 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminative Multimodal Learning via Conditional Priors in Generative Models
Oct 09, 2021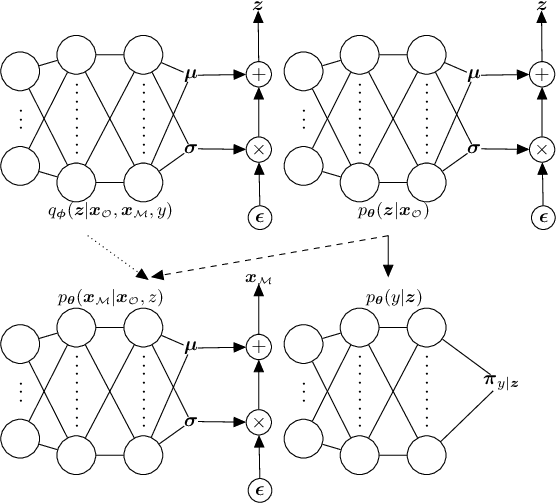
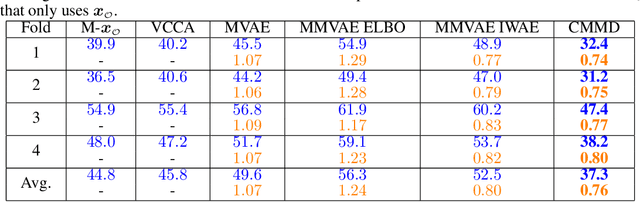
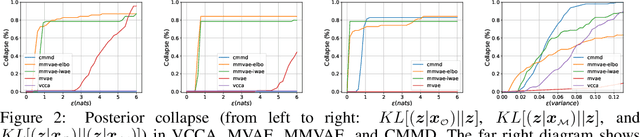
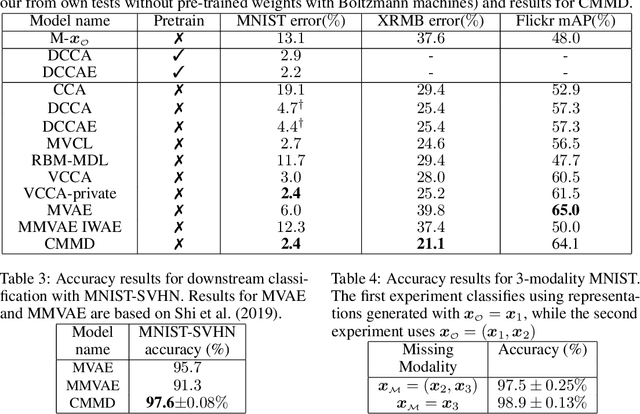
Deep generative models with latent variables have been used lately to learn joint representations and generative processes from multi-modal data. These two learning mechanisms can, however, conflict with each other and representations can fail to embed information on the data modalities. This research studies the realistic scenario in which all modalities and class labels are available for model training, but where some modalities and labels required for downstream tasks are missing. We show, in this scenario, that the variational lower bound limits mutual information between joint representations and missing modalities. We, to counteract these problems, introduce a novel conditional multi-modal discriminative model that uses an informative prior distribution and optimizes a likelihood-free objective function that maximizes mutual information between joint representations and missing modalities. Extensive experimentation shows the benefits of the model we propose, the empirical results showing that our model achieves state-of-the-art results in representative problems such as downstream classification, acoustic inversion and annotation generation.
