 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Dataset Diversity from a Geometric Perspective
Feb 10, 2026Diversity can be broadly defined as the presence of meaningful variation across elements, which can be viewed from multiple perspectives, including statistical variation and geometric structural richness in the dataset. Existing diversity metrics, such as feature-space dispersion and metric-space magnitude, primarily capture distributional variation or entropy, while largely neglecting the geometric structure of datasets. To address this gap, we introduce a framework based on topological data analysis (TDA) and persistence landscapes (PLs) to extract and quantify geometric features from data. This approach provides a theoretically grounded means of measuring diversity beyond entropy, capturing the rich geometric and structural properties of datasets. Through extensive experiments across diverse modalities, we demonstrate that our proposed PLs-based diversity metric (PLDiv) is powerful, reliable, and interpretable, directly linking data diversity to its underlying geometry and offering a foundational tool for dataset construction, augmentation, and evaluation.
"Let's Eat Grandma": When Punctuation Matters in Sentence Representation for Sentiment Analysis
Dec 10, 2020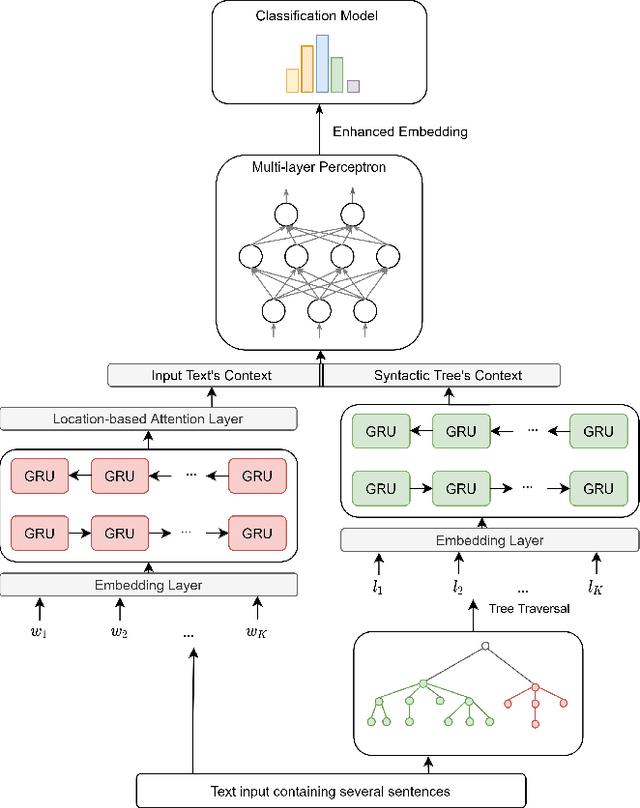

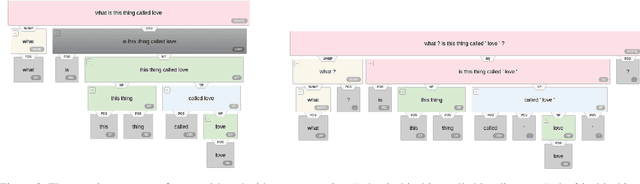
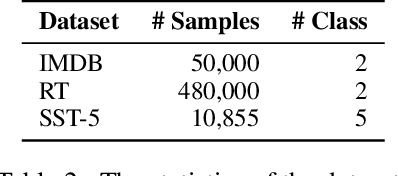
Neural network-based embeddings have been the mainstream approach for creating a vector representation of the text to capture lexical and semantic similarities and dissimilarities. In general, existing encoding methods dismiss the punctuation as insignificant information; consequently, they are routinely eliminated in the pre-processing phase as they are shown to improve task performance. In this paper, we hypothesize that punctuation could play a significant role in sentiment analysis and propose a novel representation model to improve syntactic and contextual performance. We corroborate our findings by conducting experiments on publicly available datasets and verify that our model can identify the sentiments more accurately over other state-of-the-art baseline methods.