 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality-Aware Decoding: Unifying Quality Estimation and Decoding
Feb 12, 2025



An emerging research direction in NMT involves the use of Quality Estimation (QE) models, which have demonstrated high correlations with human judgment and can enhance translations through Quality-Aware Decoding. Although several approaches have been proposed based on sampling multiple candidate translations, none have integrated these models directly into the decoding process. In this paper, we address this by proposing a novel token-level QE model capable of reliably scoring partial translations. We build a uni-directional QE model for this, as decoder models are inherently trained and efficient on partial sequences. We then present a decoding strategy that integrates the QE model for Quality-Aware decoding and demonstrate that the translation quality improves when compared to the N-best list re-ranking with state-of-the-art QE models (upto $1.39$ XCOMET-XXL $\uparrow$). Finally, we show that our approach provides significant benefits in document translation tasks, where the quality of N-best lists is typically suboptimal.
Post-edits Are Preferences Too
Oct 03, 2024



Preference Optimization (PO) techniques are currently one of the state of the art techniques for fine-tuning large language models (LLMs) on pairwise preference feedback from human annotators. However, in machine translation, this sort of feedback can be difficult to solicit. Additionally, Kreutzer et al. (2018) have shown that, for machine translation, pairwise preferences are less reliable than other forms of human feedback, such as 5-point ratings. We examine post-edits to see if they can be a source of reliable human preferences by construction. In PO, a human annotator is shown sequences $s_1$ and $s_2$ and asked for a preference judgment, %$s_1 > s_2$; while for post-editing, editors \emph{create} $s_1$ and know that it should be better than $s_2$. We attempt to use these implicit preferences for PO and show that it helps the model move towards post-edit-like hypotheses and away from machine translation-like hypotheses. Furthermore, we show that best results are obtained by pre-training the model with supervised fine-tuning (SFT) on post-edits in order to promote post-edit-like hypotheses to the top output ranks.
Plug, Play, and Fuse: Zero-Shot Joint Decoding via Word-Level Re-ranking Across Diverse Vocabularies
Aug 21, 2024



Recent advancements in NLP have resulted in models with specialized strengths, such as processing multimodal inputs or excelling in specific domains. However, real-world tasks, like multimodal translation, often require a combination of these strengths, such as handling both translation and image processing. While individual translation and vision models are powerful, they typically lack the ability to perform both tasks in a single system. Combining these models poses challenges, particularly due to differences in their vocabularies, which limit the effectiveness of traditional ensemble methods to post-generation techniques like N-best list re-ranking. In this work, we propose a novel zero-shot ensembling strategy that allows for the integration of different models during the decoding phase without the need for additional training. Our approach re-ranks beams during decoding by combining scores at the word level, using heuristics to predict when a word is completed. We demonstrate the effectiveness of this method in machine translation scenarios, showing that it enables the generation of translations that are both speech- and image-aware while also improving overall translation quality\footnote{We will release the code upon paper acceptance.}.
Prompting Large Language Models with Human Error Markings for Self-Correcting Machine Translation
Jun 04, 2024



While large language models (LLMs) pre-trained on massive amounts of unpaired language data have reached the state-of-the-art in machine translation (MT) of general domain texts, post-editing (PE) is still required to correct errors and to enhance term translation quality in specialized domains. In this paper we present a pilot study of enhancing translation memories (TM) produced by PE (source segments, machine translations, and reference translations, henceforth called PE-TM) for the needs of correct and consistent term translation in technical domains. We investigate a light-weight two-step scenario where, at inference time, a human translator marks errors in the first translation step, and in a second step a few similar examples are extracted from the PE-TM to prompt an LLM. Our experiment shows that the additional effort of augmenting translations with human error markings guides the LLM to focus on a correction of the marked errors, yielding consistent improvements over automatic PE (APE) and MT from scratch.
Contextual Refinement of Translations: Large Language Models for Sentence and Document-Level Post-Editing
Oct 23, 2023



