 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Sustainable Development Goals Using Course Descriptions -- from LLMs to Conventional Foundation Models
Feb 26, 2024We present our work on predicting United Nations sustainable development goals (SDG) for university courses. We use an LLM named PaLM 2 to generate training data given a noisy human-authored course description input as input. We use this data to train several different smaller language models to predict SDGs for university courses. This work contributes to better university level adaptation of SDGs. The best performing model in our experiments was BART with an F1-score of 0.786.
Sentiment Analysis Using Aligned Word Embeddings for Uralic Languages
May 24, 2023


In this paper, we present an approach for translating word embeddings from a majority language into 4 minority languages: Erzya, Moksha, Udmurt and Komi-Zyrian. Furthermore, we align these word embeddings and present a novel neural network model that is trained on English data to conduct sentiment analysis and then applied on endangered language data through the aligned word embeddings. To test our model, we annotated a small sentiment analysis corpus for the 4 endangered languages and Finnish. Our method reached at least 56\% accuracy for each endangered language. The models and the sentiment corpus will be released together with this paper. Our research shows that state-of-the-art neural models can be used with endangered languages with the only requirement being a dictionary between the endangered language and a majority language.
Ring That Bell: A Corpus and Method for Multimodal Metaphor Detection in Videos
Dec 15, 2022We present the first openly available multimodal metaphor annotated corpus. The corpus consists of videos including audio and subtitles that have been annotated by experts. Furthermore, we present a method for detecting metaphors in the new dataset based on the textual content of the videos. The method achieves a high F1-score (62\%) for metaphorical labels. We also experiment with other modalities and multimodal methods; however, these methods did not out-perform the text-based model. In our error analysis, we do identify that there are cases where video could help in disambiguating metaphors, however, the visual cues are too subtle for our model to capture. The data is available on Zenodo.
Modern French Poetry Generation with RoBERTa and GPT-2
Dec 06, 2022


We present a novel neural model for modern poetry generation in French. The model consists of two pretrained neural models that are fine-tuned for the poem generation task. The encoder of the model is a RoBERTa based one while the decoder is based on GPT-2. This way the model can benefit from the superior natural language understanding performance of RoBERTa and the good natural language generation performance of GPT-2. Our evaluation shows that the model can create French poetry successfully. On a 5 point scale, the lowest score of 3.57 was given by human judges to typicality and emotionality of the output poetry while the best score of 3.79 was given to understandability.
Emotion Conditioned Creative Dialog Generation
Dec 06, 2022We present a DialGPT based model for generating creative dialog responses that are conditioned based on one of the following emotions: anger, disgust, fear, happiness, pain, sadness and surprise. Our model is capable of producing a contextually apt response given an input sentence and a desired emotion label. Our model is capable of expressing the desired emotion with an accuracy of 0.6. The best performing emotions are neutral, fear and disgust. When measuring the strength of the expressed emotion, we find that anger, fear and disgust are expressed in the most strong fashion by the model.
Video Games as a Corpus: Sentiment Analysis using Fallout New Vegas Dialog
Dec 05, 2022



We present a method for extracting a multilingual sentiment annotated dialog data set from Fallout New Vegas. The game developers have preannotated every line of dialog in the game in one of the 8 different sentiments: \textit{anger, disgust, fear, happy, neutral, pained, sad } and \textit{surprised}. The game has been translated into English, Spanish, German, French and Italian. We conduct experiments on multilingual, multilabel sentiment analysis on the extracted data set using multilingual BERT, XLMRoBERTa and language specific BERT models. In our experiments, multilingual BERT outperformed XLMRoBERTa for most of the languages, also language specific models were slightly better than multilingual BERT for most of the languages. The best overall accuracy was 54\% and it was achieved by using multilingual BERT on Spanish data. The extracted data set presents a challenging task for sentiment analysis. We have released the data, including the testing and training splits, openly on Zenodo. The data set has been shuffled for copyright reasons.
Automatic Generation of Factual News Headlines in Finnish
Dec 05, 2022We present a novel approach to generating news headlines in Finnish for a given news story. We model this as a summarization task where a model is given a news article, and its task is to produce a concise headline describing the main topic of the article. Because there are no openly available GPT-2 models for Finnish, we will first build such a model using several corpora. The model is then fine-tuned for the headline generation task using a massive news corpus. The system is evaluated by 3 expert journalists working in a Finnish media house. The results showcase the usability of the presented approach as a headline suggestion tool to facilitate the news production process.
When to Laugh and How Hard? A Multimodal Approach to Detecting Humor and its Intensity
Nov 03, 2022


