 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the dynamic properties and motion reproducibility of a small upper-body humanoid robot with 13-DOF pneumatic actuation for data-driven control
Mar 16, 2026Pneumatically-actuated anthropomorphic robots with high degrees of freedom (DOF) offer significant potential for physical human-robot interaction. However, precise control of pneumatic actuators is challenging due to their inherent nonlinearities. This paper presents the development of a compact 13-DOF upper-body humanoid robot. To assess the feasibility of an effective controller, we first investigate its key dynamic properties, such as actuation time delays, and confirm that the system exhibits highly reproducible behavior. Leveraging this reproducibility, we implement a preliminary data-driven controller for a 4-DOF arm subsystem based on a multilayer perceptron with explicit time delay compensation. The network was trained on random movement data to generate pressure commands for tracking arbitrary trajectories. Comparative evaluations with a traditional PID controller demonstrate superior trajectory tracking performance, highlighting the potential of data-driven approaches for controlling complex, high-DOF pneumatic robots.
Oscillations enhance time-series prediction in reservoir computing with feedback
Jun 05, 2024Reservoir computing, a machine learning framework used for modeling the brain, can predict temporal data with little observations and minimal computational resources. However, it is difficult to accurately reproduce the long-term target time series because the reservoir system becomes unstable. This predictive capability is required for a wide variety of time-series processing, including predictions of motor timing and chaotic dynamical systems. This study proposes oscillation-driven reservoir computing (ODRC) with feedback, where oscillatory signals are fed into a reservoir network to stabilize the network activity and induce complex reservoir dynamics. The ODRC can reproduce long-term target time series more accurately than conventional reservoir computing methods in a motor timing and chaotic time-series prediction tasks. Furthermore, it generates a time series similar to the target in the unexperienced period, that is, it can learn the abstract generative rules from limited observations. Given these significant improvements made by the simple and computationally inexpensive implementation, the ODRC would serve as a practical model of various time series data. Moreover, we will discuss biological implications of the ODRC, considering it as a model of neural oscillations and their cerebellar processors.
Affordance Blending Networks
Apr 24, 2024



Affordances, a concept rooted in ecological psychology and pioneered by James J. Gibson, have emerged as a fundamental framework for understanding the dynamic relationship between individuals and their environments. Expanding beyond traditional perceptual and cognitive paradigms, affordances represent the inherent effect and action possibilities that objects offer to the agents within a given context. As a theoretical lens, affordances bridge the gap between effect and action, providing a nuanced understanding of the connections between agents' actions on entities and the effect of these actions. In this study, we propose a model that unifies object, action and effect into a single latent representation in a common latent space that is shared between all affordances that we call the affordance space. Using this affordance space, our system is able to generate effect trajectories when action and object are given and is able to generate action trajectories when effect trajectories and objects are given. In the experiments, we showed that our model does not learn the behavior of each object but it learns the affordance relations shared by the objects that we call equivalences. In addition to simulated experiments, we showed that our model can be used for direct imitation in real world cases. We also propose affordances as a base for Cross Embodiment transfer to link the actions of different robots. Finally, we introduce selective loss as a solution that allows valid outputs to be generated for indeterministic model inputs.
Correspondence learning between morphologically different robots through task demonstrations
Oct 20, 2023



We observe a large variety of robots in terms of their bodies, sensors, and actuators. Given the commonalities in the skill sets, teaching each skill to each different robot independently is inefficient and not scalable when the large variety in the robotic landscape is considered. If we can learn the correspondences between the sensorimotor spaces of different robots, we can expect a skill that is learned in one robot can be more directly and easily transferred to the other robots. In this paper, we propose a method to learn correspondences between robots that have significant differences in their morphologies: a fixed-based manipulator robot with joint control and a differential drive mobile robot. For this, both robots are first given demonstrations that achieve the same tasks. A common latent representation is formed while learning the corresponding policies. After this initial learning stage, the observation of a new task execution by one robot becomes sufficient to generate a latent space representation pertaining to the other robot to achieve the same task. We verified our system in a set of experiments where the correspondence between two simulated robots is learned (1) when the robots need to follow the same paths to achieve the same task, (2) when the robots need to follow different trajectories to achieve the same task, and (3) when complexities of the required sensorimotor trajectories are different for the robots considered. We also provide a proof-of-the-concept realization of correspondence learning between a real manipulator robot and a simulated mobile robot.
