 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Implementation of Probabilistic Models of Cognition
Apr 14, 2016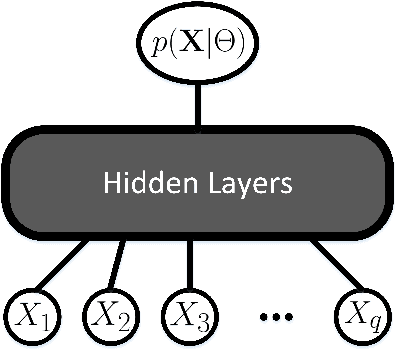
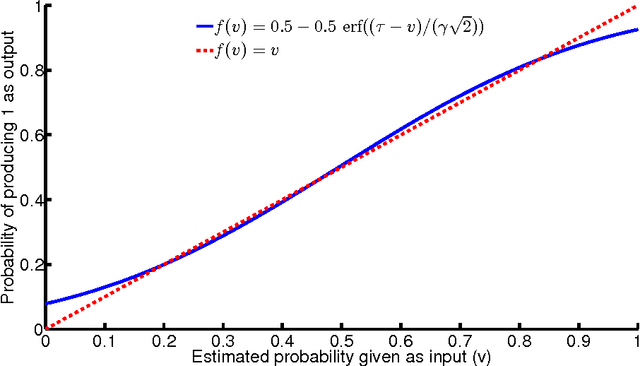
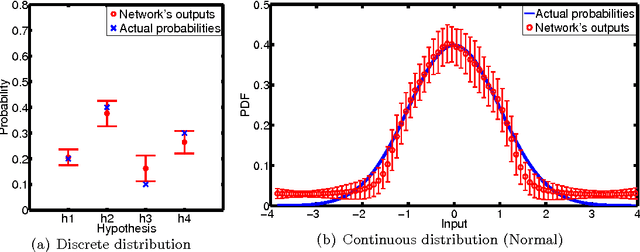
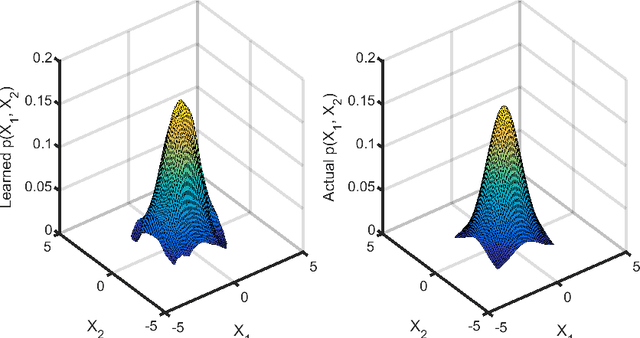
Bayesian models of cognition hypothesize that human brains make sense of data by representing probability distributions and applying Bayes' rule to find the best explanation for available data. Understanding the neural mechanisms underlying probabilistic models remains important because Bayesian models provide a computational framework, rather than specifying mechanistic processes. Here, we propose a deterministic neural-network model which estimates and represents probability distributions from observable events --- a phenomenon related to the concept of probability matching. Our model learns to represent probabilities without receiving any representation of them from the external world, but rather by experiencing the occurrence patterns of individual events. Our neural implementation of probability matching is paired with a neural module applying Bayes' rule, forming a comprehensive neural scheme to simulate human Bayesian learning and inference. Our model also provides novel explanations of base-rate neglect, a notable deviation from Bayes.
