 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Algorithm for Inference of Decision Trees from Decision Rule Systems
Jan 08, 2024Decision trees and decision rule systems play important roles as classifiers, knowledge representation tools, and algorithms. They are easily interpretable models for data analysis, making them widely used and studied in computer science. Understanding the relationships between these two models is an important task in this field. There are well-known methods for converting decision trees into systems of decision rules. In this paper, we consider the inverse transformation problem, which is not so simple. Instead of constructing an entire decision tree, our study focuses on a greedy polynomial time algorithm that simulates the operation of a decision tree on a given tuple of attribute values.
Construction of Decision Trees and Acyclic Decision Graphs from Decision Rule Systems
May 02, 2023Decision trees and systems of decision rules are widely used as classifiers, as a means for knowledge representation, and as algorithms. They are among the most interpretable models for data analysis. The study of the relationships between these two models can be seen as an important task of computer science. Methods for transforming decision trees into systems of decision rules are simple and well-known. In this paper, we consider the inverse transformation problem, which is not trivial. We study the complexity of constructing decision trees and acyclic decision graphs representing decision trees from decision rule systems, and we discuss the possibility of not building the entire decision tree, but describing the computation path in this tree for the given input.
Exact learning for infinite families of concepts
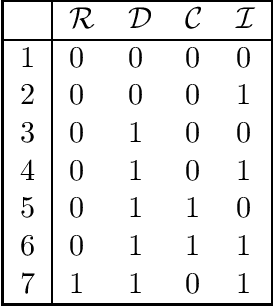
Jan 13, 2022In this paper, based on results of exact learning, test theory, and rough set theory, we study arbitrary infinite families of concepts each of which consists of an infinite set of elements and an infinite set of subsets of this set called concepts. We consider the notion of a problem over a family of concepts that is described by a finite number of elements: for a given concept, we should recognize which of the elements under consideration belong to this concept. As algorithms for problem solving, we consider decision trees of five types: (i) using membership queries, (ii) using equivalence queries, (iii) using both membership and equivalence queries, (iv) using proper equivalence queries, and (v) using both membership and proper equivalence queries. As time complexity, we study the depth of decision trees. In the worst case, with the growth of the number of elements in the problem description, the minimum depth of decision trees of the first type either grows as a logarithm or linearly, and the minimum depth of decision trees of each of the other types either is bounded from above by a constant or grows as a logarithm, or linearly. The obtained results allow us to distinguish seven complexity classes of infinite families of concepts.
Exact learning and test theory
Jan 12, 2022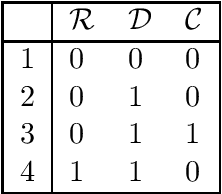
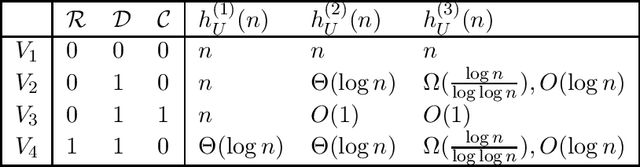
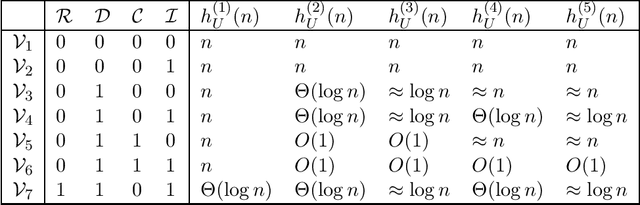
In this paper, based on results of exact learning and test theory, we study arbitrary infinite binary information systems each of which consists of an infinite set of elements and an infinite set of two-valued functions (attributes) defined on the set of elements. We consider the notion of a problem over information system, which is described by a finite number of attributes: for a given element, we should recognize values of these attributes. As algorithms for problem solving, we consider decision trees of two types: (i) using only proper hypotheses (an analog of proper equivalence queries from exact learning), and (ii) using both attributes and proper hypotheses. As time complexity, we study the depth of decision trees. In the worst case, with the growth of the number of attributes in the problem description, the minimum depth of decision trees of both types either is bounded from above by a constant or grows as a logarithm, or linearly. Based on these results and results obtained earlier for attributes and arbitrary hypotheses, we divide the set of all infinite binary information systems into seven complexity classes.