 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual audio loss function for deep learning
Aug 20, 2017PESQ and POLQA , are standards are standards for automated assessment of voice quality of speech as experienced by human beings. The predictions of those objective measures should come as close as possible to subjective quality scores as obtained in subjective listening tests. Wavenet is a deep neural network originally developed as a deep generative model of raw audio wave-forms. Wavenet architecture is based on dilated causal convolutions, which exhibit very large receptive fields. In this short paper we suggest using the Wavenet architecture, in particular its large receptive filed in order to learn PESQ algorithm. By doing so we can use it as a differentiable loss function for speech enhancement.
Compressed Learning: A Deep Neural Network Approach
Oct 30, 2016
Compressed Learning (CL) is a joint signal processing and machine learning framework for inference from a signal, using a small number of measurements obtained by linear projections of the signal. In this paper we present an end-to-end deep learning approach for CL, in which a network composed of fully-connected layers followed by convolutional layers perform the linear sensing and non-linear inference stages. During the training phase, the sensing matrix and the non-linear inference operator are jointly optimized, and the proposed approach outperforms state-of-the-art for the task of image classification. For example, at a sensing rate of 1% (only 8 measurements of 28 X 28 pixels images), the classification error for the MNIST handwritten digits dataset is 6.46% compared to 41.06% with state-of-the-art.
SEBOOST - Boosting Stochastic Learning Using Subspace Optimization Techniques
Sep 02, 2016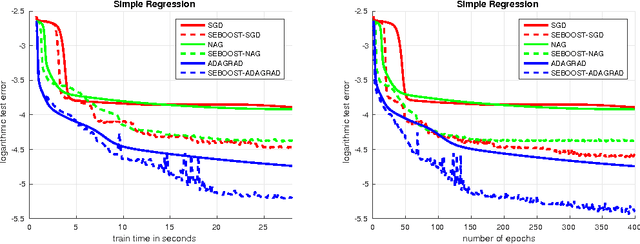

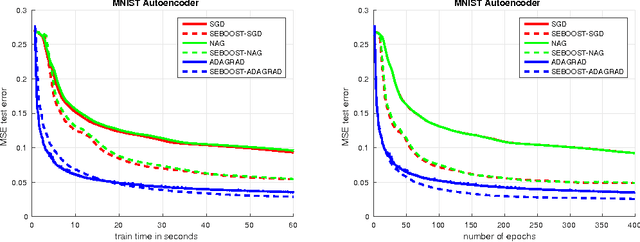
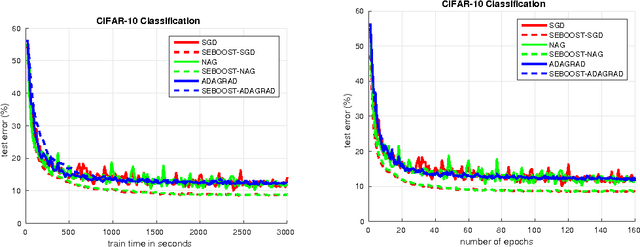
We present SEBOOST, a technique for boosting the performance of existing stochastic optimization methods. SEBOOST applies a secondary optimization process in the subspace spanned by the last steps and descent directions. The method was inspired by the SESOP optimization method for large-scale problems, and has been adapted for the stochastic learning framework. It can be applied on top of any existing optimization method with no need to tweak the internal algorithm. We show that the method is able to boost the performance of different algorithms, and make them more robust to changes in their hyper-parameters. As the boosting steps of SEBOOST are applied between large sets of descent steps, the additional subspace optimization hardly increases the overall computational burden. We introduce two hyper-parameters that control the balance between the baseline method and the secondary optimization process. The method was evaluated on several deep learning tasks, demonstrating promising results.
A Deep Learning Approach to Block-based Compressed Sensing of Images
Jun 05, 2016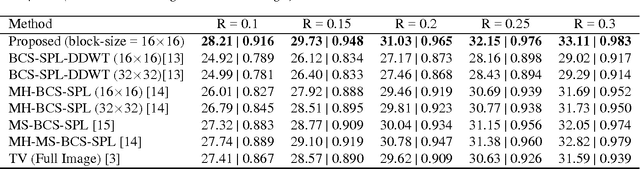



Compressed sensing (CS) is a signal processing framework for efficiently reconstructing a signal from a small number of measurements, obtained by linear projections of the signal. Block-based CS is a lightweight CS approach that is mostly suitable for processing very high-dimensional images and videos: it operates on local patches, employs a low-complexity reconstruction operator and requires significantly less memory to store the sensing matrix. In this paper we present a deep learning approach for block-based CS, in which a fully-connected network performs both the block-based linear sensing and non-linear reconstruction stages. During the training phase, the sensing matrix and the non-linear reconstruction operator are \emph{jointly} optimized, and the proposed approach outperforms state-of-the-art both in terms of reconstruction quality and computation time. For example, at a 25% sensing rate the average PSNR advantage is 0.77dB and computation time is over 200-times faster.