This looks more like that: Enhancing Self-Explaining Models by Prototypical Relevance Propagation
Aug 27, 2021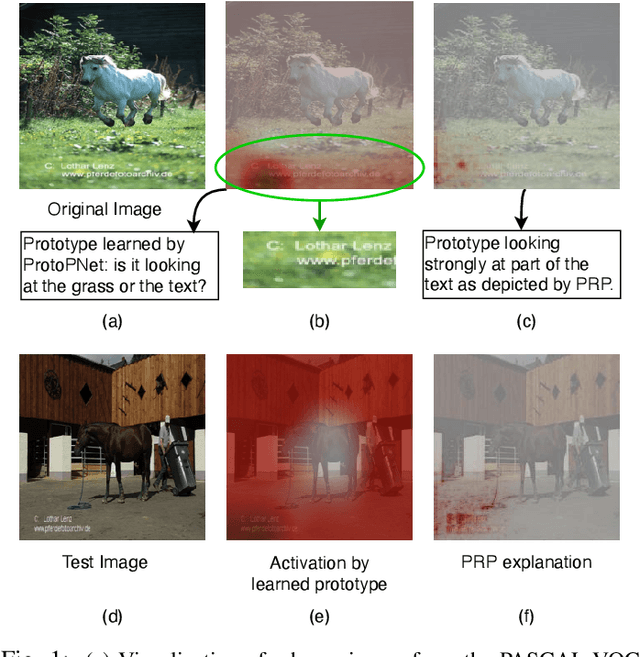
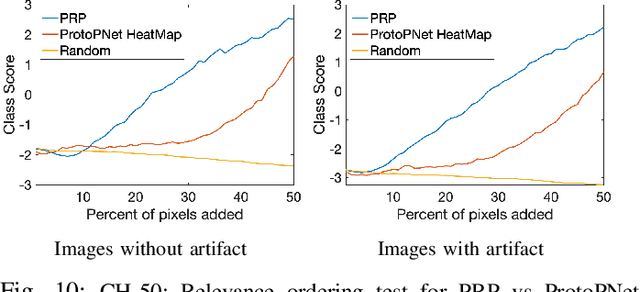

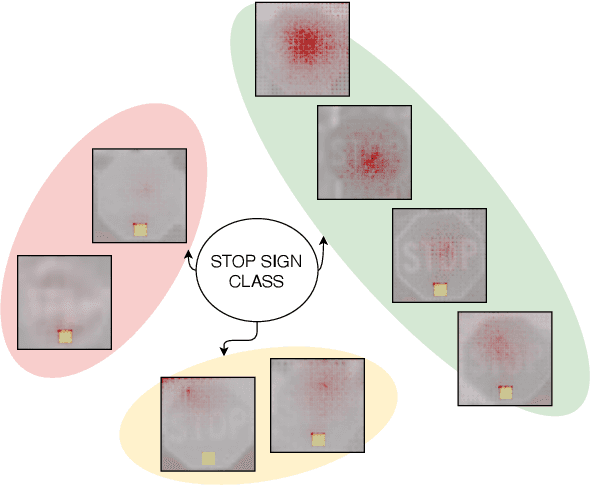
Current machine learning models have shown high efficiency in solving a wide variety of real-world problems. However, their black box character poses a major challenge for the understanding and traceability of the underlying decision-making strategies. As a remedy, many post-hoc explanation and self-explanatory methods have been developed to interpret the models' behavior. These methods, in addition, enable the identification of artifacts that can be learned by the model as class-relevant features. In this work, we provide a detailed case study of the self-explaining network, ProtoPNet, in the presence of a spectrum of artifacts. Accordingly, we identify the main drawbacks of ProtoPNet, especially, its coarse and spatially imprecise explanations. We address these limitations by introducing Prototypical Relevance Propagation (PRP), a novel method for generating more precise model-aware explanations. Furthermore, in order to obtain a clean dataset, we propose to use multi-view clustering strategies for segregating the artifact images using the PRP explanations, thereby suppressing the potential artifact learning in the models.
M3D-VTON: A Monocular-to-3D Virtual Try-On Network
Aug 11, 2021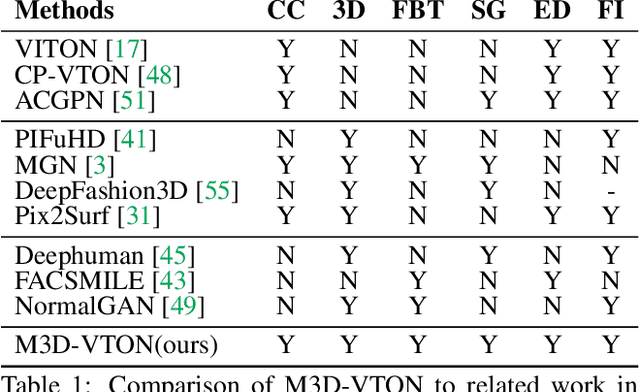
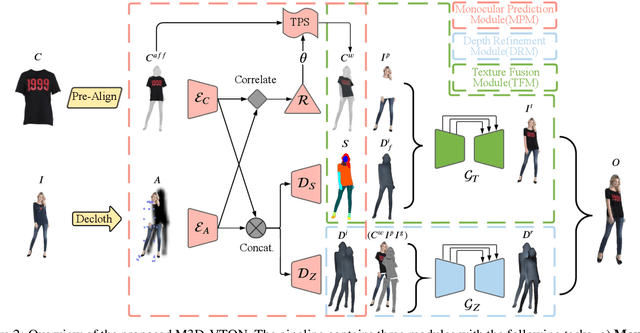
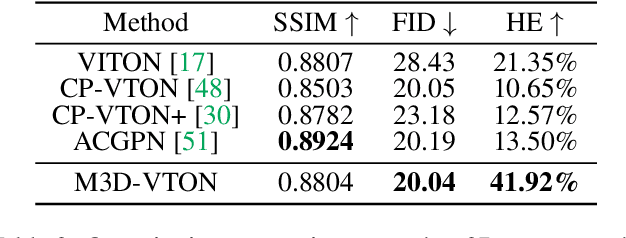
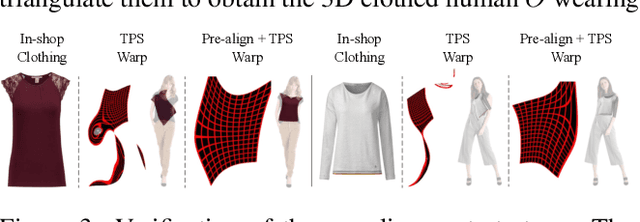
Virtual 3D try-on can provide an intuitive and realistic view for online shopping and has a huge potential commercial value. However, existing 3D virtual try-on methods mainly rely on annotated 3D human shapes and garment templates, which hinders their applications in practical scenarios. 2D virtual try-on approaches provide a faster alternative to manipulate clothed humans, but lack the rich and realistic 3D representation. In this paper, we propose a novel Monocular-to-3D Virtual Try-On Network (M3D-VTON) that builds on the merits of both 2D and 3D approaches. By integrating 2D information efficiently and learning a mapping that lifts the 2D representation to 3D, we make the first attempt to reconstruct a 3D try-on mesh only taking the target clothing and a person image as inputs. The proposed