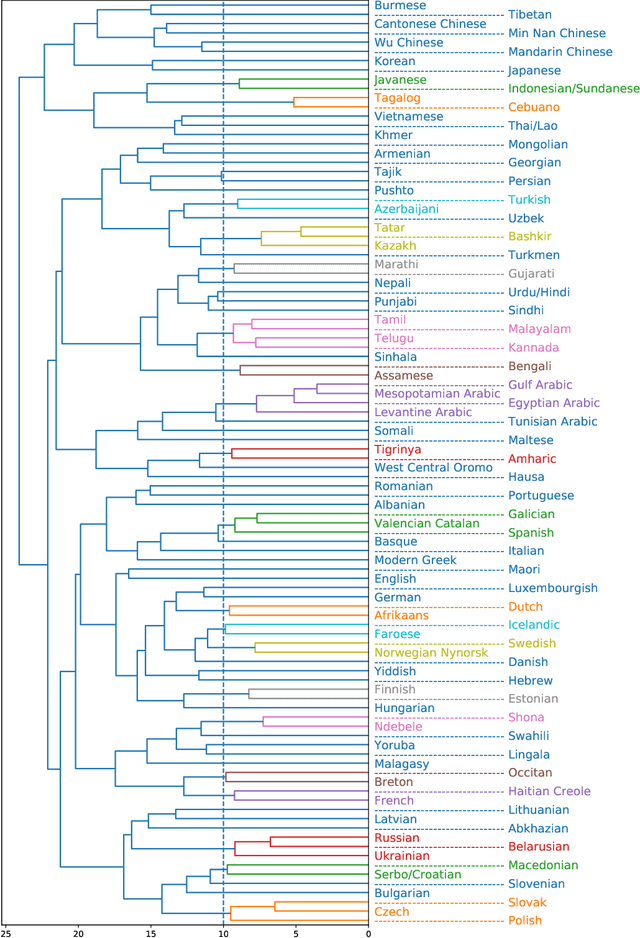
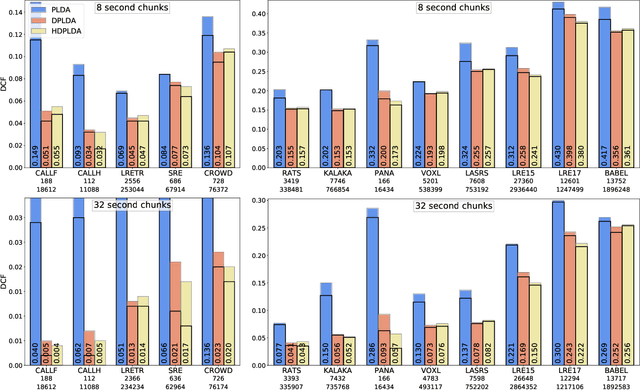
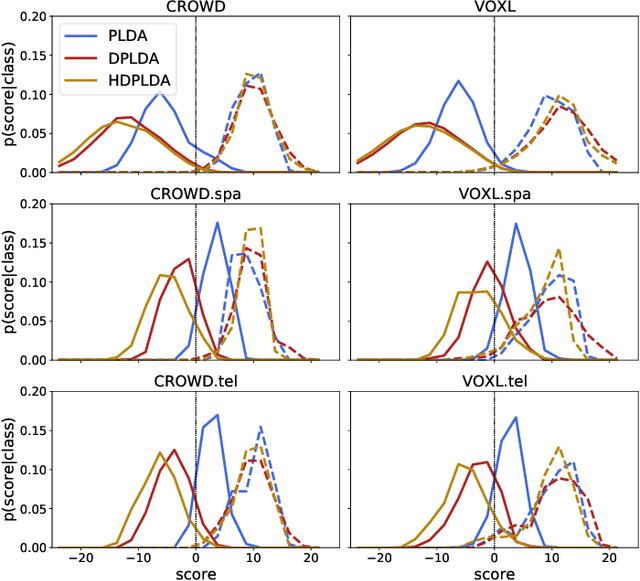
Spoken language recognition (SLR) refers to the automatic process used to determine the language present in a speech sample. SLR is an important task in its own right, for example, as a tool to analyze or categorize large amounts of multi-lingual data. Further, it is also an essential tool for selecting downstream applications in a work flow, for example, to chose appropriate speech recognition or machine translation models. SLR systems are usually composed of two stages, one where an embedding representing the audio sample is extracted and a second one which computes the final scores for each language. In this work, we approach the SLR task as a detection problem and implement the second stage as a probabilistic linear discriminant analysis (PLDA) model. We show that discriminative training of the PLDA parameters gives large gains with respect to the usual generative training. Further, we propose a novel hierarchical approach were two PLDA models are trained, one to generate scores for clusters of highly related languages and a second one to generate scores conditional to each cluster. The final language detection scores are computed as a combination of these two sets of scores. The complete model is trained discriminatively to optimize a cross-entropy objective. We show that this hierarchical approach consistently outperforms the non-hierarchical one for detection of highly related languages, in many cases by large margins. We train our systems on a collection of datasets including 100 languages and test them both on matched and mismatched conditions, showing that the gains are robust to condition mismatch.
