 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDilated Convolutions with Lateral Inhibitions for Semantic Image Segmentation
Jun 16, 2020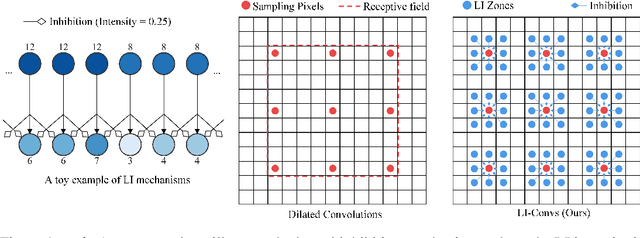
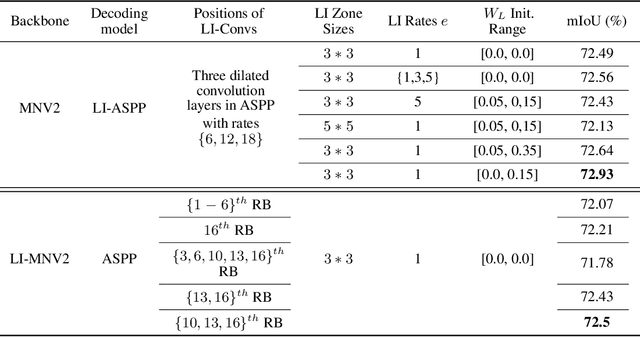

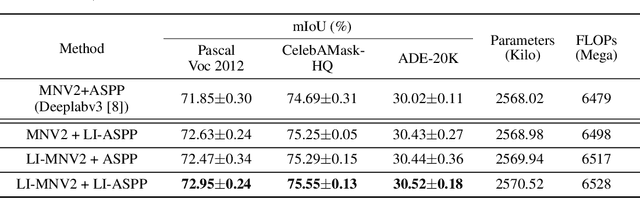
Dilated convolutions are widely used in deep semantic segmentation models as they can enlarge the filters' receptive field without adding additional weights nor sacrificing spatial resolution. However, as dilated convolutional filters do not possess positional knowledge about the pixels on semantically meaningful contours, they could lead to ambiguous predictions on object boundaries. In addition, although dilating the filter can expand its receptive field, the total number of sampled pixels remains unchanged, which usually comprises a small fraction of the receptive field's total area. Inspired by the Lateral Inhibition (LI) mechanisms in human visual systems, we propose the dilated convolution with lateral inhibitions (LI-Convs) to overcome these limitations. Introducing LI mechanisms improves the convolutional filter's sensitivity to semantic object boundaries. Moreover, since LI-Convs also implicitly take the pixels from the laterally inhibited zones into consideration, they can also extract features at a denser scale. By integrating LI-Convs into the Deeplabv3+ architecture, we propose the Lateral Inhibited Atrous Spatial Pyramid Pooling (LI-ASPP) and the Lateral Inhibited MobileNet-V2 (LI-MNV2). Experimental results on three benchmark datasets (PASCAL VOC 2012, CelebAMask-HQ and ADE20K) show that our LI-based segmentation models outperform the baseline on all of them, thus verify the effectiveness and generality of the proposed LI-Convs.
