 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Humans Growl and Birds Speak: High-Fidelity Voice Conversion from Human to Animal and Designed Sounds
May 30, 2025Human to non-human voice conversion (H2NH-VC) transforms human speech into animal or designed vocalizations. Unlike prior studies focused on dog-sounds and 16 or 22.05kHz audio transformation, this work addresses a broader range of non-speech sounds, including natural sounds (lion-roars, birdsongs) and designed voice (synthetic growls). To accomodate generation of diverse non-speech sounds and 44.1kHz high-quality audio transformation, we introduce a preprocessing pipeline and an improved CVAE-based H2NH-VC model, both optimized for human and non-human voices. Experimental results showed that the proposed method outperformed baselines in quality, naturalness, and similarity MOS, achieving effective voice conversion across diverse non-human timbres. Demo samples are available at https://nc-ai.github.io/speech/publications/nonhuman-vc/
UniTTS: Residual Learning of Unified Embedding Space for Speech Style Control
Jun 21, 2021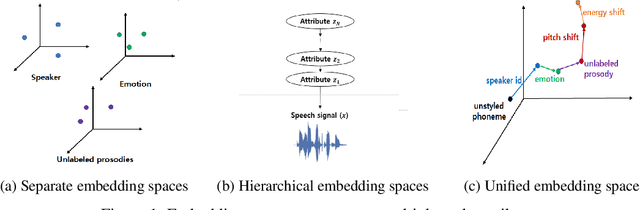
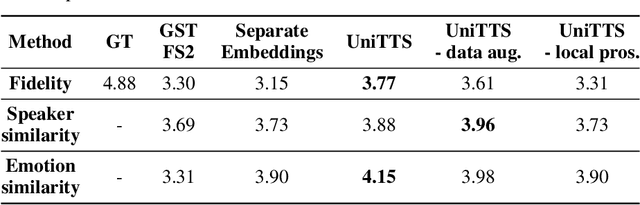
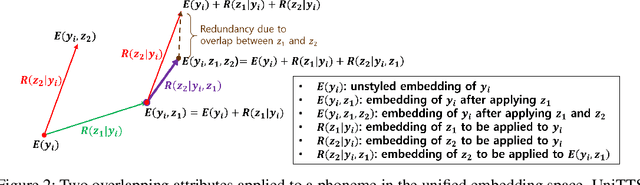

We propose a novel high-fidelity expressive speech synthesis model, UniTTS, that learns and controls overlapping style attributes avoiding interference. UniTTS represents multiple style attributes in a single unified embedding space by the residuals between the phoneme embeddings before and after applying the attributes. The proposed method is especially effective in controlling multiple attributes that are difficult to separate cleanly, such as speaker ID and emotion, because it minimizes redundancy when adding variance in speaker ID and emotion, and additionally, predicts duration, pitch, and energy based on the speaker ID and emotion. In experiments, the visualization results exhibit that the proposed methods learned multiple attributes harmoniously in a manner that can be easily separated again. As well, UniTTS synthesized high-fidelity speech signals controlling multiple style attributes. The synthesized speech samples are presented at https://jackson-kang.github.io/paper_works/UniTTS/demos.
Fast DCTTS: Efficient Deep Convolutional Text-to-Speech
Apr 01, 2021
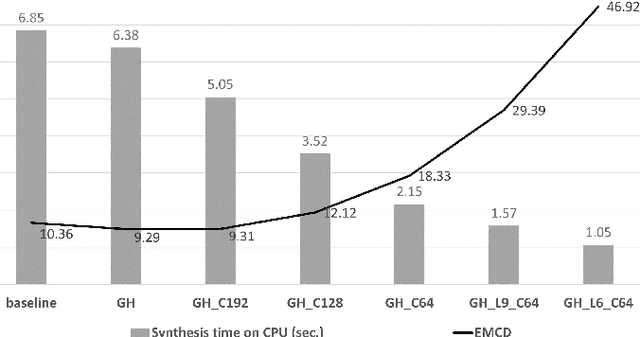
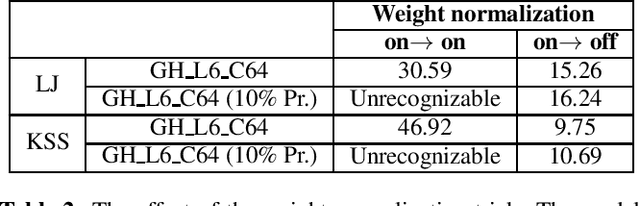
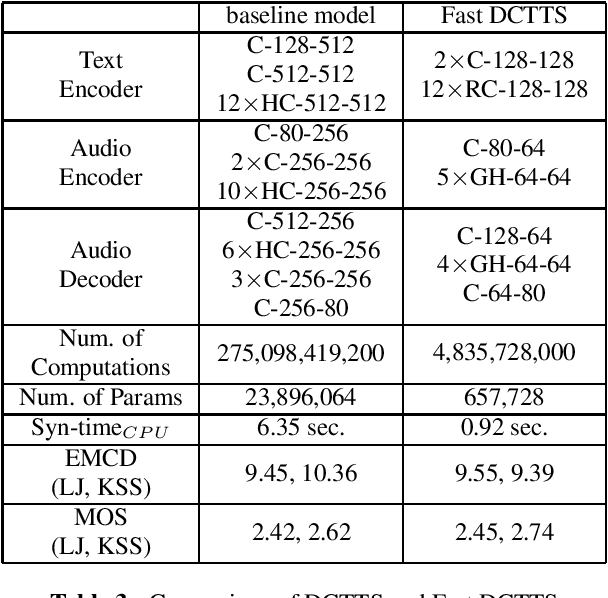
We propose an end-to-end speech synthesizer, Fast DCTTS, that synthesizes speech in real time on a single CPU thread. The proposed model is composed of a carefully-tuned lightweight network designed by applying multiple network reduction and fidelity improvement techniques. In addition, we propose a novel group highway activation that can compromise between computational efficiency and the regularization effect of the gating mechanism. As well, we introduce a new metric called Elastic mel-cepstral distortion (EMCD) to measure the fidelity of the output mel-spectrogram. In experiments, we analyze the effect of the acceleration techniques on speed and speech quality. Compared with the baseline model, the proposed model exhibits improved MOS from 2.62 to 2.74 with only 1.76% computation and 2.75% parameters. The speed on a single CPU thread was improved by 7.45 times, which is fast enough to produce mel-spectrogram in real time without GPU.