A Speaker Verification Backend with Robust Performance across Conditions
Feb 02, 2021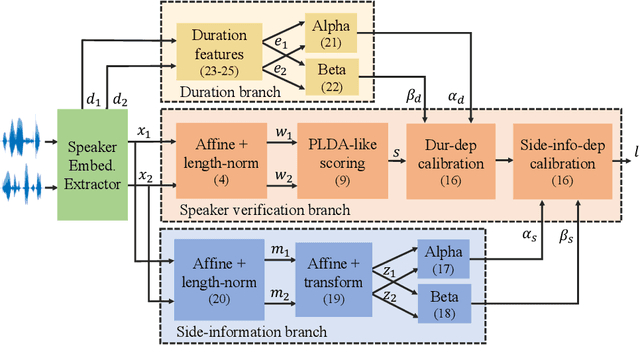
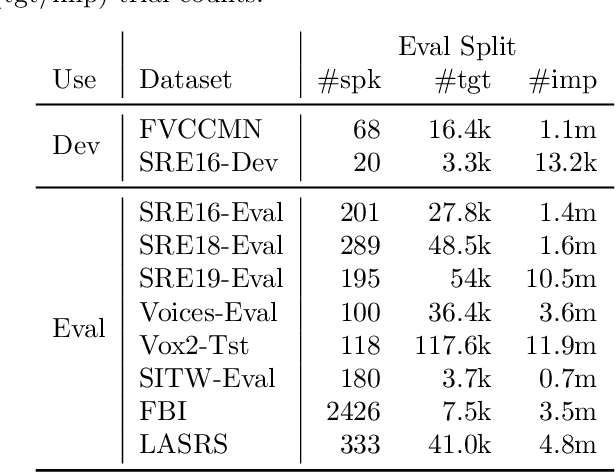
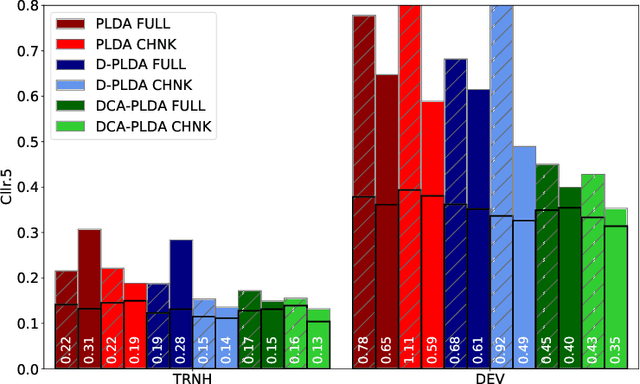
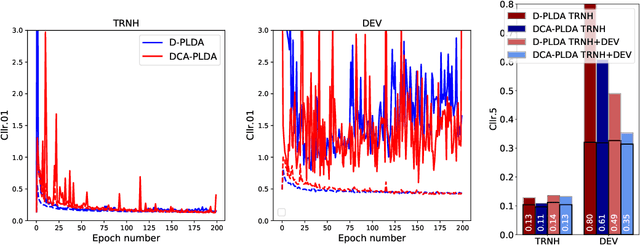
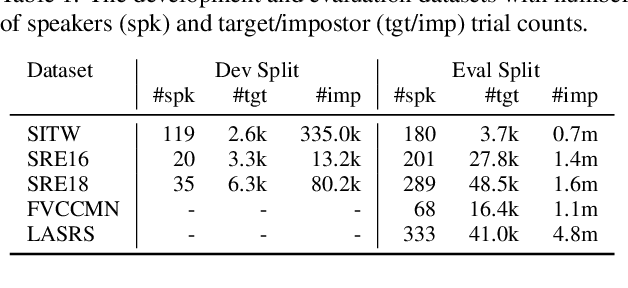
In this paper, we address the problem of speaker verification in conditions unseen or unknown during development. A standard method for speaker verification consists of extracting speaker embeddings with a deep neural network and processing them through a backend composed of probabilistic linear discriminant analysis (PLDA) and global logistic regression score calibration. This method is known to result in systems that work poorly on conditions different from those used to train the calibration model. We propose to modify the standard backend, introducing an adaptive calibrator that uses duration and other automatically extracted side-information to adapt to the conditions of the inputs. The backend is trained discriminatively to optimize binary cross-entropy. When trained on a number of diverse datasets that are labeled only with respect to speaker, the proposed backend consistently and, in some cases, dramatically improves calibration, compared to the standard PLDA approach, on a number of held-out datasets, some of which are markedly different from the training data. Discrimination performance is also consistently improved. We show that joint training of the PLDA and the adaptive calibrator is essential -- the same benefits cannot be achieved when freezing PLDA and fine-tuning the calibrator. To our knowledge, the results in this paper are the first evidence in the literature that it is possible to develop a speaker verification system with robust out-of-the-box performance on a large variety of conditions.