Bimanual rope manipulation skill synthesis through context dependent correction policy learning from human demonstration
Sep 28, 2022
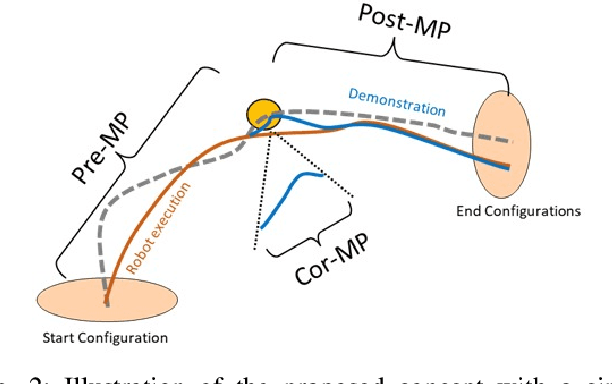
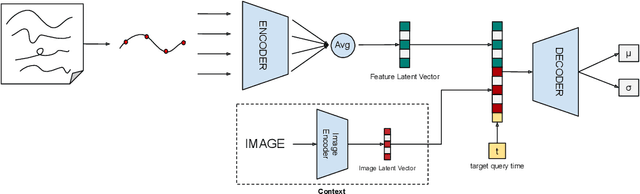

Learning from demonstration (LfD) provides a convenient means to equip robots with dexterous skills when demonstration can be obtained in robot intrinsic coordinates. However, the problem of compounding errors in long and complex skills reduces its wide deployment. Since most such complex skills are composed of smaller movements that are combined, considering the target skill as a sequence of compact motor primitives seems reasonable. Here the problem that needs to be tackled is to ensure that a motor primitive ends in a state that allows the successful execution of the subsequent primitive. In this study, we focus on this problem by proposing to learn an explicit correction policy when the expected transition state between primitives is not achieved. The correction policy is itself learned via behavior cloning by the use of a state-of-the-art movement primitive learning architecture, Conditional Neural Motor Primitives (CNMPs). The learned correction policy is then able to produce diverse movement trajectories in a context dependent way. The advantage of the proposed system over learning the complete task as a single action is shown with a table-top setup in simulation, where an object has to be pushed through a corridor in two steps. Then, the applicability of the proposed method to bi-manual knotting in the real world is shown by equipping an upper-body humanoid robot with the skill of making knots over a bar in 3D space. The experiments show that the robot can perform successful knotting even when the faced correction cases are not part of the human demonstration set.
High-level Features for Resource Economy and Fast Learning in Skill Transfer
Jun 18, 2021Abstraction is an important aspect of intelligence which enables agents to construct robust representations for effective decision making. In the last decade, deep networks are proven to be effective due to their ability to form increasingly complex abstractions. However, these abstractions are distributed over many neurons, making the re-use of a learned skill costly. Previous work either enforced formation of abstractions creating a designer bias, or used a large number of neural units without investigating how to obtain high-level features that may more effectively capture the source task. For avoiding designer bias and unsparing resource use, we propose to exploit neural response dynamics to form compact representations to use in skill transfer. For this, we consider two competing methods based on (1) maximum information compression principle and (2) the notion that abstract events tend to generate slowly changing signals, and apply them to the neural signals generated during task execution. To be concrete, in our simulation experiments, we either apply principal component analysis (PCA) or slow feature analysis (SFA) on the signals collected from the last hidden layer of a deep network while it performs a source task, and use these features for skill transfer in a new target task. We compare the generalization performance of these alternatives with the baselines of skill transfer with full layer output and no-transfer settings. Our results show that SFA units are the most successful for skill transfer. SFA as well as PCA, incur less resources compared to usual skill transfer, whereby many units formed show a localized response reflecting end-effector-obstacle-goal relations. Finally, SFA units with lowest eigenvalues resembles symbolic representations that highly correlate with high-level features such as joint angles which might be thought of precursors for fully symbolic systems.