Towards Certified Robustness of Metric Learning
Jun 10, 2020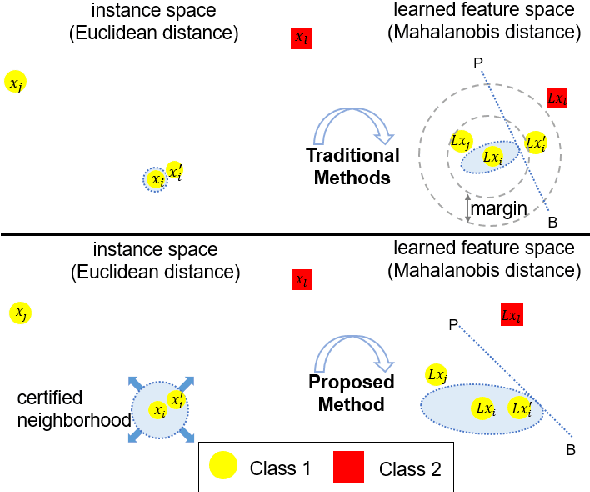
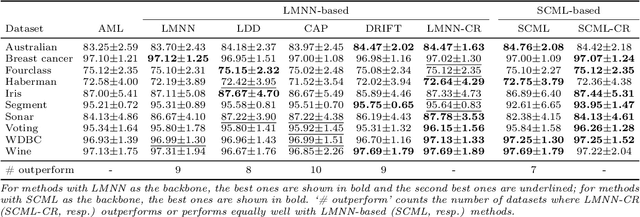
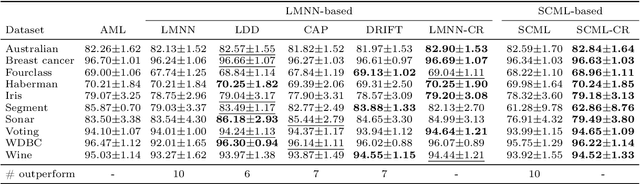
Metric learning aims to learn a distance metric such that semantically similar instances are pulled together while dissimilar instances are pushed away. Many existing methods consider maximizing or at least constraining a distance "margin" that separates similar and dissimilar pairs of instances to guarantee their performance on a subsequent k-nearest neighbor classifier. However, such a margin in the feature space does not necessarily lead to robustness certification or even anticipated generalization advantage, since a small perturbation of test instance in the instance space could still potentially alter the model prediction. To address this problem, we advocate penalizing small distance between training instances and their nearest adversarial examples, and we show that the resulting new approach to metric learning enjoys a larger certified neighborhood with theoretical performance guarantee. Moreover, drawing on an intuitive geometric insight, the proposed new loss term permits an analytically elegant closed-form solution and offers great flexibility in leveraging it jointly with existing metric learning methods. Extensive experiments demonstrate the superiority of the proposed method over the state-of-the-arts in terms of both discrimination accuracy and robustness to noise.
Dynamic Face Video Segmentation via Reinforcement Learning
Jul 02, 2019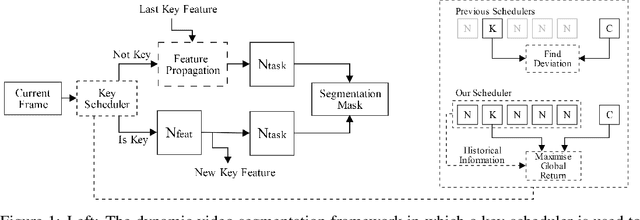
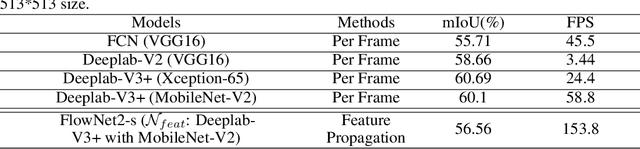
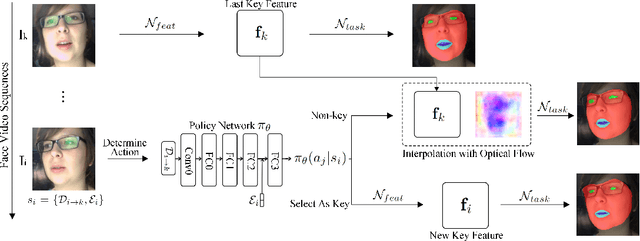
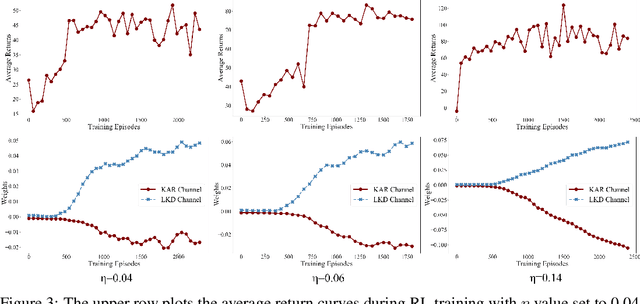
For real-time semantic video segmentation, most recent works utilise a dynamic framework with a key scheduler to make online key/non-key decisions. Some works used a fixed key scheduling policy, while others proposed adaptive key scheduling methods based on heuristic strategies, both of which may lead to suboptimal global performance. To overcome this limitation, we propose to model the online key decision process in dynamic video segmentation as a deep reinforcement learning problem, and to learn an efficient and effective scheduling policy from expert information about decision history and from the process of maximising global return. Moreover, we study the application of dynamic video segmentation on face videos, a field that has not been investigated before. By evaluating on the 300VW dataset, we show that the performance of our reinforcement key scheduler outperforms that of various baseline approaches, and our method could also achieve real-time processing speed. To the best of our knowledge, this is the first work to use reinforcement learning for online key-frame decision in dynamic video segmentation, and also the first work on its application on face videos.
