 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulating a Tetris-Inspired 3D Video Representation
Jul 11, 2024Video Synopsis is a technique that performs video compression in a way that preserves the activity in the video. This technique is particularly useful in surveillance and monitoring applications. Although it is still a nascent field of research, there have been several approaches proposed over the last two decades varying with the application, optimization type, nature of data feed, etc. The primary data required for these algorithms arises from some sort of object tracking method. In this paper, we discuss different spatio-temporal data representations suitable for different applications. We also present a formal definition for the video synopsis algorithm. We further discuss the assumptions and modifications to this definition required for a simpler version of the problem. We explore the application of a packing algorithm to solve the problem of video synopsis. Since the nature of the data is three dimensional, we consider 3D packing problems in the discussion. This paper also provides an extensive literature review of different video synopsis methods and packing problems. Lastly, we examine the different applications of this algorithm and how the different data representations discussed earlier can make the problem simpler. We also discuss the future directions of research that can be explored following this discussion.
Non-Uniform Spatial Alignment Errors in sUAS Imagery From Wide-Area Disasters
May 10, 2024



This work presents the first quantitative study of alignment errors between small uncrewed aerial systems (sUAS) geospatial imagery and a priori building polygons and finds that alignment errors are non-uniform and irregular. The work also introduces a publicly available dataset of imagery, building polygons, and human-generated and curated adjustments that can be used to evaluate existing strategies for aligning building polygons with sUAS imagery. There are no efforts that have aligned pre-existing spatial data with sUAS imagery, and thus, there is no clear state of practice. However, this effort and analysis show that the translational alignment errors present in this type of data, averaging 82px and an intersection over the union of 0.65, which would induce further errors and biases in downstream machine learning systems unless addressed. This study identifies and analyzes the translational alignment errors of 21,619 building polygons in fifty-one orthomosaic images, covering 16787.2 Acres (26.23 square miles), constructed from sUAS raw imagery from nine wide-area disasters (Hurricane Ian, Hurricane Harvey, Hurricane Michael, Hurricane Ida, Hurricane Idalia, Hurricane Laura, the Mayfield Tornado, the Musset Bayou Fire, and the Kilauea Eruption). The analysis finds no uniformity among the angle and distance metrics of the building polygon alignments as they present an average degree variance of 0.4 and an average pixel distance variance of 0.45. This work alerts the sUAS community to the problem of spatial alignment and that a simple linear transform, often used to align satellite imagery, will not be sufficient to align spatial data in sUAS orthomosaic imagery.
Humane Speech Synthesis through Zero-Shot Emotion and Disfluency Generation
Mar 31, 2024Contemporary conversational systems often present a significant limitation: their responses lack the emotional depth and disfluent characteristic of human interactions. This absence becomes particularly noticeable when users seek more personalized and empathetic interactions. Consequently, this makes them seem mechanical and less relatable to human users. Recognizing this gap, we embarked on a journey to humanize machine communication, to ensure AI systems not only comprehend but also resonate. To address this shortcoming, we have designed an innovative speech synthesis pipeline. Within this framework, a cutting-edge language model introduces both human-like emotion and disfluencies in a zero-shot setting. These intricacies are seamlessly integrated into the generated text by the language model during text generation, allowing the system to mirror human speech patterns better, promoting more intuitive and natural user interactions. These generated elements are then adeptly transformed into corresponding speech patterns and emotive sounds using a rule-based approach during the text-to-speech phase. Based on our experiments, our novel system produces synthesized speech that's almost indistinguishable from genuine human communication, making each interaction feel more personal and authentic.
Temporal Word Meaning Disambiguation using TimeLMs
Oct 15, 2022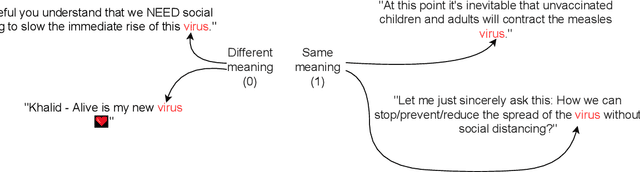
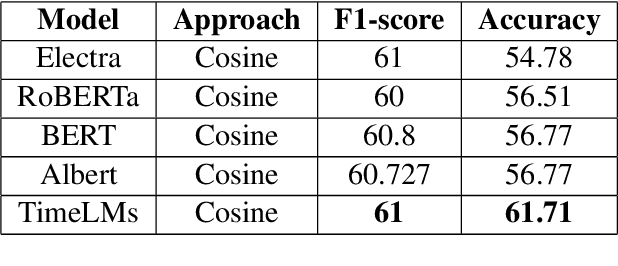
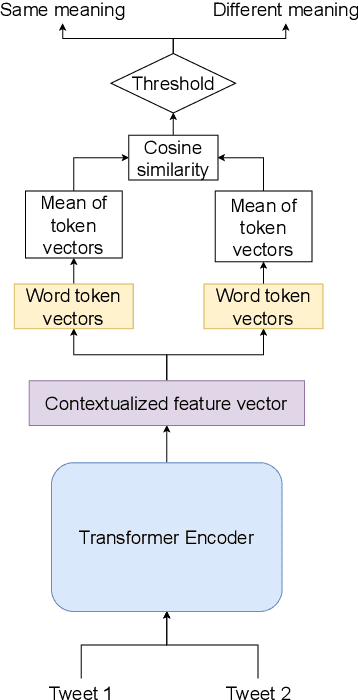
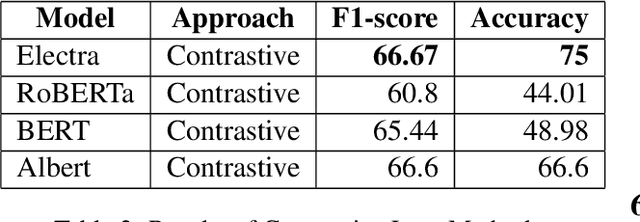
Meaning of words constantly changes given the events in modern civilization. Large Language Models use word embeddings, which are often static and thus cannot cope with this semantic change. Thus,it is important to resolve ambiguity in word meanings. This paper is an effort in this direction, where we explore methods for word sense disambiguation for the EvoNLP shared task. We conduct rigorous ablations for two solutions to this problem. We see that an approach using time-aware language models helps this task. Furthermore, we explore possible future directions to this problem.