 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBemaGANv2: A Tutorial and Comparative Survey of GAN-based Vocoders for Long-Term Audio Generation
Jun 11, 2025This paper presents a tutorial-style survey and implementation guide of BemaGANv2, an advanced GAN-based vocoder designed for high-fidelity and long-term audio generation. Built upon the original BemaGAN architecture, BemaGANv2 incorporates major architectural innovations by replacing traditional ResBlocks in the generator with the Anti-aliased Multi-Periodicity composition (AMP) module, which internally applies the Snake activation function to better model periodic structures. In the discriminator framework, we integrate the Multi-Envelope Discriminator (MED), a novel architecture we originally proposed, to extract rich temporal envelope features crucial for periodicity detection. Coupled with the Multi-Resolution Discriminator (MRD), this combination enables more accurate modeling of long-range dependencies in audio. We systematically evaluate various discriminator configurations, including MSD + MED, MSD + MRD, and MPD + MED + MRD, using objective metrics (FAD, SSIM, PLCC, MCD) and subjective evaluations (MOS, SMOS). This paper also provides a comprehensive tutorial on the model architecture, training methodology, and implementation to promote reproducibility. The code and pre-trained models are available at: https://github.com/dinhoitt/BemaGANv2.
Pretraining a Shared Q-Network for Data-Efficient Offline Reinforcement Learning
May 09, 2025



Offline reinforcement learning (RL) aims to learn a policy from a static dataset without further interactions with the environment. Collecting sufficiently large datasets for offline RL is exhausting since this data collection requires colossus interactions with environments and becomes tricky when the interaction with the environment is restricted. Hence, how an agent learns the best policy with a minimal static dataset is a crucial issue in offline RL, similar to the sample efficiency problem in online RL. In this paper, we propose a simple yet effective plug-and-play pretraining method to initialize a feature of a $Q$-network to enhance data efficiency in offline RL. Specifically, we introduce a shared $Q$-network structure that outputs predictions of the next state and $Q$-value. We pretrain the shared $Q$-network through a supervised regression task that predicts a next state and trains the shared $Q$-network using diverse offline RL methods. Through extensive experiments, we empirically demonstrate that our method enhances the performance of existing popular offline RL methods on the D4RL, Robomimic and V-D4RL benchmarks. Furthermore, we show that our method significantly boosts data-efficient offline RL across various data qualities and data distributions trough D4RL and ExoRL benchmarks. Notably, our method adapted with only 10% of the dataset outperforms standard algorithms even with full datasets.
Infusing model predictive control into meta-reinforcement learning for mobile robots in dynamic environments
Sep 15, 2021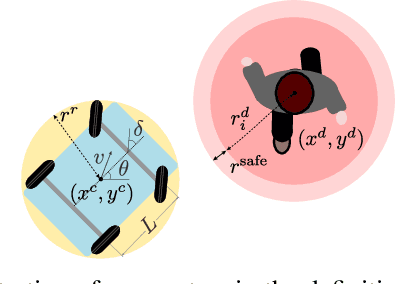
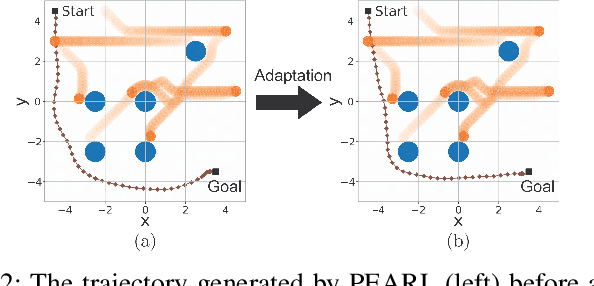
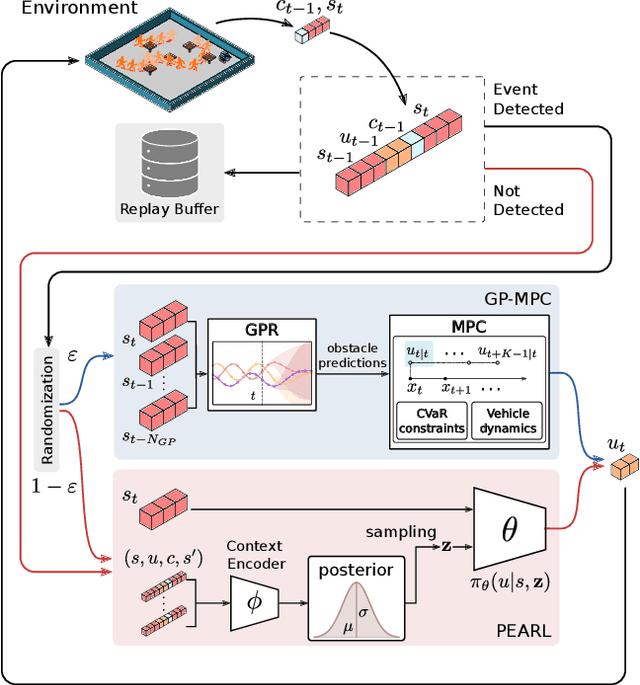
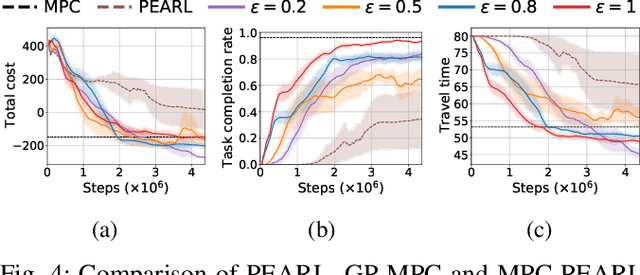
The successful operation of mobile robots requires them to rapidly adapt to environmental changes. Toward developing an adaptive decision-making tool for mobile robots, we propose combining meta-reinforcement learning (meta-RL) with model predictive control (MPC). The key idea of our method is to switch between a meta-learned policy and an MPC controller in an event-triggered fashion. Our method uses an off-policy meta-RL algorithm as a baseline to train a policy using transition samples generated by MPC. The MPC module of our algorithm is carefully designed to infer the movements of obstacles via Gaussian process regression (GPR) and to avoid collisions via conditional value-at-risk (CVaR) constraints. Due to its design, our method benefits from the two complementary tools. First, high-performance action samples generated by the MPC controller enhance the learning performance and stability of the meta-RL algorithm. Second, through the use of the meta-learned policy, the MPC controller is infrequently activated, thereby significantly reducing computation time. The results of our simulations on a restaurant service robot show that our algorithm outperforms both of the baseline methods.