VoxSRC 2020: The Second VoxCeleb Speaker Recognition Challenge
Dec 12, 2020
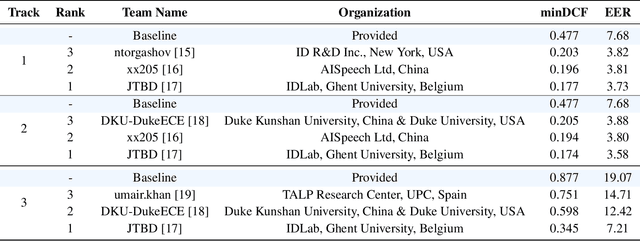

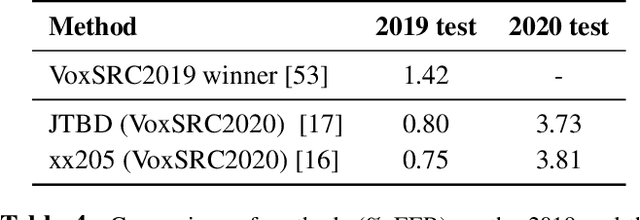
We held the second installment of the VoxCeleb Speaker Recognition Challenge in conjunction with Interspeech 2020. The goal of this challenge was to assess how well current speaker recognition technology is able to diarise and recognize speakers in unconstrained or `in the wild' data. It consisted of: (i) a publicly available speaker recognition and diarisation dataset from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a virtual public challenge and workshop held at Interspeech 2020. This paper outlines the challenge, and describes the baselines, methods used, and results. We conclude with a discussion of the progress over the first installment of the challenge.
Temporarily-Aware Context Modelling using Generative Adversarial Networks for Speech Activity Detection
Apr 02, 2020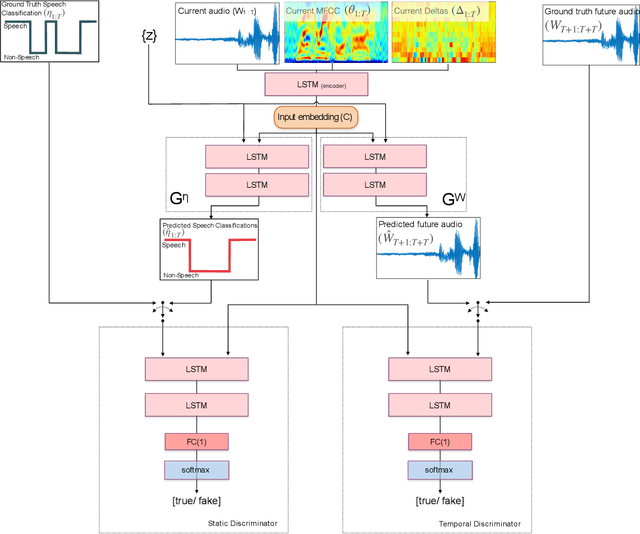
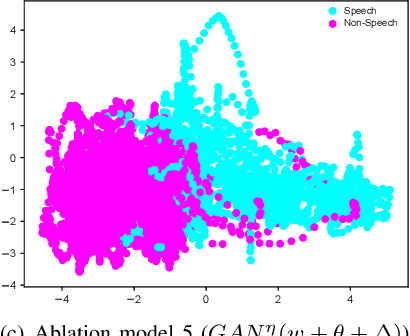

This paper presents a novel framework for Speech Activity Detection (SAD). Inspired by the recent success of multi-task learning approaches in the speech processing domain, we propose a novel joint learning framework for SAD. We utilise generative adversarial networks to automatically learn a loss function for joint prediction of the frame-wise speech/ non-speech classifications together with the next audio segment. In order to exploit the temporal relationships within the input signal, we propose a temporal discriminator which aims to ensure that the predicted signal is temporally consistent. We evaluate the proposed framework on multiple public benchmarks, including NIST OpenSAT' 17, AMI Meeting and HAVIC, where we demonstrate its capability to outperform state-of-the-art SAD approaches. Furthermore, our cross-database evaluations demonstrate the robustness of the proposed approach across different languages, accents, and acoustic environments.
