 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning-based sliding window for continual learning under concept drift
Mar 15, 2026Traditional machine learning assumes a stationary data distribution, yet many real-world applications operate on nonstationary streams in which the underlying concept evolves over time. This problem can also be viewed as task-free continual learning under concept drift, where a model must adapt sequentially without explicit task identities or task boundaries. In such settings, effective learning requires both rapid adaptation to new data and forgetting of outdated information. A common solution is based on a sliding window, but this approach is often computationally demanding because the model must be repeatedly retrained from scratch on the most recent data. We propose a different perspective based on machine unlearning. Instead of rebuilding the model each time the active window changes, we remove the influence of outdated samples using unlearning and then update the model with newly observed data. This enables efficient, targeted forgetting while preserving adaptation to evolving distributions. To the best of our knowledge, this is the first work to connect machine unlearning with concept drift mitigation for task-free continual learning. Empirical results on image stream classification across multiple drift scenarios demonstrate that the proposed approach offers a competitive and computationally efficient alternative to standard sliding-window retraining. Our implementation can be found at \hrehttps://anonymous.4open.science/r/MUNDataStream-60F3}{https://anonymous.4open.science/r/MUNDataStream-60F3}.
Holistic Continual Learning under Concept Drift with Adaptive Memory Realignment
Jul 03, 2025



Traditional continual learning methods prioritize knowledge retention and focus primarily on mitigating catastrophic forgetting, implicitly assuming that the data distribution of previously learned tasks remains static. This overlooks the dynamic nature of real-world data streams, where concept drift permanently alters previously seen data and demands both stability and rapid adaptation. We introduce a holistic framework for continual learning under concept drift that simulates realistic scenarios by evolving task distributions. As a baseline, we consider Full Relearning (FR), in which the model is retrained from scratch on newly labeled samples from the drifted distribution. While effective, this approach incurs substantial annotation and computational overhead. To address these limitations, we propose Adaptive Memory Realignment (AMR), a lightweight alternative that equips rehearsal-based learners with a drift-aware adaptation mechanism. AMR selectively removes outdated samples of drifted classes from the replay buffer and repopulates it with a small number of up-to-date instances, effectively realigning memory with the new distribution. This targeted resampling matches the performance of FR while reducing the need for labeled data and computation by orders of magnitude. To enable reproducible evaluation, we introduce four concept-drift variants of standard vision benchmarks: Fashion-MNIST-CD, CIFAR10-CD, CIFAR100-CD, and Tiny-ImageNet-CD, where previously seen classes reappear with shifted representations. Comprehensive experiments on these datasets using several rehearsal-based baselines show that AMR consistently counters concept drift, maintaining high accuracy with minimal overhead. These results position AMR as a scalable solution that reconciles stability and plasticity in non-stationary continual learning environments.
Advanced Machine Learning Techniques for Fake News (Online Disinformation) Detection: A Systematic Mapping Study
Dec 28, 2020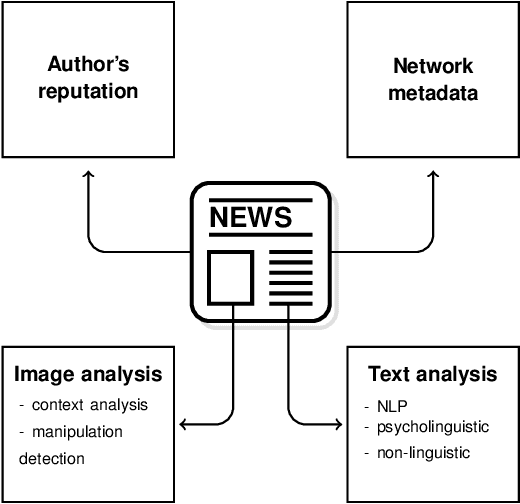
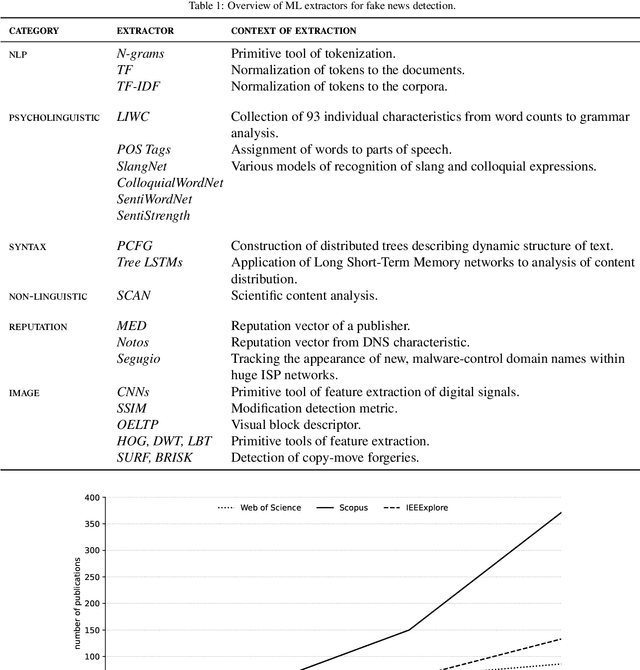
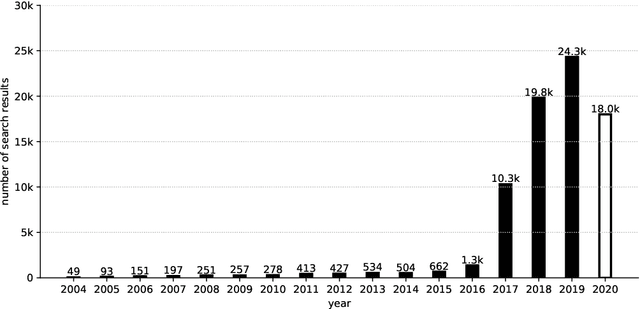

Fake news has now grown into a big problem for societies and also a major challenge for people fighting disinformation. This phenomenon plagues democratic elections, reputations of individual persons or organizations, and has negatively impacted citizens, (e.g., during the COVID-19 pandemic in the US or Brazil). Hence, developing effective tools to fight this phenomenon by employing advanced Machine Learning (ML) methods poses a significant challenge. The following paper displays the present body of knowledge on the application of such intelligent tools in the fight against disinformation. It starts by showing the historical perspective and the current role of fake news in the information war. Proposed solutions based solely on the work of experts are analysed and the most important directions of the application of intelligent systems in the detection of misinformation sources are pointed out. Additionally, the paper presents some useful resources (mainly datasets useful when assessing ML solutions for fake news detection) and provides a short overview of the most important R&D projects related to this subject. The main purpose of this work is to analyse the current state of knowledge in detecting fake news; on the one hand to show possible solutions, and on the other hand to identify the main challenges and methodological gaps to motivate future research.