Sparse Multivariate Factor Regression
Feb 29, 2016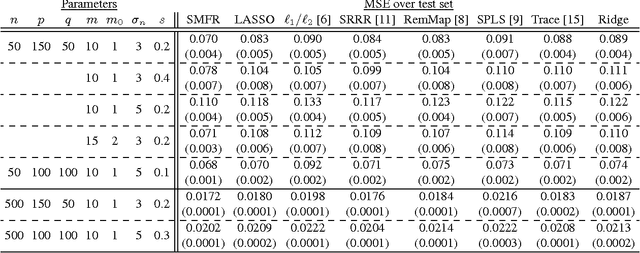
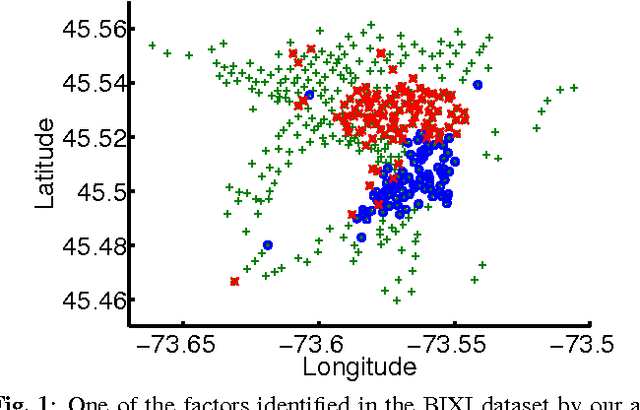
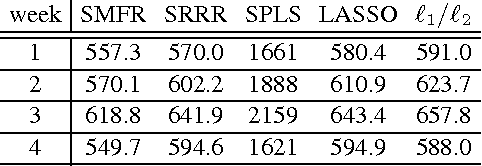
We consider the problem of multivariate regression in a setting where the relevant predictors could be shared among different responses. We propose an algorithm which decomposes the coefficient matrix into the product of a long matrix and a wide matrix, with an elastic net penalty on the former and an $\ell_1$ penalty on the latter. The first matrix linearly transforms the predictors to a set of latent factors, and the second one regresses the responses on these factors. Our algorithm simultaneously performs dimension reduction and coefficient estimation and automatically estimates the number of latent factors from the data. Our formulation results in a non-convex optimization problem, which despite its flexibility to impose effective low-dimensional structure, is difficult, or even impossible, to solve exactly in a reasonable time. We specify an optimization algorithm based on alternating minimization with three different sets of updates to solve this non-convex problem and provide theoretical results on its convergence and optimality. Finally, we demonstrate the effectiveness of our algorithm via experiments on simulated and real data.
Semi-parametric Order-based Generalized Multivariate Regression
Feb 19, 2016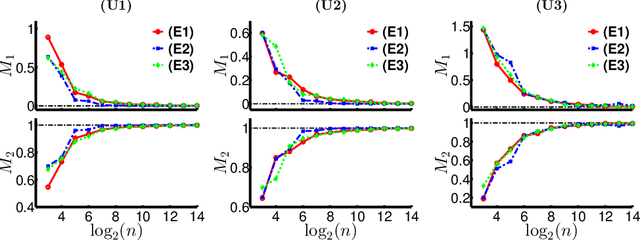
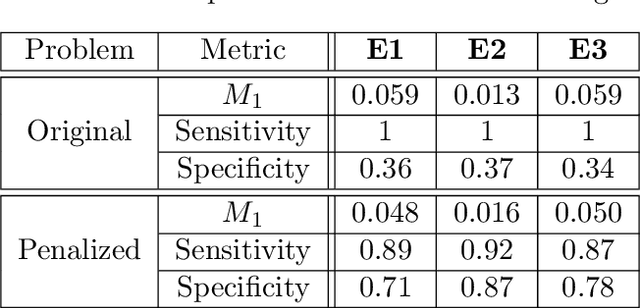
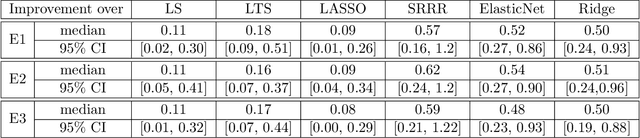

In this paper, we consider a generalized multivariate regression problem where the responses are monotonic functions of linear transformations of predictors. We propose a semi-parametric algorithm based on the ordering of the responses which is invariant to the functional form of the transformation function. We prove that our algorithm, which maximizes the rank correlation of responses and linear transformations of predictors, is a consistent estimator of the true coefficient matrix. We also identify the rate of convergence and show that the squared estimation error decays with a rate of $o(1/\sqrt{n})$. We then propose a greedy algorithm to maximize the highly non-smooth objective function of our model and examine its performance through extensive simulations. Finally, we compare our algorithm with traditional multivariate regression algorithms over synthetic and real data.