A Speaker Verification Backend for Improved Calibration Performance across Varying Conditions
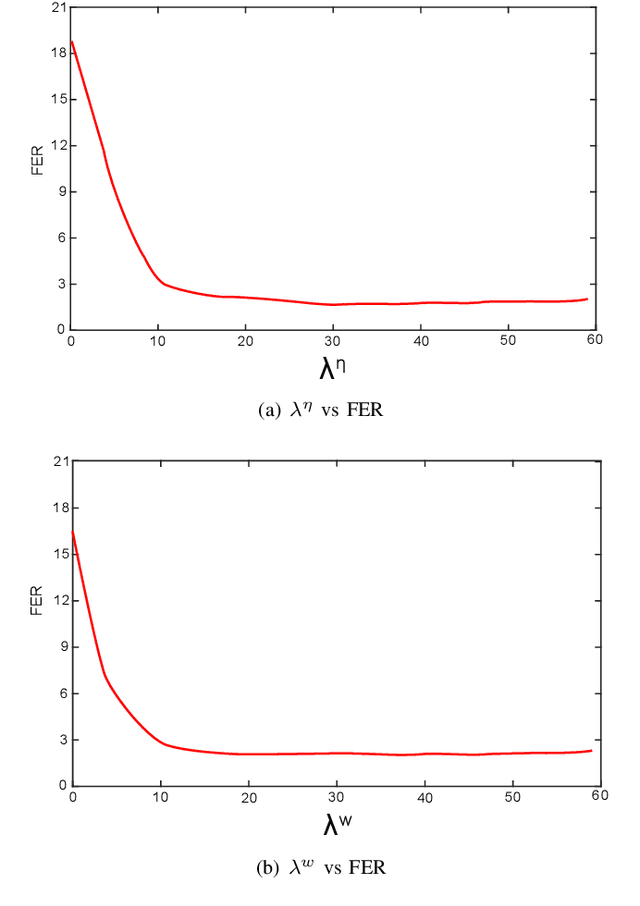
Feb 05, 2020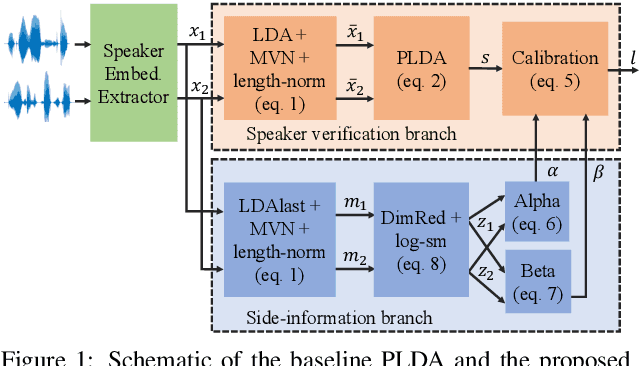
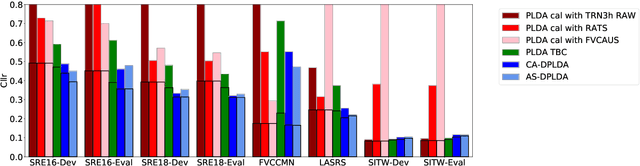
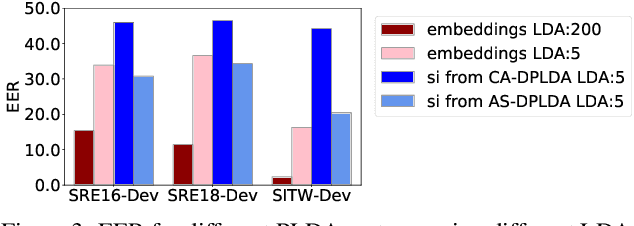
In a recent work, we presented a discriminative backend for speaker verification that achieved good out-of-the-box calibration performance on most tested conditions containing varying levels of mismatch to the training conditions. This backend mimics the standard PLDA-based backend process used in most current speaker verification systems, including the calibration stage. All parameters of the backend are jointly trained to optimize the binary cross-entropy for the speaker verification task. Calibration robustness is achieved by making the parameters of the calibration stage a function of vectors representing the conditions of the signal, which are extracted using a model trained to predict condition labels. In this work, we propose a simplified version of this backend where the vectors used to compute the calibration parameters are estimated within the backend, without the need for a condition prediction model. We show that this simplified method provides similar performance to the previously proposed method while being simpler to implement, and having less requirements on the training data. Further, we provide an analysis of different aspects of the method including the effect of initialization, the nature of the vectors used to compute the calibration parameters, and the effect that the random seed and the number of training epochs has on performance. We also compare the proposed method with the trial-based calibration (TBC) method that, to our knowledge, was the state-of-the-art for achieving good calibration across varying conditions. We show that the proposed method outperforms TBC while also being several orders of magnitude faster to run, comparable to the standard PLDA baseline.
