 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCALVIS: chest, waist and pelvis circumference from 3D human body meshes as ground truth for deep learning
Feb 12, 2020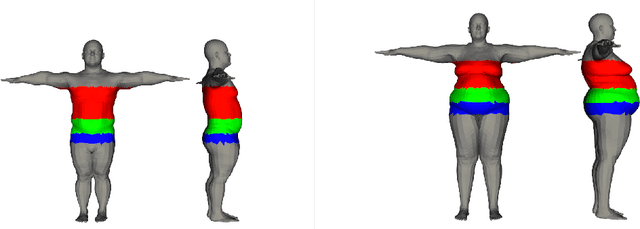
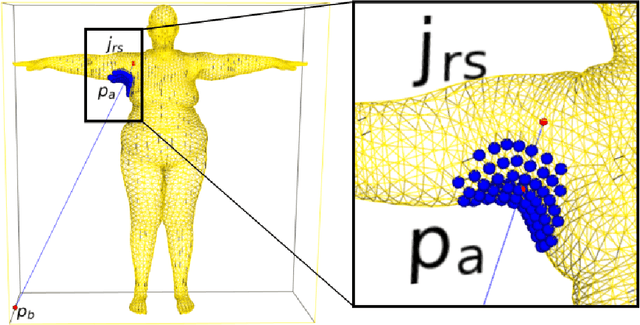
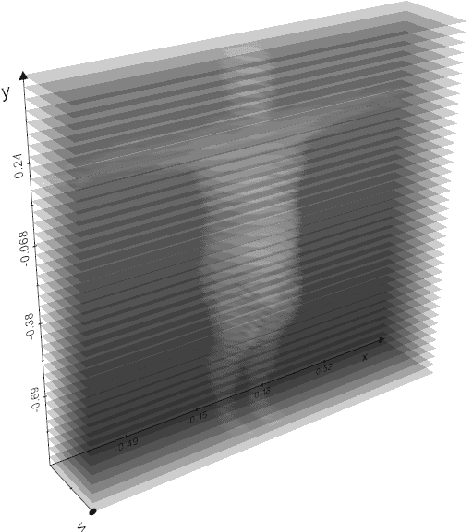
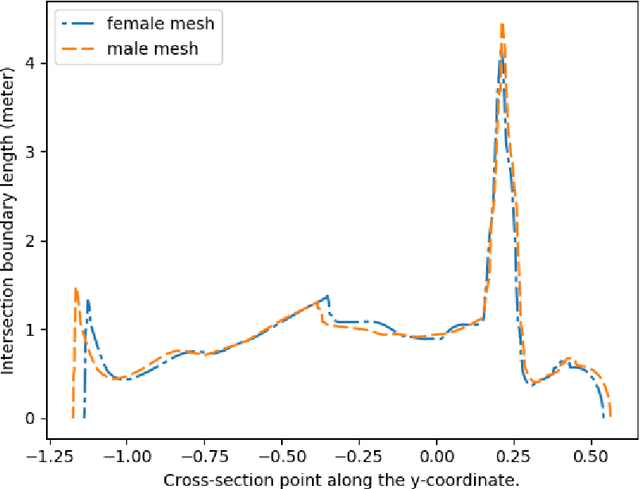
In this paper we present CALVIS, a method to calculate $\textbf{C}$hest, w$\textbf{A}$ist and pe$\textbf{LVIS}$ circumference from 3D human body meshes. Our motivation is to use this data as ground truth for training convolutional neural networks (CNN). Previous work had used the large scale CAESAR dataset or determined these anthropometrical measurements $\textit{manually}$ from a person or human 3D body meshes. Unfortunately, acquiring these data is a cost and time consuming endeavor. In contrast, our method can be used on 3D meshes automatically. We synthesize eight human body meshes and apply CALVIS to calculate chest, waist and pelvis circumference. We evaluate the results qualitatively and observe that the measurements can indeed be used to estimate the shape of a person. We then asses the plausibility of our approach by generating ground truth with CALVIS to train a small CNN. After having trained the network with our data, we achieve competitive validation error. Furthermore, we make the implementation of CALVIS publicly available to advance the field.
RPBA -- Robust Parallel Bundle Adjustment Based on Covariance Information
Oct 17, 2019
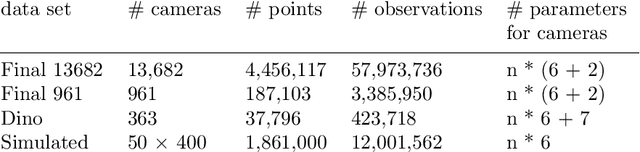


