 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping AI Risk Mitigations: Evidence Scan and Preliminary AI Risk Mitigation Taxonomy
Dec 12, 2025Organizations and governments that develop, deploy, use, and govern AI must coordinate on effective risk mitigation. However, the landscape of AI risk mitigation frameworks is fragmented, uses inconsistent terminology, and has gaps in coverage. This paper introduces a preliminary AI Risk Mitigation Taxonomy to organize AI risk mitigations and provide a common frame of reference. The Taxonomy was developed through a rapid evidence scan of 13 AI risk mitigation frameworks published between 2023-2025, which were extracted into a living database of 831 AI risk mitigations. The mitigations were iteratively clustered & coded to create the Taxonomy. The preliminary AI Risk Mitigation Taxonomy organizes mitigations into four categories and 23 subcategories: (1) Governance & Oversight: Formal organizational structures and policy frameworks that establish human oversight mechanisms and decision protocols; (2) Technical & Security: Technical, physical, and engineering safeguards that secure AI systems and constrain model behaviors; (3) Operational Process: processes and management frameworks governing AI system deployment, usage, monitoring, incident handling, and validation; and (4) Transparency & Accountability: formal disclosure practices and verification mechanisms that communicate AI system information and enable external scrutiny. The rapid evidence scan and taxonomy construction also revealed several cases where terms like 'risk management' and 'red teaming' are used widely but refer to different responsible actors, actions, and mechanisms of action to reduce risk. This Taxonomy and associated mitigation database, while preliminary, offers a starting point for collation and synthesis of AI risk mitigations. It also offers an accessible, structured way for different actors in the AI ecosystem to discuss and coordinate action to reduce risks from AI.
RAFT: A Real-World Few-Shot Text Classification Benchmark
Sep 28, 2021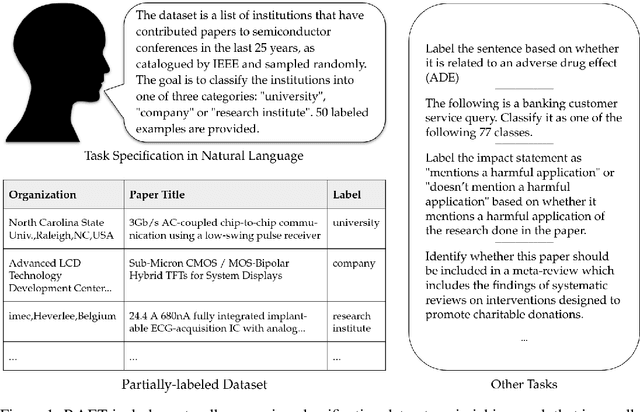
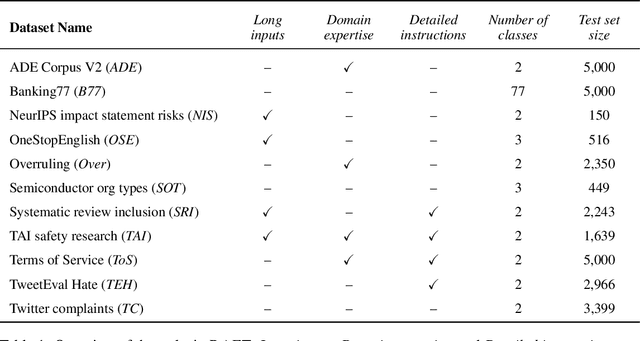
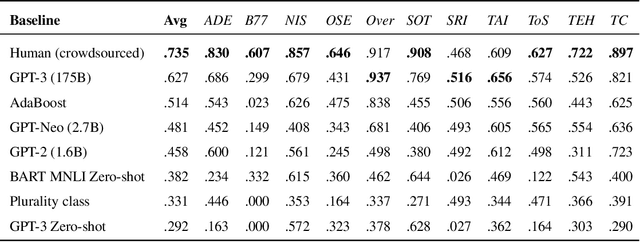

Large pre-trained language models have shown promise for few-shot learning, completing text-based tasks given only a few task-specific examples. Will models soon solve classification tasks that have so far been reserved for human research assistants? Existing benchmarks are not designed to measure progress in applied settings, and so don't directly answer this question. The RAFT benchmark (Real-world Annotated Few-shot Tasks) focuses on naturally occurring tasks and uses an evaluation setup that mirrors deployment. Baseline evaluations on RAFT reveal areas current techniques struggle with: reasoning over long texts and tasks with many classes. Human baselines show that some classification tasks are difficult for non-expert humans, reflecting that real-world value sometimes depends on domain expertise. Yet even non-expert human baseline F1 scores exceed GPT-3 by an average of 0.11. The RAFT datasets and leaderboard will track which model improvements translate into real-world benefits at https://raft.elicit.org .