Dynamic Ensemble Active Learning: A Non-Stationary Bandit with Expert Advice
Sep 29, 2018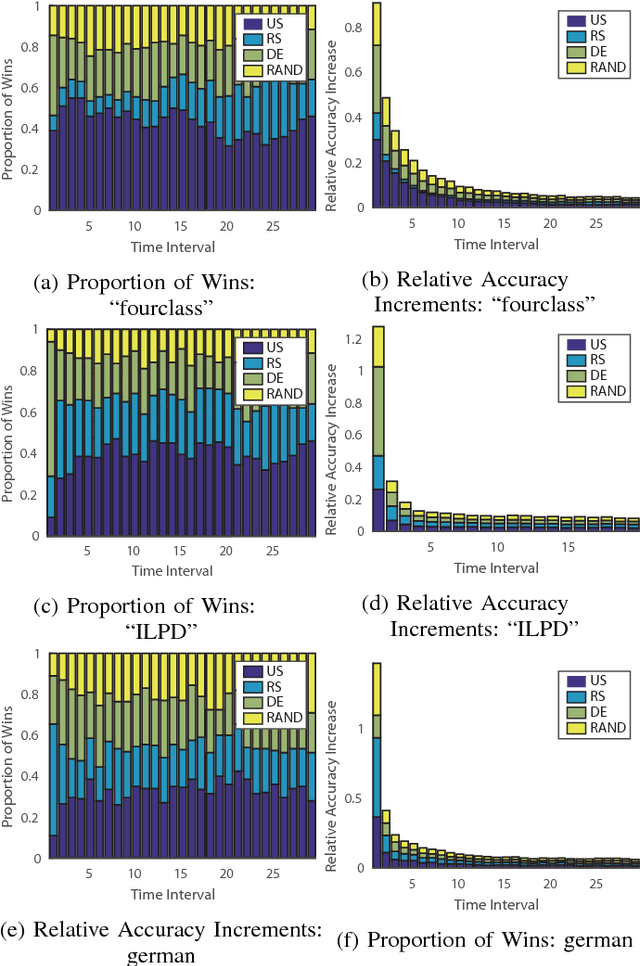
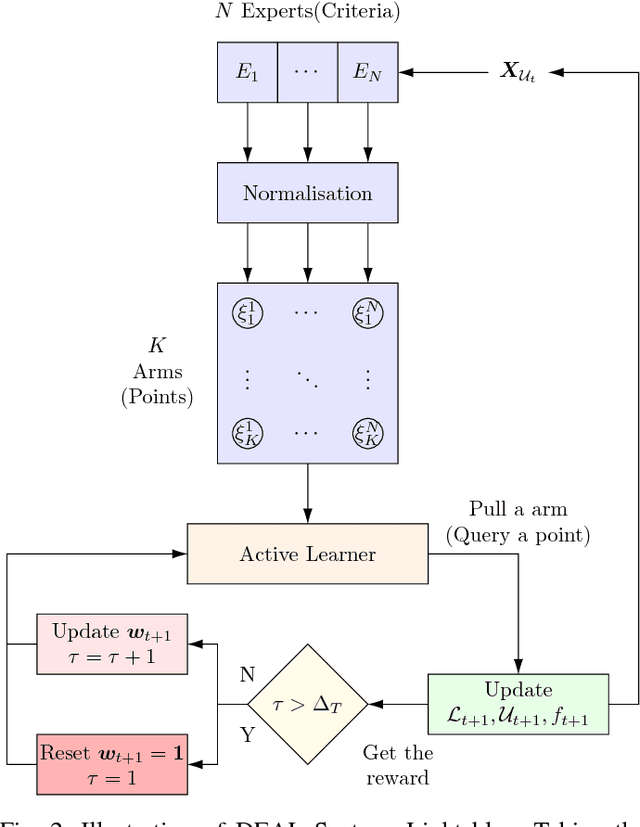
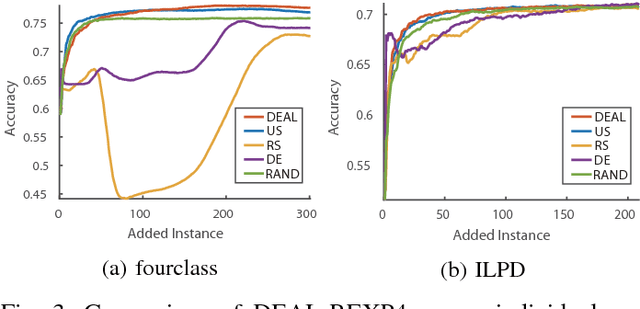
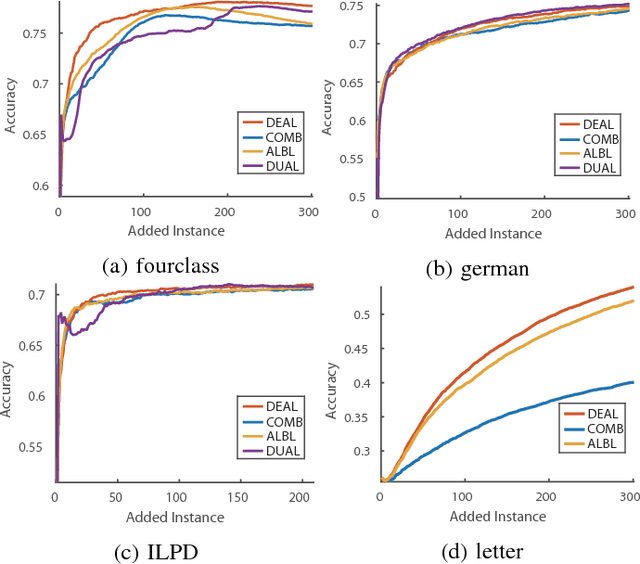
Active learning aims to reduce annotation cost by predicting which samples are useful for a human teacher to label. However it has become clear there is no best active learning algorithm. Inspired by various philosophies about what constitutes a good criteria, different algorithms perform well on different datasets. This has motivated research into ensembles of active learners that learn what constitutes a good criteria in a given scenario, typically via multi-armed bandit algorithms. Though algorithm ensembles can lead to better results, they overlook the fact that not only does algorithm efficacy vary across datasets, but also during a single active learning session. That is, the best criteria is non-stationary. This breaks existing algorithms' guarantees and hampers their performance in practice. In this paper, we propose dynamic ensemble active learning as a more general and promising research direction. We develop a dynamic ensemble active learner based on a non-stationary multi-armed bandit with expert advice algorithm. Our dynamic ensemble selects the right criteria at each step of active learning. It has theoretical guarantees, and shows encouraging results on $13$ popular datasets.
