 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural-Symbolic Framework for Mental Simulation
Aug 05, 2020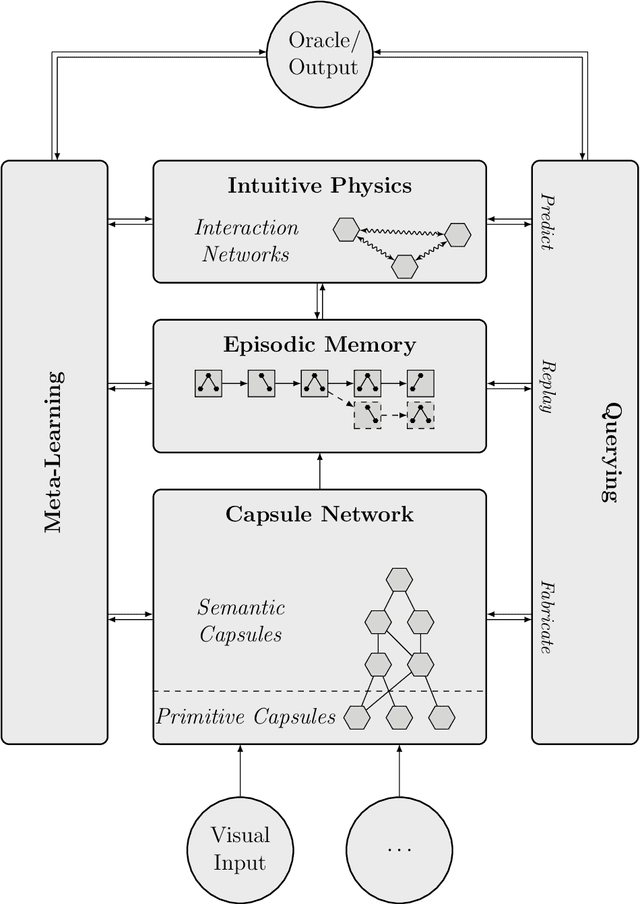
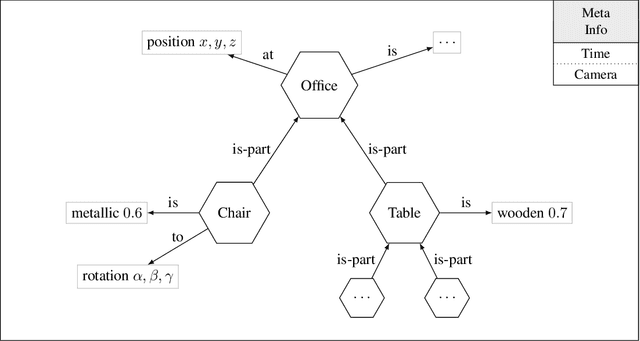
We present a neural-symbolic framework for observing the environment and continuously learning visual semantics and intuitive physics to reproduce them in an interactive simulation. The framework consists of five parts, a neural-symbolic hybrid network based on capsules for inverse graphics, an episodic memory to store observations, an interaction network for intuitive physics, a meta-learning agent that continuously improves the framework and a querying language that acts as the framework's interface for simulation. By means of lifelong meta-learning, the capsule network is expanded and trained continuously, in order to better adapt to its environment with each iteration. This enables it to learn new semantics using a few-shot approach and with minimal input from an oracle over its lifetime. From what it learned through observation, the part for intuitive physics infers all the required physical properties of the objects in a scene, enabling predictions. Finally, a custom query language ties all parts together, which allows to perform various mental simulation tasks, such as navigation, sorting and simulation of a game environment, with which we illustrate the potential of our novel approach.
Hacking Neural Networks: A Short Introduction
Dec 01, 2019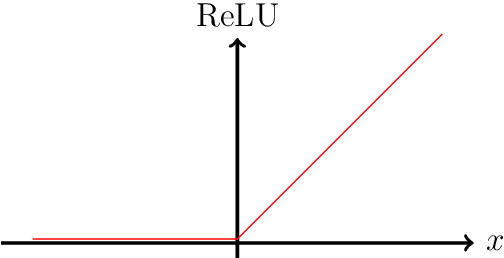