M3D-VTON includes three modules: 1) The Monocular Prediction Module (MPM) that estimates an initial full-body depth map and accomplishes 2D clothes-person alignment through a novel two-stage warping procedure; 2) The Depth Refinement Module (DRM) that refines the initial body depth to produce more detailed pleat and face characteristics; 3) The Texture Fusion Module (TFM) that fuses the warped clothing with the non-target body part to refine the results. We also construct a high-quality synthesized Monocular-to-3D virtual try-on dataset, in which each person image is associated with a front and a back depth map. Extensive experiments demonstrate that the proposed M3D-VTON can manipulate and reconstruct the 3D human body wearing the given clothing with compelling details and is more efficient than other 3D approaches.
Negational Symmetry of Quantum Neural Networks for Binary Pattern Classification
May 20, 2021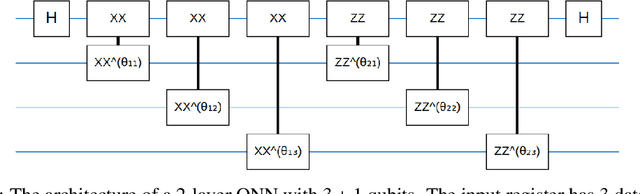
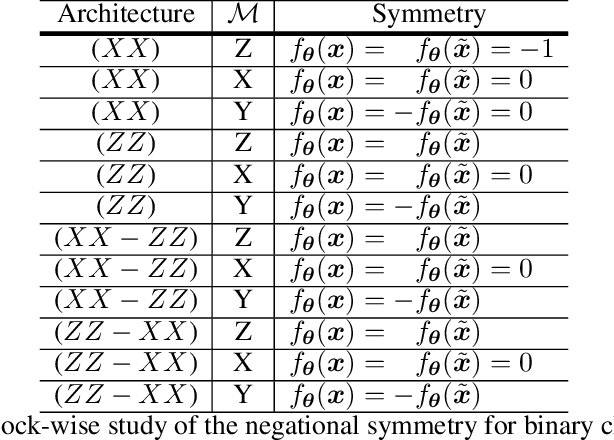
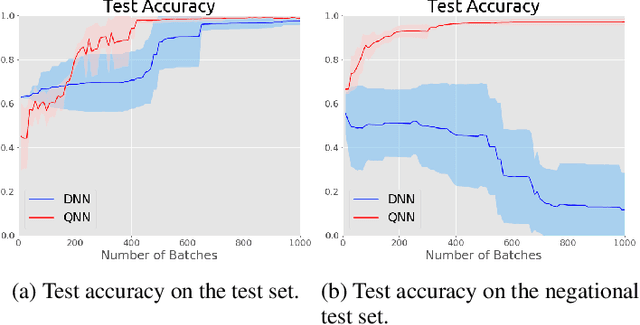
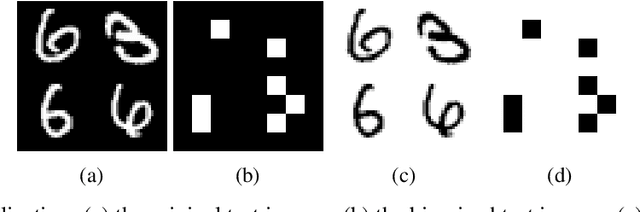
Entanglement is a physical phenomenon, which has fueled recent successes of quantum algorithms. Although quantum neural networks (QNNs) have shown promising results in solving simple machine learning tasks recently, for the time being, the effect of entanglement in QNNs and the behavior of QNNs in binary pattern classification are still underexplored. In this work, we provide some theoretical insight into the properties of QNNs by presenting and analyzing a new form of invariance embedded in QNNs for both quantum binary classification and quantum representation learning, which we term negational symmetry. Given a quantum binary signal and its negational counterpart where a bitwise NOT operation is applied to each quantum bit of the binary signal, a QNN outputs the same logits. That is to say, QNNs cannot differentiate a quantum binary signal and its negational counterpart in a binary classification task. We further empirically evaluate the negational symmetry of QNNs in binary pattern classification tasks using Google's quantum computing framework. The theoretical and experimental results suggest that negational symmetry is a fundamental property of QNNs, which is not shared by classical models. Our findings also imply that negational symmetry is a double-edged sword in practical quantum applications.