Meta-Learning Transferable Active Learning Policies by Deep Reinforcement Learning
Jun 12, 2018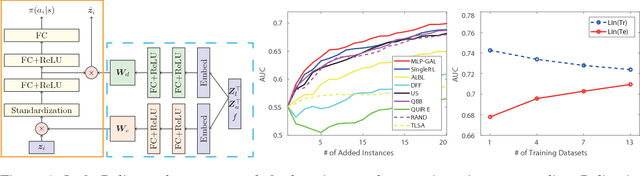
Active learning (AL) aims to enable training high performance classifiers with low annotation cost by predicting which subset of unlabelled instances would be most beneficial to label. The importance of AL has motivated extensive research, proposing a wide variety of manually designed AL algorithms with diverse theoretical and intuitive motivations. In contrast to this body of research, we propose to treat active learning algorithm design as a meta-learning problem and learn the best criterion from data. We model an active learning algorithm as a deep neural network that inputs the base learner state and the unlabelled point set and predicts the best point to annotate next. Training this active query policy network with reinforcement learning, produces the best non-myopic policy for a given dataset. The key challenge in achieving a general solution to AL then becomes that of learner generalisation, particularly across heterogeneous datasets. We propose a multi-task dataset-embedding approach that allows dataset-agnostic active learners to be trained. Our evaluation shows that AL algorithms trained in this way can directly generalise across diverse problems.