Trainlets: Dictionary Learning in High Dimensions
May 12, 2016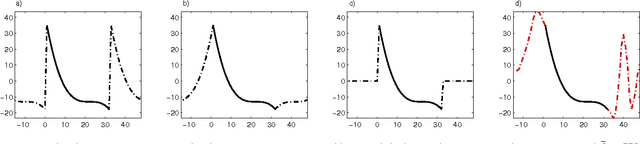
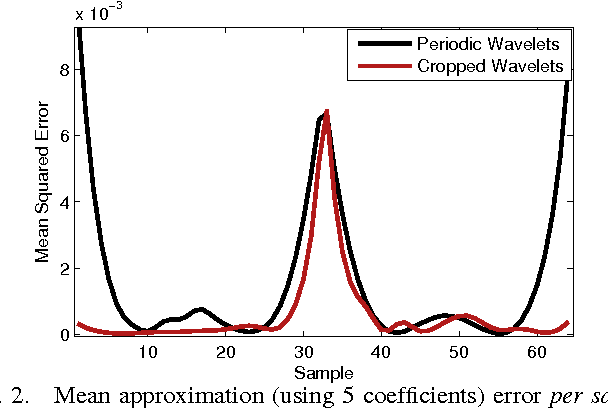

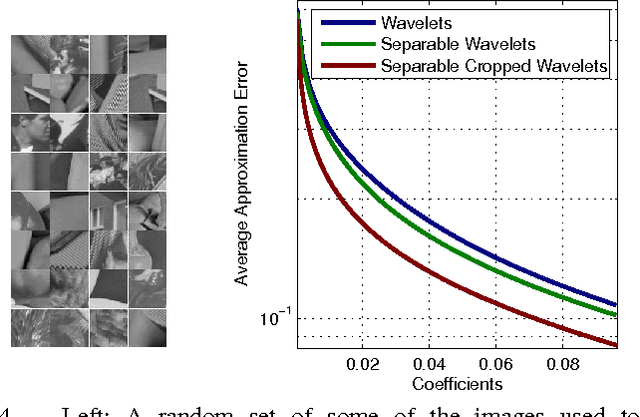
Sparse representations has shown to be a very powerful model for real world signals, and has enabled the development of applications with notable performance. Combined with the ability to learn a dictionary from signal examples, sparsity-inspired algorithms are often achieving state-of-the-art results in a wide variety of tasks. Yet, these methods have traditionally been restricted to small dimensions mainly due to the computational constraints that the dictionary learning problem entails. In the context of image processing, this implies handling small image patches. In this work we show how to efficiently handle bigger dimensions and go beyond the small patches in sparsity-based signal and image processing methods. We build our approach based on a new cropped wavelet decomposition, which enables a multi-scale analysis with virtually no border effects. We then employ this as the base dictionary within a double sparsity model to enable the training of adaptive dictionaries. To cope with the increase of training data, while at the same time improving the training performance, we present an Online Sparse Dictionary Learning (OSDL) algorithm to train this model effectively, enabling it to handle millions of examples. This work shows that dictionary learning can be up-scaled to tackle a new level of signal dimensions, obtaining large adaptable atoms that we call trainlets.