On the weight and density bounds of polynomial threshold functions
Jul 06, 2020
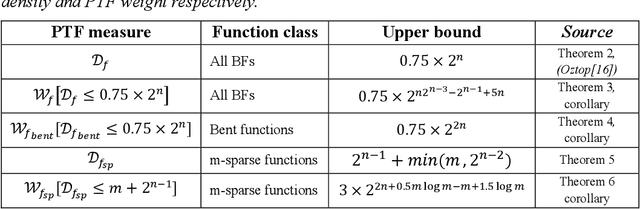
In this report, we show that all n-variable Boolean function can be represented as polynomial threshold functions (PTF) with at most $0.75 \times 2^n$ non-zero integer coefficients and give an upper bound on the absolute value of these coefficients. To our knowledge this provides the best known bound on both the PTF density (number of monomials) and weight (sum of the coefficient magnitudes) of general Boolean functions. The special case of Bent functions is also analyzed and shown that any n-variable Bent function can be represented with integer coefficients less than $2^n$ while also obeying the aforementioned density bound. Finally, sparse Boolean functions, which are almost constant except for $m << 2^n$ number of variable assignments, are shown to have small weight PTFs with density at most $m+2^{n-1}$.
Situated GAIL: Multitask imitation using task-conditioned adversarial inverse reinforcement learning
Nov 01, 2019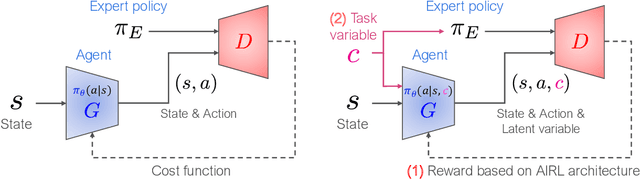
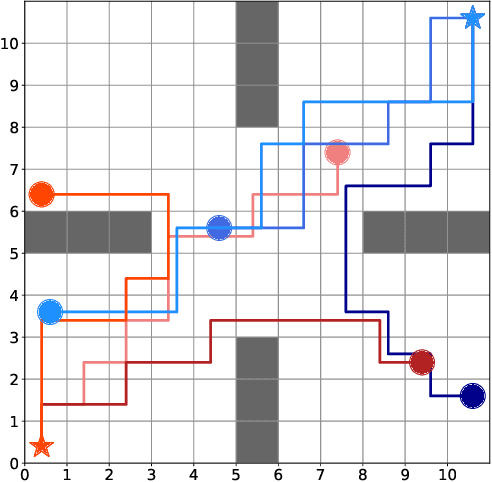
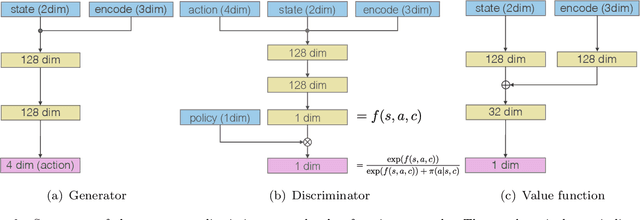
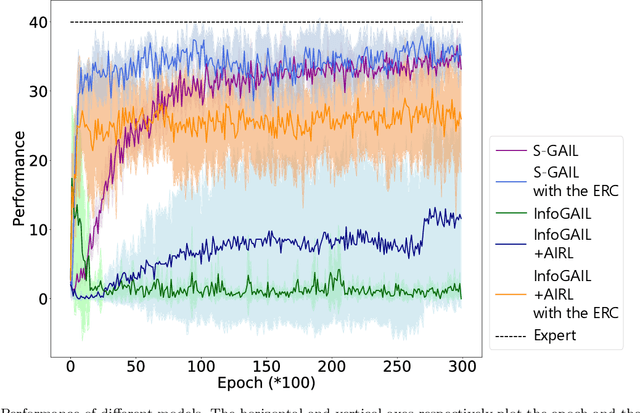
Generative adversarial imitation learning (GAIL) has attracted increasing attention in the field of robot learning. It enables robots to learn a policy to achieve a task demonstrated by an expert while simultaneously estimating the reward function behind the expert's behaviors. However, this framework is limited to learning a single task with a single reward function. This study proposes an extended framework called situated GAIL (S-GAIL), in which a task variable is introduced to both the discriminator and generator of the GAIL framework. The task variable has the roles of discriminating different contexts and making the framework learn different reward functions and policies for multiple tasks. To achieve the early convergence of learning and robustness during reward estimation, we introduce a term to adjust the entropy regularization coefficient in the generator's objective function. Our experiments using two setups (navigation in a discrete grid world and arm reaching in a continuous space) demonstrate that the proposed framework can acquire multiple reward functions and policies more effectively than existing frameworks. The task variable enables our framework to differentiate contexts while sharing common knowledge among multiple tasks.