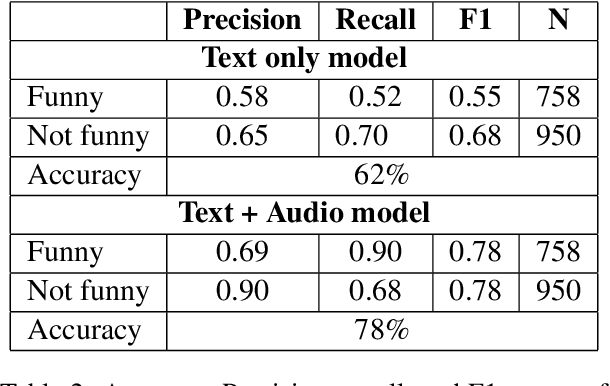
Prerecorded laughter accompanying dialog in comedy TV shows encourages the audience to laugh by clearly marking humorous moments in the show. We present an approach for automatically detecting humor in the Friends TV show using multimodal data. Our model is capable of recognizing whether an utterance is humorous or not and assess the intensity of it. We use the prerecorded laughter in the show as annotation as it marks humor and the length of the audience's laughter tells us how funny a given joke is. We evaluate the model on episodes the model has not been exposed to during the training phase. Our results show that the model is capable of correctly detecting whether an utterance is humorous 78% of the time and how long the audience's laughter reaction should last with a mean absolute error of 600 milliseconds.
Multilingual Persuasion Detection: Video Games as an Invaluable Data Source for NLP
Jul 10, 2022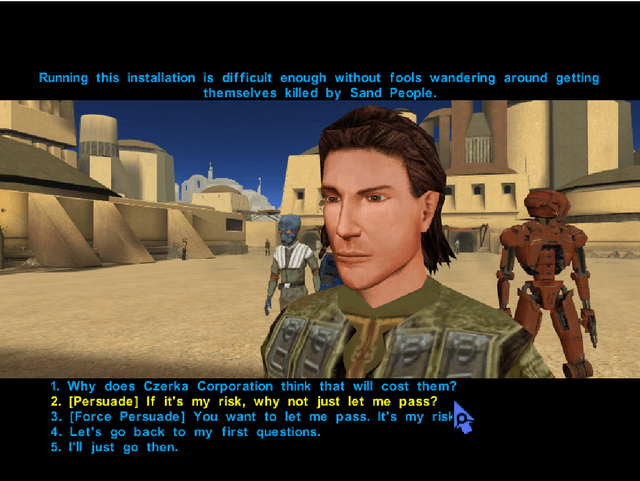
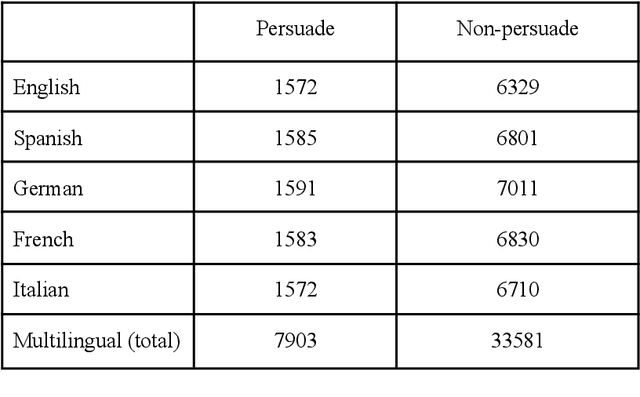
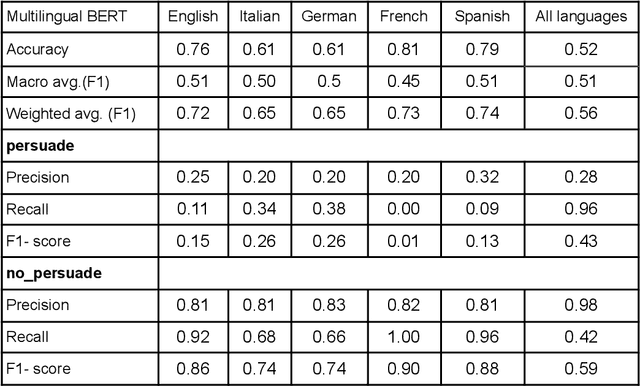
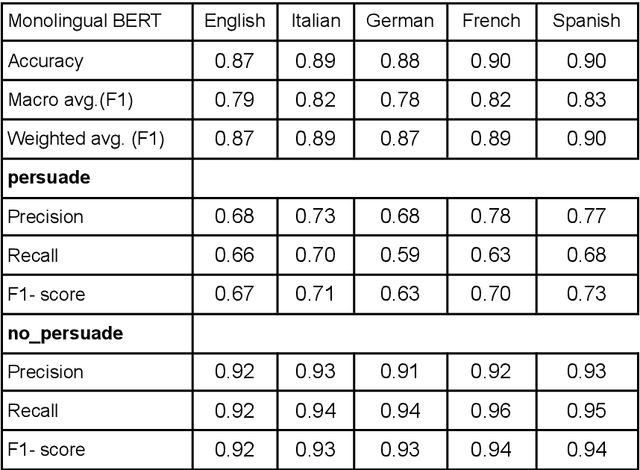
