Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Depression in Thai Blog Posts: a Dataset and a Baseline
Nov 08, 2021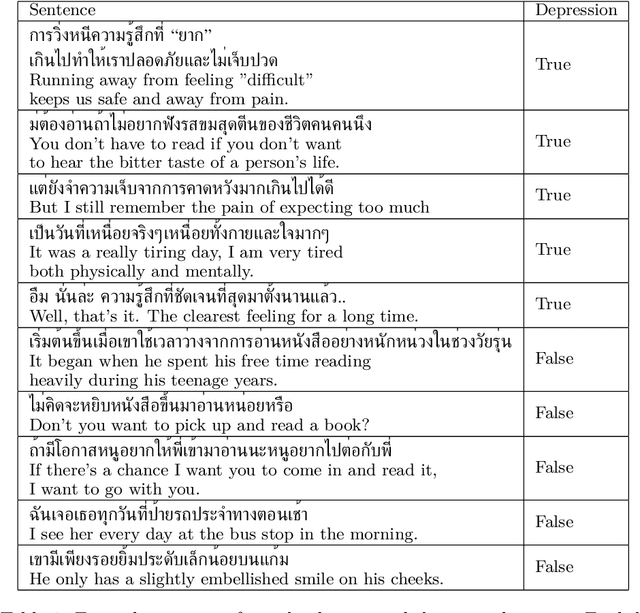
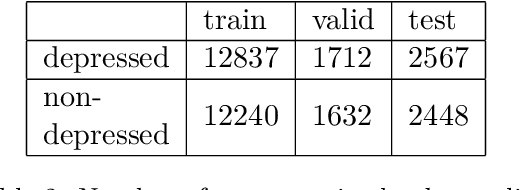
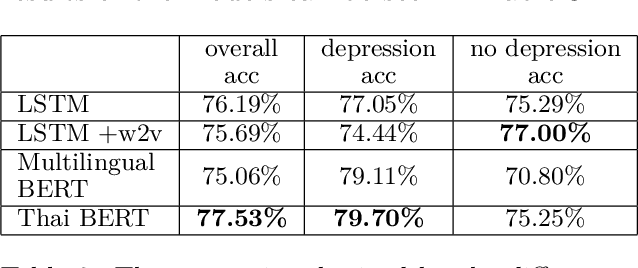
We present the first openly available corpus for detecting depression in Thai. Our corpus is compiled by expert verified cases of depression in several online blogs. We experiment with two different LSTM based models and two different BERT based models. We achieve a 77.53\% accuracy with a Thai BERT model in detecting depression. This establishes a good baseline for future researcher on the same corpus. Furthermore, we identify a need for Thai embeddings that have been trained on a more varied corpus than Wikipedia. Our corpus, code and trained models have been released openly on Zenodo.
* Workshop on Noisy User-generated Text (at EMNLP)
Via