Metric Learning via Maximizing the Lipschitz Margin Ratio
Feb 09, 2018
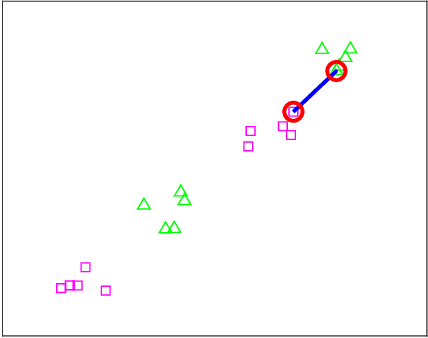
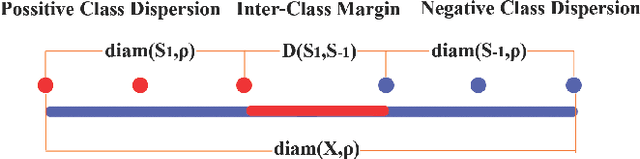

In this paper, we propose the Lipschitz margin ratio and a new metric learning framework for classification through maximizing the ratio. This framework enables the integration of both the inter-class margin and the intra-class dispersion, as well as the enhancement of the generalization ability of a classifier. To introduce the Lipschitz margin ratio and its associated learning bound, we elaborate the relationship between metric learning and Lipschitz functions, as well as the representability and learnability of the Lipschitz functions. After proposing the new metric learning framework based on the introduced Lipschitz margin ratio, we also prove that some well known metric learning algorithms can be shown as special cases of the proposed framework. In addition, we illustrate the framework by implementing it for learning the squared Mahalanobis metric, and by demonstrating its encouraging results on eight popular datasets of machine learning.
Learning Local Metrics and Influential Regions for Classification
Feb 09, 2018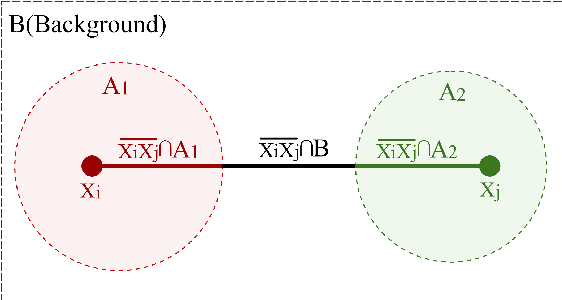

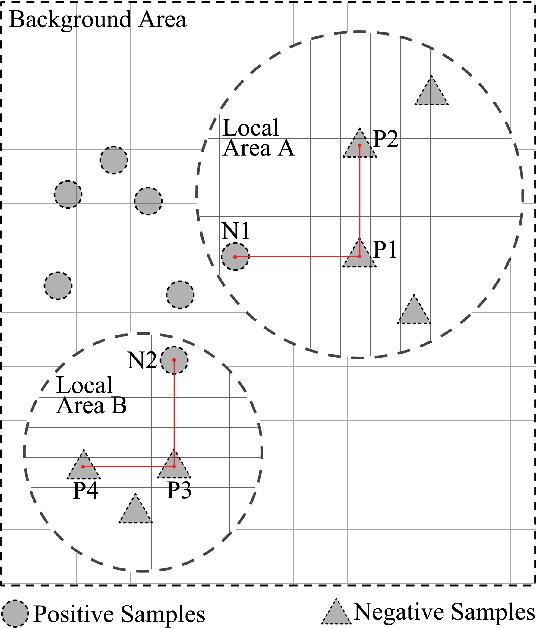

The performance of distance-based classifiers heavily depends on the underlying distance metric, so it is valuable to learn a suitable metric from the data. To address the problem of multimodality, it is desirable to learn local metrics. In this short paper, we define a new intuitive distance with local metrics and influential regions, and subsequently propose a novel local metric learning method for distance-based classification. Our key intuition is to partition the metric space into influential regions and a background region, and then regulate the effectiveness of each local metric to be within the related influential regions. We learn local metrics and influential regions to reduce the empirical hinge loss, and regularize the parameters on the basis of a resultant learning bound. Encouraging experimental results are obtained from various public and popular data sets.