Patch-Ordering as a Regularization for Inverse Problems in Image Processing
Feb 26, 2016


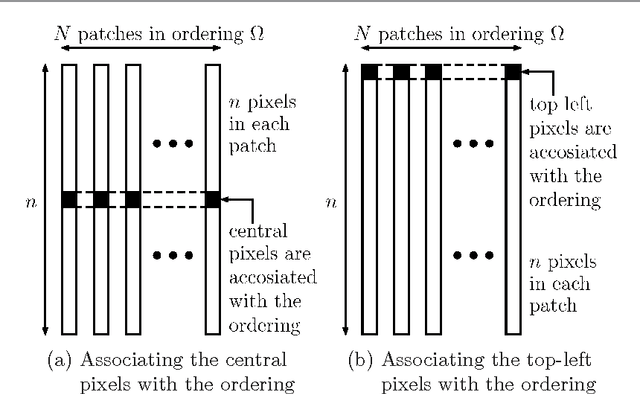
Recent work in image processing suggests that operating on (overlapping) patches in an image may lead to state-of-the-art results. This has been demonstrated for a variety of problems including denoising, inpainting, deblurring, and super-resolution. The work reported in [1,2] takes an extra step forward by showing that ordering these patches to form an approximate shortest path can be leveraged for better processing. The core idea is to apply a simple filter on the resulting 1D smoothed signal obtained after the patch-permutation. This idea has been also explored in combination with a wavelet pyramid, leading eventually to a sophisticated and highly effective regularizer for inverse problems in imaging. In this work we further study the patch-permutation concept, and harness it to propose a new simple yet effective regularization for image restoration problems. Our approach builds on the classic Maximum A'posteriori probability (MAP), with a penalty function consisting of a regular log-likelihood term and a novel permutation-based regularization term. Using a plain 1D Laplacian, the proposed regularization forces robust smoothness (L1) on the permuted pixels. Since the permutation originates from patch-ordering, we propose to accumulate the smoothness terms over all the patches' pixels. Furthermore, we take into account the found distances between adjacent patches in the ordering, by weighting the Laplacian outcome. We demonstrate the proposed scheme on a diverse set of problems: (i) severe Poisson image denoising, (ii) Gaussian image denoising, (iii) image deblurring, and (iv) single image super-resolution. In all these cases, we use recent methods that handle these problems as initialization to our scheme. This is followed by an L-BFGS optimization of the above-described penalty function, leading to state-of-the-art results, and especially so for highly ill-posed cases.
Speeding-Up Convergence via Sequential Subspace Optimization: Current State and Future Directions
Dec 31, 2013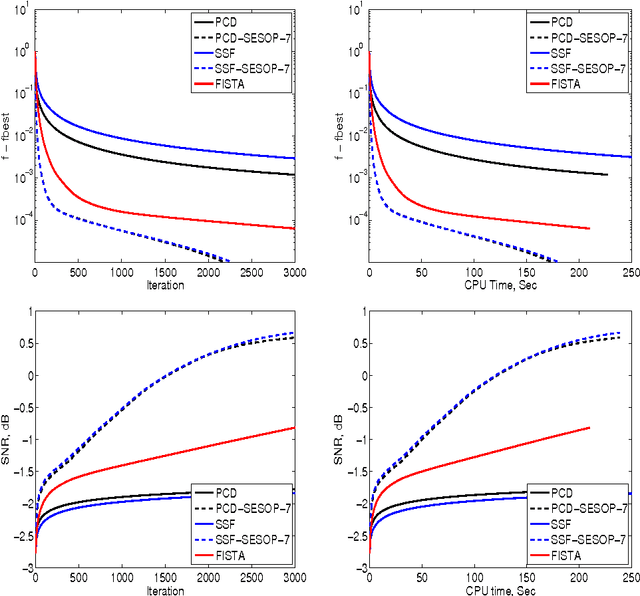
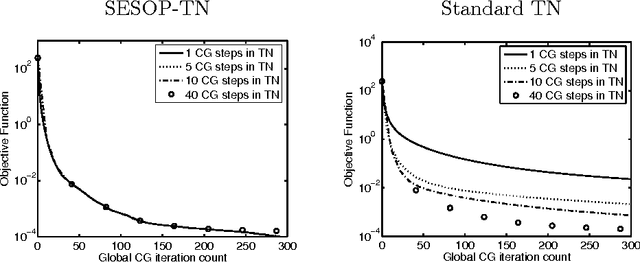