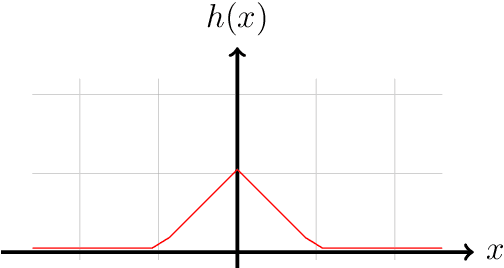
A large chunk of research on the security issues of neural networks is focused on adversarial attacks. However, there exists a vast sea of simpler attacks one can perform both against and with neural networks. In this article, we give a quick introduction on how deep learning in security works and explore the basic methods of exploitation, but also look at the offensive capabilities deep learning enabled tools provide. All presented attacks, such as backdooring, GPU-based buffer overflows or automated bug hunting, are accompanied by short open-source exercises for anyone to try out.
Adding Intuitive Physics to Neural-Symbolic Capsules Using Interaction Networks
May 23, 2019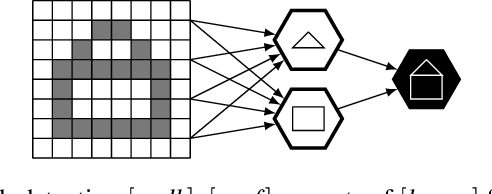


Many current methods to learn intuitive physics are based on interaction networks and similar approaches. However, they rely on information that has proven difficult to estimate directly from image data in the past. We aim to narrow this gap by inferring all the semantic information needed from raw pixel data in the form of a scene-graph. Our approach is based on neural-symbolic capsules, which identify which objects in the scene are static, dynamic, elastic or rigid, possible joints between them, as well as their collision information. By integrating all this with interaction networks, we demonstrate how our method is able to learn intuitive physics directly from image sequences and apply its knowledge to new scenes and objects, resulting in an inverse-simulation pipeline.
A Neural-Symbolic Architecture for Inverse Graphics Improved by Lifelong Meta-Learning
May 22, 2019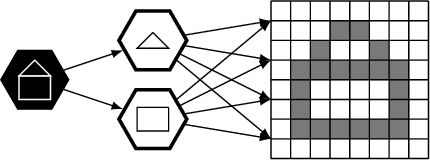

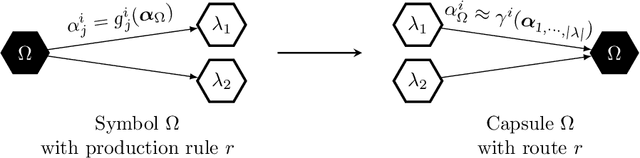
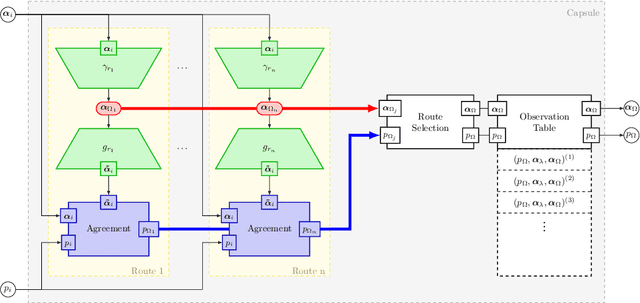
We follow the idea of formulating vision as inverse graphics and propose a new type of element for this task, a neural-symbolic capsule. It is capable of de-rendering a scene into semantic information feed-forward, as well as rendering it feed-backward. An initial set of capsules for graphical primitives is obtained from a generative grammar and connected into a full capsule network. Lifelong meta-learning continuously improves this network's detection capabilities by adding capsules for new and more complex objects it detects in a scene using few-shot learning. Preliminary results demonstrate the potential of our novel approach.