 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial nets with perceptual losses for text-to-image synthesis
Aug 30, 2017
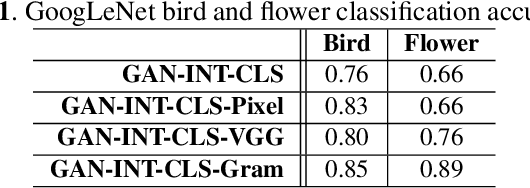
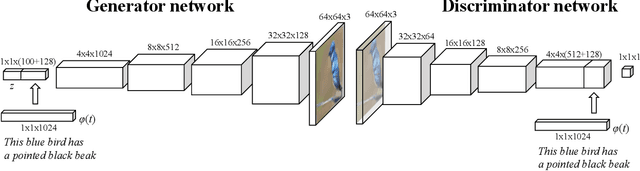

Recent approaches in generative adversarial networks (GANs) can automatically synthesize realistic images from descriptive text. Despite the overall fair quality, the generated images often expose visible flaws that lack structural definition for an object of interest. In this paper, we aim to extend state of the art for GAN-based text-to-image synthesis by improving perceptual quality of generated images. Differentiated from previous work, our synthetic image generator optimizes on perceptual loss functions that measure pixel, feature activation, and texture differences against a natural image. We present visually more compelling synthetic images of birds and flowers generated from text descriptions in comparison to some of the most prominent existing work.
Multimodal Sparse Coding for Event Detection
May 17, 2016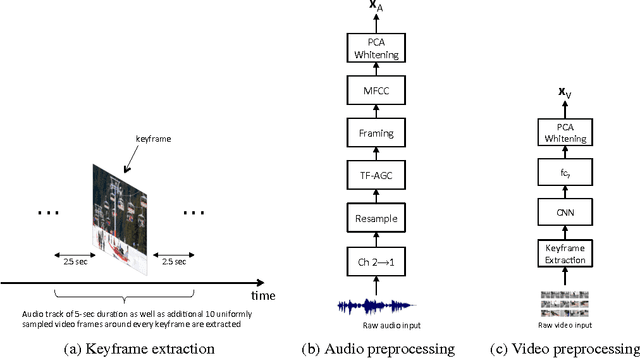
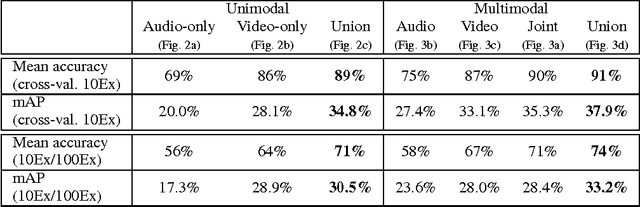
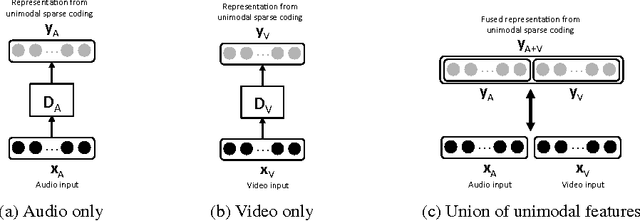
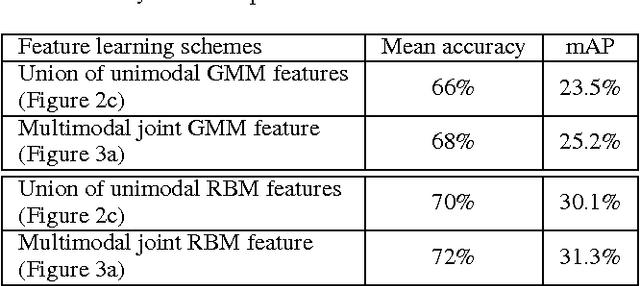
Unsupervised feature learning methods have proven effective for classification tasks based on a single modality. We present multimodal sparse coding for learning feature representations shared across multiple modalities. The shared representations are applied to multimedia event detection (MED) and evaluated in comparison to unimodal counterparts, as well as other feature learning methods such as GMM supervectors and sparse RBM. We report the cross-validated classification accuracy and mean average precision of the MED system trained on features learned from our unimodal and multimodal settings for a subset of the TRECVID MED 2014 dataset.
Multimodal sparse representation learning and applications
Mar 02, 2016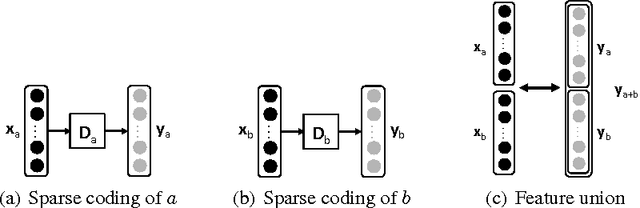
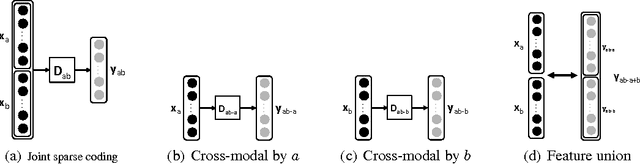

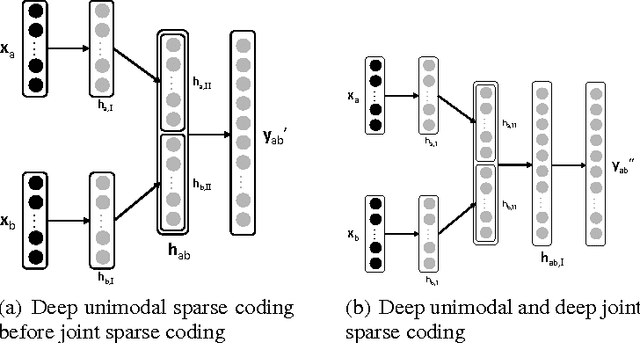
Unsupervised methods have proven effective for discriminative tasks in a single-modality scenario. In this paper, we present a multimodal framework for learning sparse representations that can capture semantic correlation between modalities. The framework can model relationships at a higher level by forcing the shared sparse representation. In particular, we propose the use of joint dictionary learning technique for sparse coding and formulate the joint representation for concision, cross-modal representations (in case of a missing modality), and union of the cross-modal representations. Given the accelerated growth of multimodal data posted on the Web such as YouTube, Wikipedia, and Twitter, learning good multimodal features is becoming increasingly important. We show that the shared representations enabled by our framework substantially improve the classification performance under both unimodal and multimodal settings. We further show how deep architectures built on the proposed framework are effective for the case of highly nonlinear correlations between modalities. The effectiveness of our approach is demonstrated experimentally in image denoising, multimedia event detection and retrieval on the TRECVID dataset (audio-video), category classification on the Wikipedia dataset (image-text), and sentiment classification on PhotoTweet (image-text).