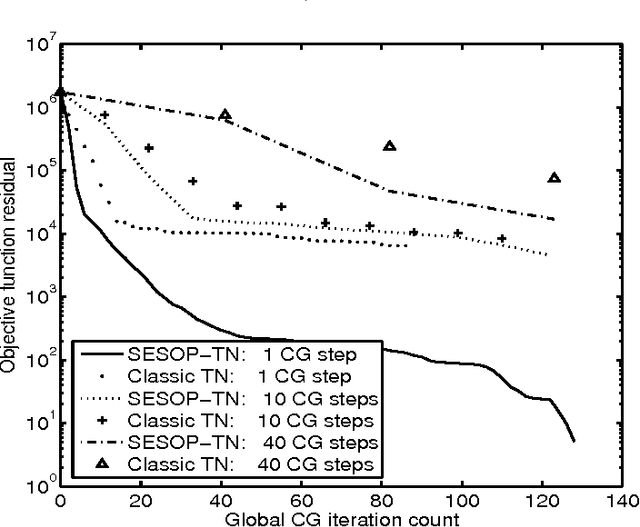
This is an overview paper written in style of research proposal. In recent years we introduced a general framework for large-scale unconstrained optimization -- Sequential Subspace Optimization (SESOP) and demonstrated its usefulness for sparsity-based signal/image denoising, deconvolution, compressive sensing, computed tomography, diffraction imaging, support vector machines. We explored its combination with Parallel Coordinate Descent and Separable Surrogate Function methods, obtaining state of the art results in above-mentioned areas. There are several methods, that are faster than plain SESOP under specific conditions: Trust region Newton method - for problems with easily invertible Hessian matrix; Truncated Newton method - when fast multiplication by Hessian is available; Stochastic optimization methods - for problems with large stochastic-type data; Multigrid methods - for problems with nested multilevel structure. Each of these methods can be further improved by merge with SESOP. One can also accelerate Augmented Lagrangian method for constrained optimization problems and Alternating Direction Method of Multipliers for problems with separable objective function and non-separable constraints.
Spatially-Adaptive Reconstruction in Computed Tomography using Neural Networks
Nov 28, 2013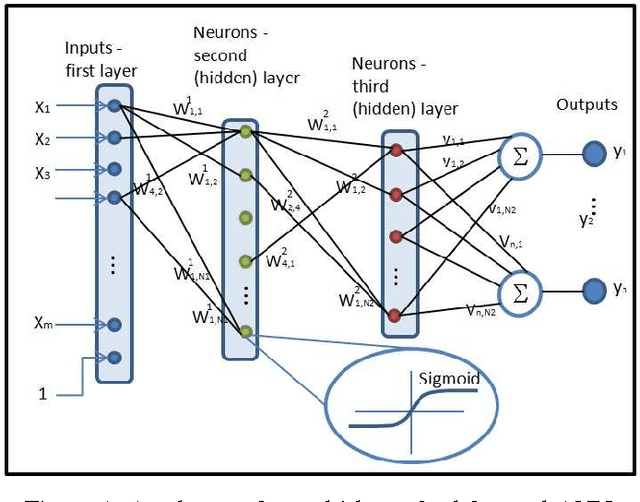
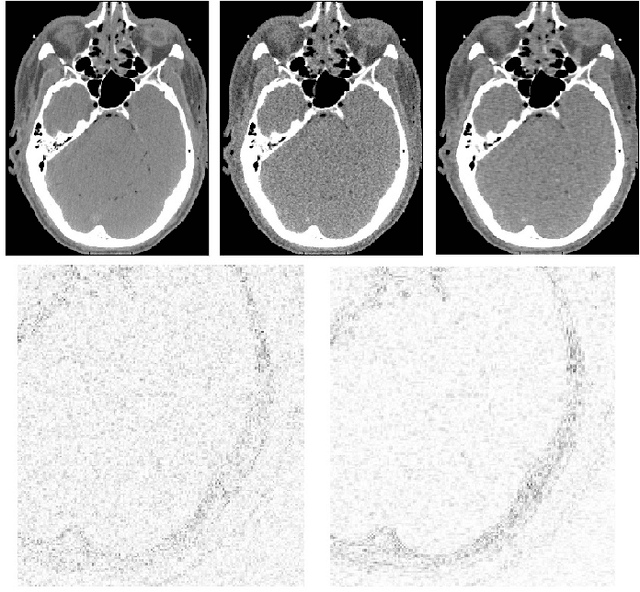
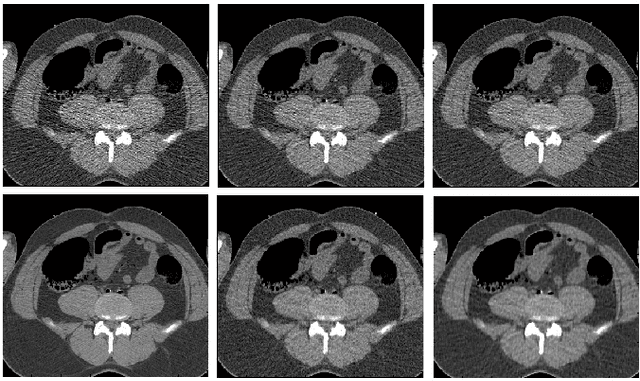
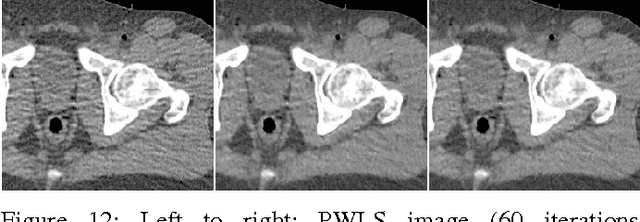
We propose a supervised machine learning approach for boosting existing signal and image recovery methods and demonstrate its efficacy on example of image reconstruction in computed tomography. Our technique is based on a local nonlinear fusion of several image estimates, all obtained by applying a chosen reconstruction algorithm with different values of its control parameters. Usually such output images have different bias/variance trade-off. The fusion of the images is performed by feed-forward neural network trained on a set of known examples. Numerical experiments show an improvement in reconstruction quality relatively to existing direct and iterative reconstruction methods.