Large Language Models (LLM's) have demonstrated considerable success in various Natural Language Processing tasks, but they have yet to attain state-of-the-art performance in Neural Machine Translation (NMT). Nevertheless, their significant performance in tasks demanding a broad understanding and contextual processing shows their potential for translation. To exploit these abilities, we investigate using LLM's for MT and explore recent parameter-efficient fine-tuning techniques. Surprisingly, our initial experiments find that fine-tuning for translation purposes even led to performance degradation. To overcome this, we propose an alternative approach: adapting LLM's as Automatic Post-Editors (APE) rather than direct translators. Building on the LLM's exceptional ability to process and generate lengthy sequences, we also propose extending our approach to document-level translation. We show that leveraging Low-Rank-Adapter fine-tuning for APE can yield significant improvements across both sentence and document-level metrics while generalizing to out-of-domain data. Most notably, we achieve a state-of-the-art accuracy rate of 89\% on the ContraPro test set, which specifically assesses the model's ability to resolve pronoun ambiguities when translating from English to German. Lastly, we investigate a practical scenario involving manual post-editing for document-level translation, where reference context is made available. Here, we demonstrate that leveraging human corrections can significantly reduce the number of edits required for subsequent translations\footnote{Interactive Demo for integrating manual feedback can be found \href{https://huggingface.co/spaces/skoneru/contextual_refinement_ende}{here}}
Enhancing Supervised Learning with Contrastive Markings in Neural Machine Translation Training
Jul 17, 2023Supervised learning in Neural Machine Translation (NMT) typically follows a teacher forcing paradigm where reference tokens constitute the conditioning context in the model's prediction, instead of its own previous predictions. In order to alleviate this lack of exploration in the space of translations, we present a simple extension of standard maximum likelihood estimation by a contrastive marking objective. The additional training signals are extracted automatically from reference translations by comparing the system hypothesis against the reference, and used for up/down-weighting correct/incorrect tokens. The proposed new training procedure requires one additional translation pass over the training set per epoch, and does not alter the standard inference setup. We show that training with contrastive markings yields improvements on top of supervised learning, and is especially useful when learning from postedits where contrastive markings indicate human error corrections to the original hypotheses. Code is publicly released.
A parallel evaluation data set of software documentation with document structure annotation
Aug 11, 2020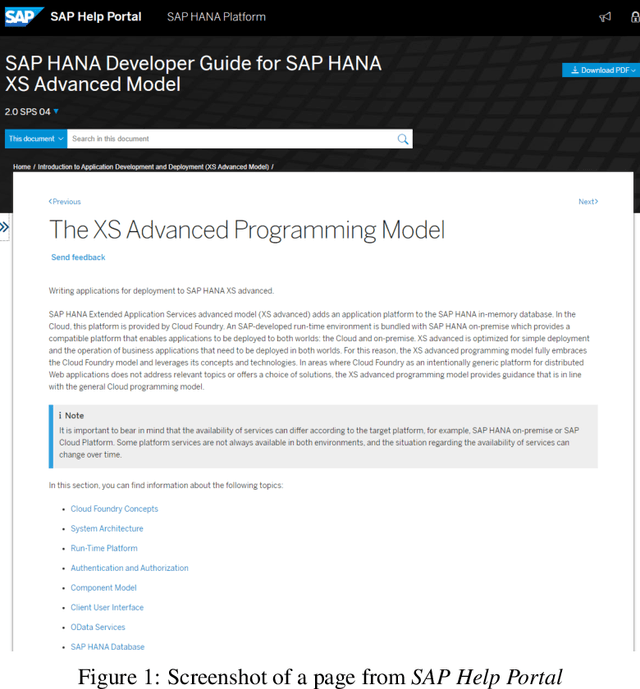
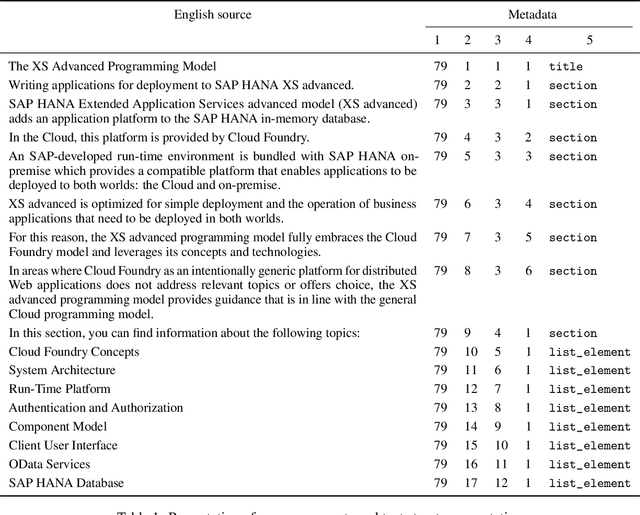
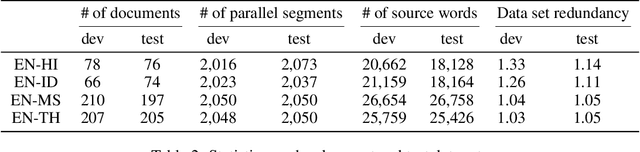
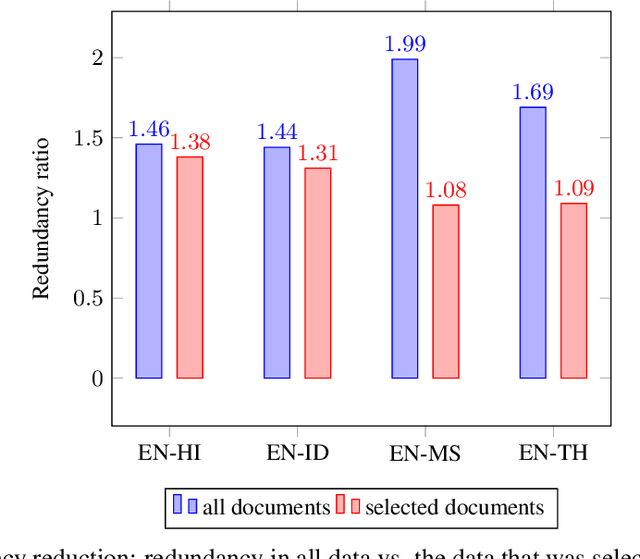
This paper accompanies the software documentation data set for machine translation, a parallel evaluation data set of data originating from the SAP Help Portal, that we release to the machine translation community for research purposes. It offers the possibility to tune and evaluate machine translation systems in the domain of corporate software documentation and contributes to the availability of a wider range of evaluation scenarios. The data set comprises of the language pairs English to Hindi, Indonesian, Malay and Thai, and thus also increases the test coverage for the many low-resource language pairs. Unlike most evaluation data sets that consist of plain parallel text, the segments in this data set come with additional metadata that describes structural information of the document context. We provide insights into the origin and creation, the particularities and characteristics of the data set.