Role-playing games (RPGs) have a considerable amount of text in video game dialogues. Quite often this text is semi-annotated by the game developers. In this paper, we extract a multilingual dataset of persuasive dialogue from several RPGs. We show the viability of this data in building a persuasion detection system using a natural language processing (NLP) model called BERT. We believe that video games have a lot of unused potential as a datasource for a variety of NLP tasks. The code and data described in this paper are available on Zenodo.
Harnessing Multilingual Resources to Question Answering in Arabic
May 16, 2022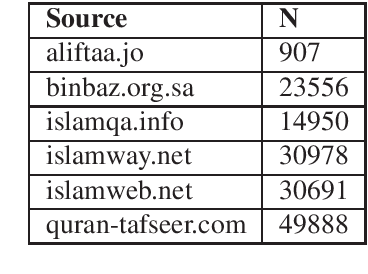
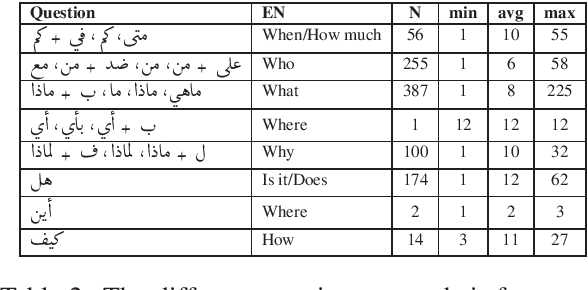


The goal of the paper is to predict answers to questions given a passage of Qur'an. The answers are always found in the passage, so the task of the model is to predict where an answer starts and where it ends. As the initial data set is rather small for training, we make use of multilingual BERT so that we can augment the training data by using data available for languages other than Arabic. Furthermore, we crawl a large Arabic corpus that is domain specific to religious discourse. Our approach consists of two steps, first we train a BERT model to predict a set of possible answers in a passage. Finally, we use another BERT based model to rank the candidate answers produced by the first BERT model.