Spatially-Adaptive Reconstruction in Computed Tomography Based on Statistical Learning
Apr 25, 2010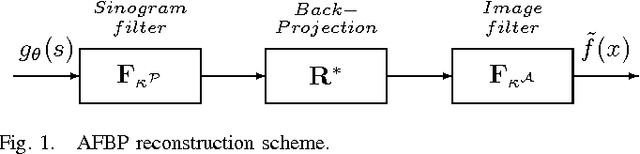
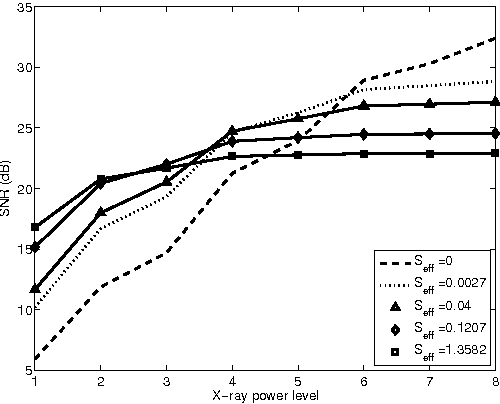
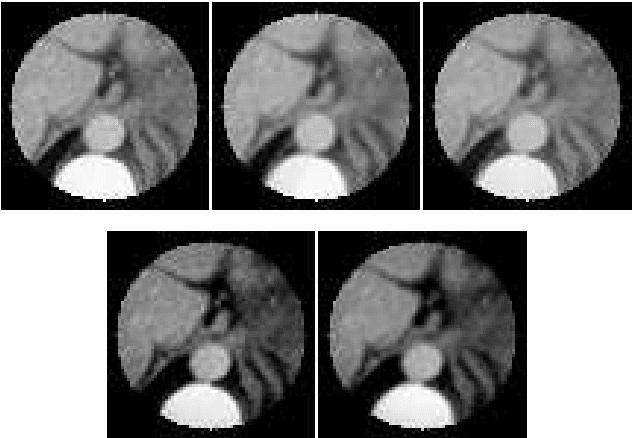
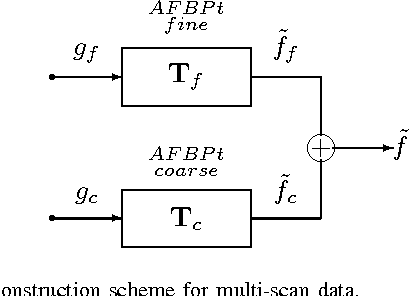
We propose a direct reconstruction algorithm for Computed Tomography, based on a local fusion of a few preliminary image estimates by means of a non-linear fusion rule. One such rule is based on a signal denoising technique which is spatially adaptive to the unknown local smoothness. Another, more powerful fusion rule, is based on a neural network trained off-line with a high-quality training set of images. Two types of linear reconstruction algorithms for the preliminary images are employed for two different reconstruction tasks. For an entire image reconstruction from full projection data, the proposed scheme uses a sequence of Filtered Back-Projection algorithms with a gradually growing cut-off frequency. To recover a Region Of Interest only from local projections, statistically-trained linear reconstruction algorithms are employed. Numerical experiments display the improvement in reconstruction quality when compared to linear reconstruction algorithms.