 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Copy-Augmented Sequence-to-Sequence Architecture Gives Good Performance on Task-Oriented Dialogue
Aug 14, 2017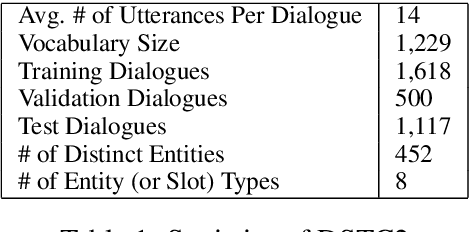
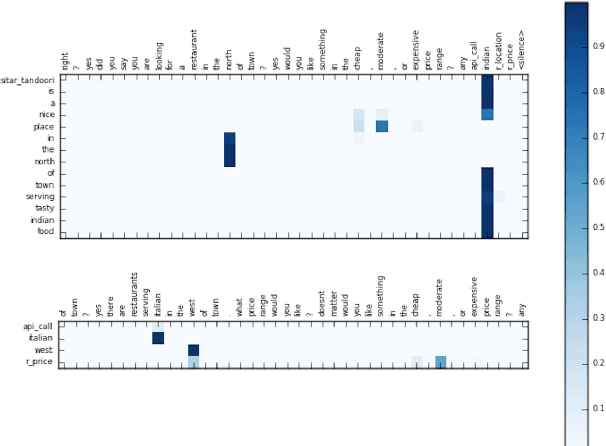
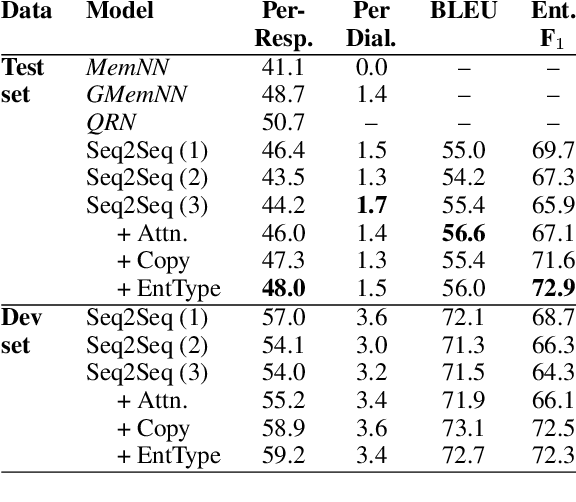

Task-oriented dialogue focuses on conversational agents that participate in user-initiated dialogues on domain-specific topics. In contrast to chatbots, which simply seek to sustain open-ended meaningful discourse, existing task-oriented agents usually explicitly model user intent and belief states. This paper examines bypassing such an explicit representation by depending on a latent neural embedding of state and learning selective attention to dialogue history together with copying to incorporate relevant prior context. We complement recent work by showing the effectiveness of simple sequence-to-sequence neural architectures with a copy mechanism. Our model outperforms more complex memory-augmented models by 7% in per-response generation and is on par with the current state-of-the-art on DSTC2.
Key-Value Retrieval Networks for Task-Oriented Dialogue
Jul 14, 2017

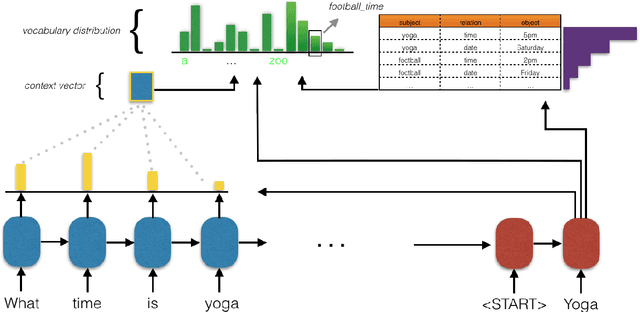
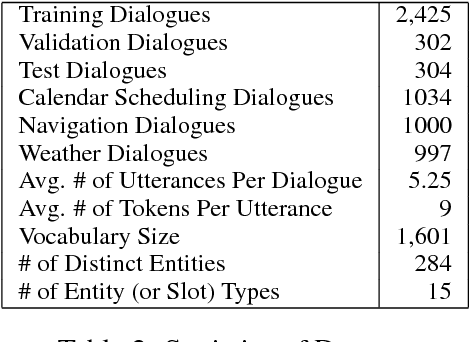
Neural task-oriented dialogue systems often struggle to smoothly interface with a knowledge base. In this work, we seek to address this problem by proposing a new neural dialogue agent that is able to effectively sustain grounded, multi-domain discourse through a novel key-value retrieval mechanism. The model is end-to-end differentiable and does not need to explicitly model dialogue state or belief trackers. We also release a new dataset of 3,031 dialogues that are grounded through underlying knowledge bases and span three distinct tasks in the in-car personal assistant space: calendar scheduling, weather information retrieval, and point-of-interest navigation. Our architecture is simultaneously trained on data from all domains and significantly outperforms a competitive rule-based system and other existing neural dialogue architectures on the provided domains according to both automatic and human evaluation metrics.
Learning Symmetric Collaborative Dialogue Agents with Dynamic Knowledge Graph Embeddings
Apr 24, 2017