VoxSRC 2019: The first VoxCeleb Speaker Recognition Challenge
Dec 05, 2019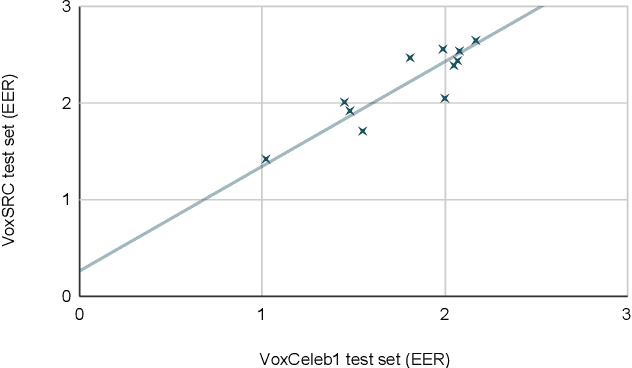

The VoxCeleb Speaker Recognition Challenge 2019 aimed to assess how well current speaker recognition technology is able to identify speakers in unconstrained or `in the wild' data. It consisted of: (i) a publicly available speaker recognition dataset from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and workshop held at Interspeech 2019 in Graz, Austria. This paper outlines the challenge and provides its baselines, results and discussions.
A discriminative condition-aware backend for speaker verification
Nov 26, 2019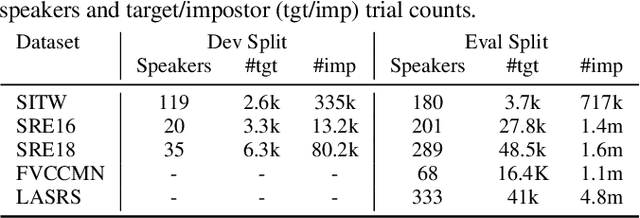
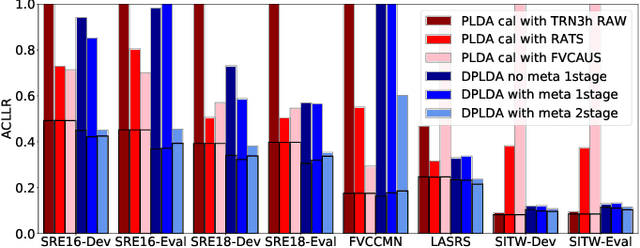
We present a scoring approach for speaker verification that mimics the standard PLDA-based backend process used in most current speaker verification systems. However, unlike the standard backends, all parameters of the model are jointly trained to optimize the binary cross-entropy for the speaker verification task. We further integrate the calibration stage inside the model, making the parameters of this stage depend on metadata vectors that represent the conditions of the signals. We show that the proposed backend has excellent out-of-the-box calibration performance on most of our test sets, making it an ideal approach for cases in which the test conditions are not known and development data is not available for training a domain-specific calibration model.