A core component of all Structure from Motion (SfM) approaches is bundle adjustment. As the latter is a computational bottleneck for larger blocks, parallel bundle adjustment has become an active area of research. Particularly, consensus-based optimization methods have been shown to be suitable for this task. We have extended them using covariance information derived by the adjustment of individual three-dimensional (3D) points, i.e., "triangulation" or "intersection". This does not only lead to a much better convergence behavior, but also avoids fiddling with the penalty parameter of standard consensus-based approaches. The corresponding novel approach can also be seen as a variant of resection / intersection schemes, where we adjust during intersection a number of sub-blocks directly related to the number of threads available on a computer each containing a fraction of the cameras of the block. We show that our novel approach is suitable for robust parallel bundle adjustment and demonstrate its capabilities in comparison to the basic consensus-based approach as well as a state-of-the-art parallel implementation of bundle adjustment. Code for our novel approach is available on GitHub: https://github.com/helmayer/RPBA
Adding Intuitive Physics to Neural-Symbolic Capsules Using Interaction Networks
May 23, 2019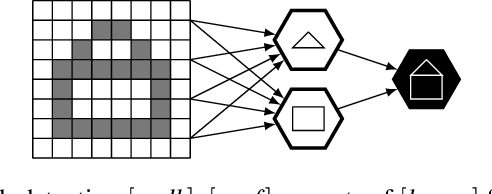


Many current methods to learn intuitive physics are based on interaction networks and similar approaches. However, they rely on information that has proven difficult to estimate directly from image data in the past. We aim to narrow this gap by inferring all the semantic information needed from raw pixel data in the form of a scene-graph. Our approach is based on neural-symbolic capsules, which identify which objects in the scene are static, dynamic, elastic or rigid, possible joints between them, as well as their collision information. By integrating all this with interaction networks, we demonstrate how our method is able to learn intuitive physics directly from image sequences and apply its knowledge to new scenes and objects, resulting in an inverse-simulation pipeline.
A Neural-Symbolic Architecture for Inverse Graphics Improved by Lifelong Meta-Learning
May 22, 2019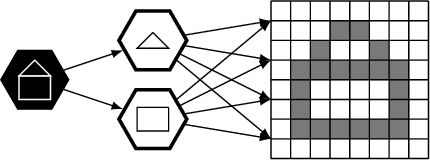

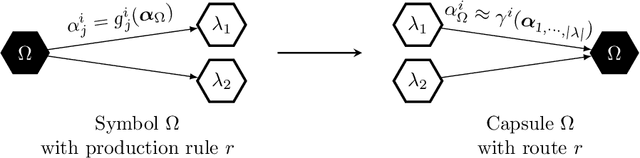
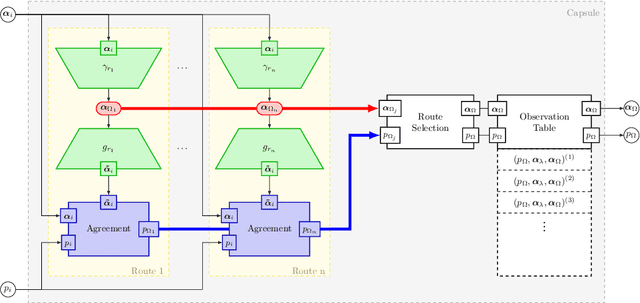
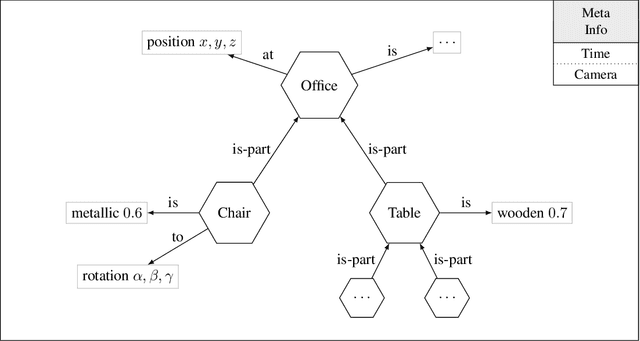
We follow the idea of formulating vision as inverse graphics and propose a new type of element for this task, a neural-symbolic capsule. It is capable of de-rendering a scene into semantic information feed-forward, as well as rendering it feed-backward. An initial set of capsules for graphical primitives is obtained from a generative grammar and connected into a full capsule network. Lifelong meta-learning continuously improves this network's detection capabilities by adding capsules for new and more complex objects it detects in a scene using few-shot learning. Preliminary results demonstrate the potential of our novel approach.