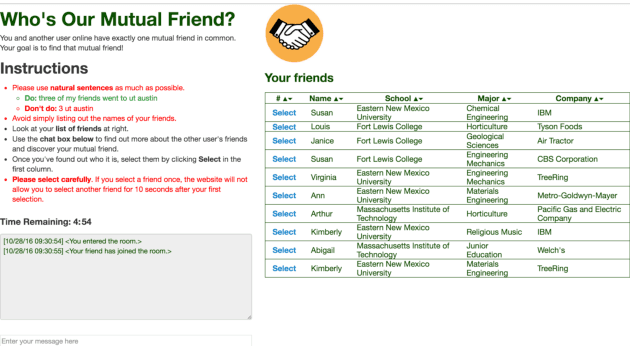

We study a symmetric collaborative dialogue setting in which two agents, each with private knowledge, must strategically communicate to achieve a common goal. The open-ended dialogue state in this setting poses new challenges for existing dialogue systems. We collected a dataset of 11K human-human dialogues, which exhibits interesting lexical, semantic, and strategic elements. To model both structured knowledge and unstructured language, we propose a neural model with dynamic knowledge graph embeddings that evolve as the dialogue progresses. Automatic and human evaluations show that our model is both more effective at achieving the goal and more human-like than baseline neural and rule-based models.
SceneSeer: 3D Scene Design with Natural Language
Feb 28, 2017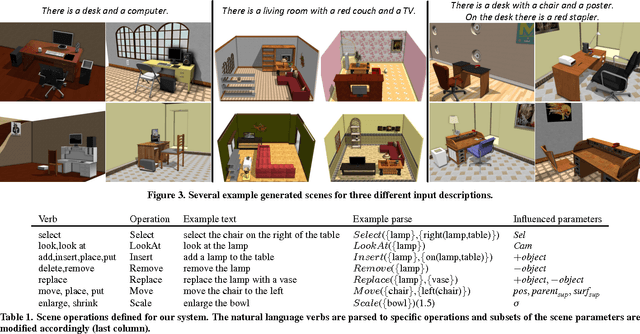

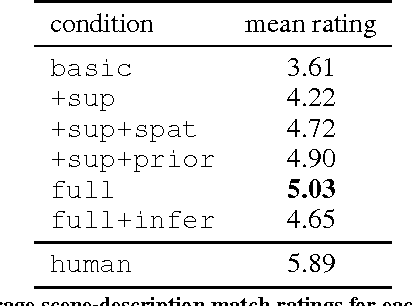

Designing 3D scenes is currently a creative task that requires significant expertise and effort in using complex 3D design interfaces. This effortful design process starts in stark contrast to the easiness with which people can use language to describe real and imaginary environments. We present SceneSeer: an interactive text to 3D scene generation system that allows a user to design 3D scenes using natural language. A user provides input text from which we extract explicit constraints on the objects that should appear in the scene. Given these explicit constraints, the system then uses a spatial knowledge base learned from an existing database of 3D scenes and 3D object models to infer an arrangement of the objects forming a natural scene matching the input description. Using textual commands the user can then iteratively refine the created scene by adding, removing, replacing, and manipulating objects. We evaluate the quality of 3D scenes generated by SceneSeer in a perceptual evaluation experiment where we compare against manually designed scenes and simpler baselines for 3D scene generation. We demonstrate how the generated scenes can be iteratively refined through simple natural language commands.