Compensated Integrated Gradients to Reliably Interpret EEG Classification
Nov 21, 2018
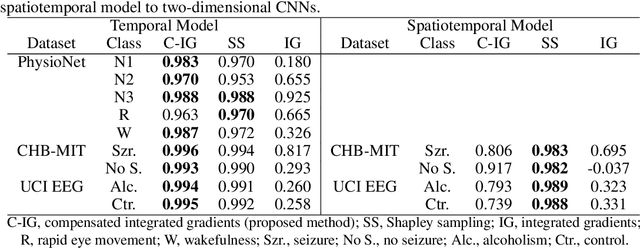
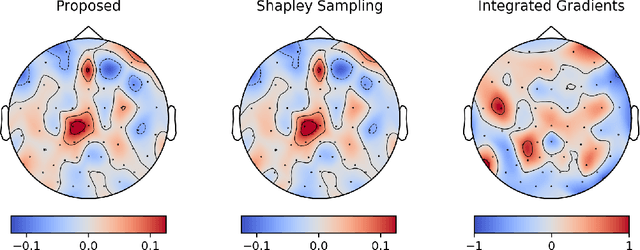
Integrated gradients are widely employed to evaluate the contribution of input features in classification models because it satisfies the axioms for attribution of prediction. This method, however, requires an appropriate baseline for reliable determination of the contributions. We propose a compensated integrated gradients method that does not require a baseline. In fact, the method compensates the attributions calculated by integrated gradients at an arbitrary baseline using Shapley sampling. We prove that the method retrieves reliable attributions if the processes of input features in a classifier are mutually independent, and they are identical like shared weights in convolutional neural networks. Using three electroencephalogram datasets, we experimentally demonstrate that the attributions of the proposed method are more reliable than those of the original integrated gradients, and its computational complexity is much lower than that of Shapley sampling.
On- and Off-Policy Monotonic Policy Improvement
Nov 01, 2017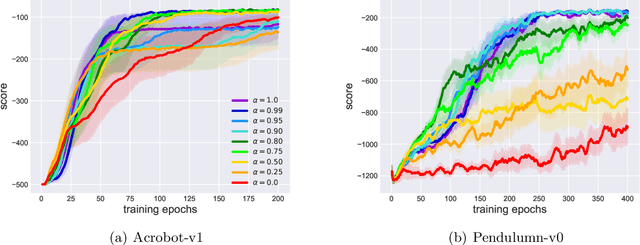
Monotonic policy improvement and off-policy learning are two main desirable properties for reinforcement learning algorithms. In this paper, by lower bounding the performance difference of two policies, we show that the monotonic policy improvement is guaranteed from on- and off-policy mixture samples. An optimization procedure which applies the proposed bound can be regarded as an off-policy natural policy gradient method. In order to support the theoretical result, we provide a trust region policy optimization method using experience replay as a naive application of our bound, and evaluate its performance in two classical benchmark problems.