Semi-supervised acoustic model training for speech with code-switching
Oct 23, 2018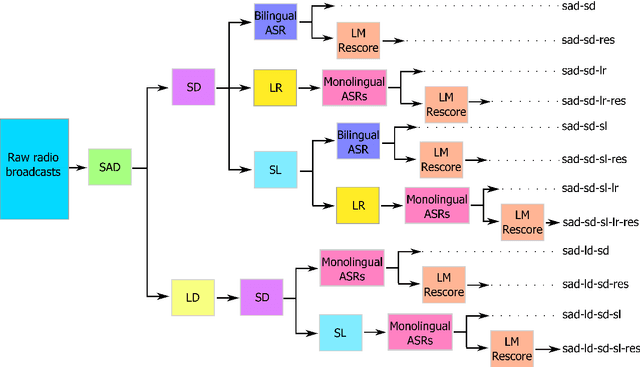
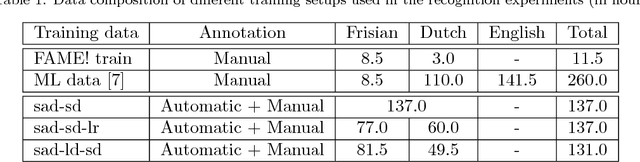

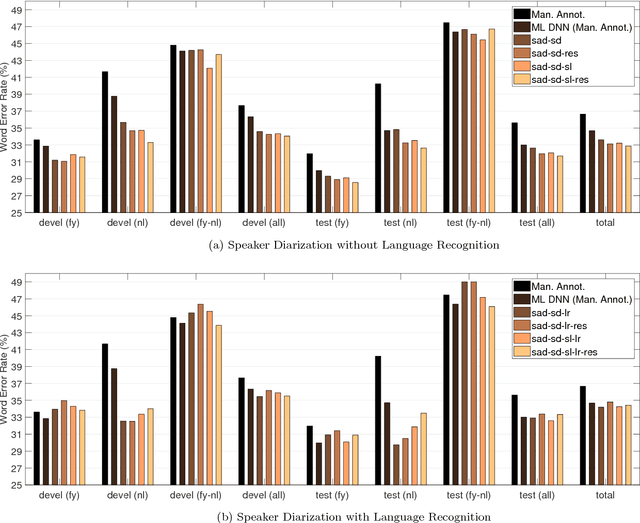
In the FAME! project, we aim to develop an automatic speech recognition (ASR) system for Frisian-Dutch code-switching (CS) speech extracted from the archives of a local broadcaster with the ultimate goal of building a spoken document retrieval system. Unlike Dutch, Frisian is a low-resourced language with a very limited amount of manually annotated speech data. In this paper, we describe several automatic annotation approaches to enable using of a large amount of raw bilingual broadcast data for acoustic model training in a semi-supervised setting. Previously, it has been shown that the best-performing ASR system is obtained by two-stage multilingual deep neural network (DNN) training using 11 hours of manually annotated CS speech (reference) data together with speech data from other high-resourced languages. We compare the quality of transcriptions provided by this bilingual ASR system with several other approaches that use a language recognition system for assigning language labels to raw speech segments at the front-end and using monolingual ASR resources for transcription. We further investigate automatic annotation of the speakers appearing in the raw broadcast data by first labeling with (pseudo) speaker tags using a speaker diarization system and then linking to the known speakers appearing in the reference data using a speaker recognition system. These speaker labels are essential for speaker-adaptive training in the proposed setting. We train acoustic models using the manually and automatically annotated data and run recognition experiments on the development and test data of the FAME! speech corpus to quantify the quality of the automatic annotations. The ASR and CS detection results demonstrate the potential of using automatic language and speaker tagging in semi-supervised bilingual acoustic model training.
Joint PLDA for Simultaneous Modeling of Two Factors
Mar 28, 2018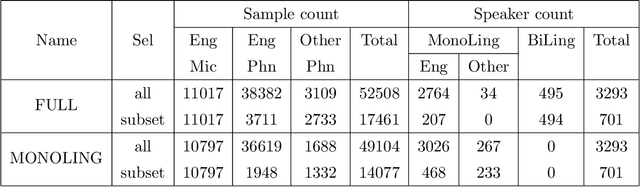
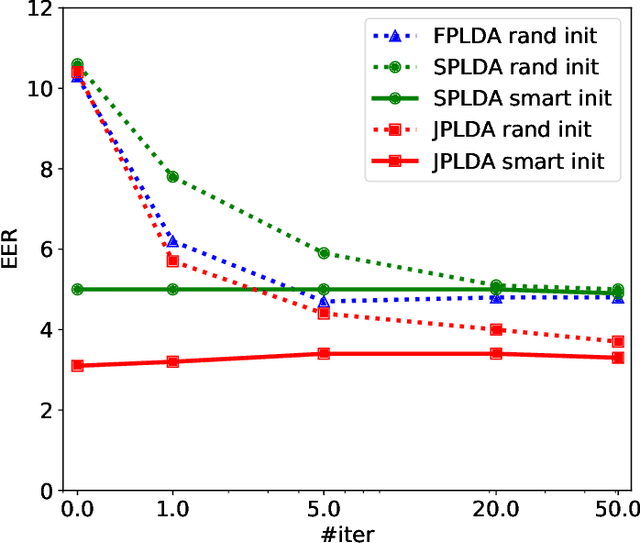
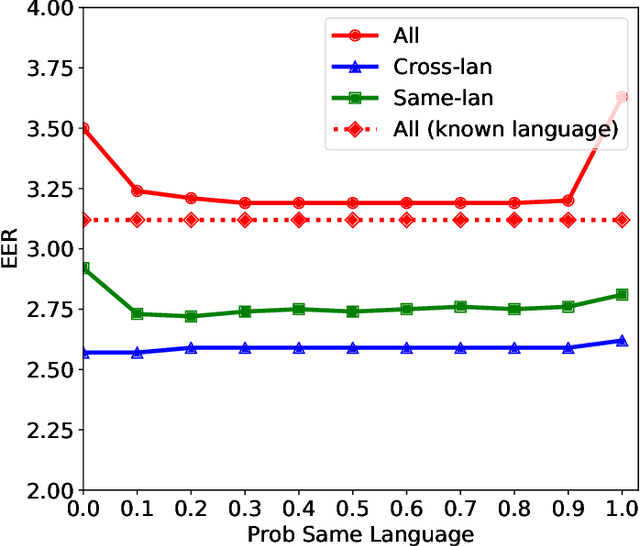
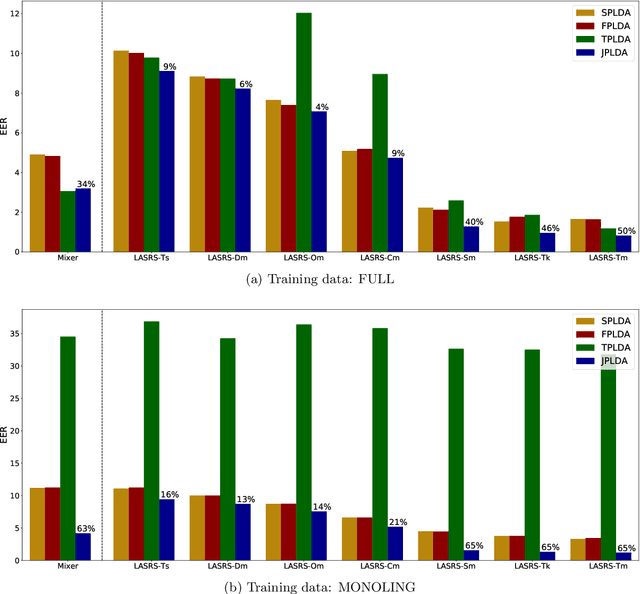
Probabilistic linear discriminant analysis (PLDA) is a method used for biometric problems like speaker or face recognition that models the variability of the samples using two latent variables, one that depends on the class of the sample and another one that is assumed independent across samples and models the within-class variability. In this work, we propose a generalization of PLDA that enables joint modeling of two sample-dependent factors: the class of interest and a nuisance condition. The approach does not change the basic form of PLDA but rather modifies the training procedure to consider the dependency across samples of the latent variable that models within-class variability. While the identity of the nuisance condition is needed during training, it is not needed during testing since we propose a scoring procedure that marginalizes over the corresponding latent variable. We show results on a multilingual speaker-verification task, where the language spoken is considered a nuisance condition. We show that the proposed joint PLDA approach leads to significant performance gains in this task for two different datasets, in particular when the training data contains mostly or only monolingual speakers.