Reconsidering Representation Alignment for Multi-view Clustering
Mar 13, 2021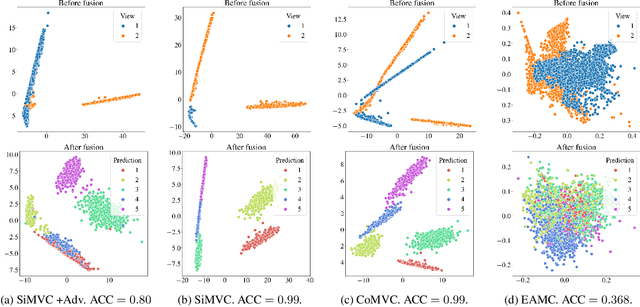
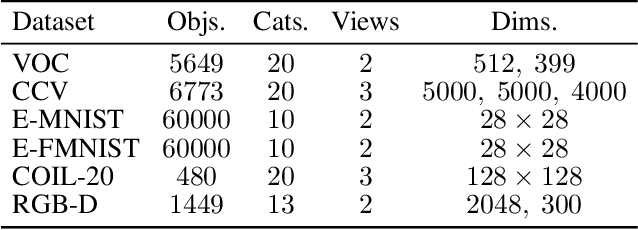
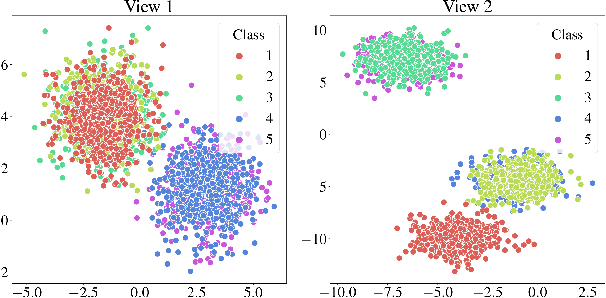
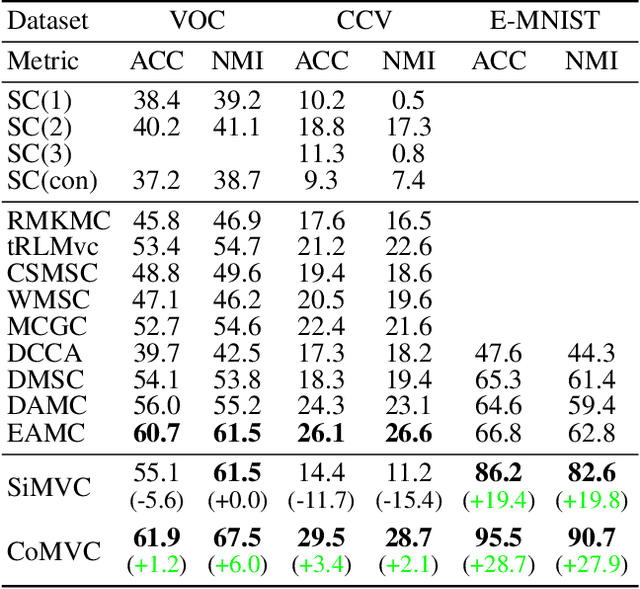
Aligning distributions of view representations is a core component of today's state of the art models for deep multi-view clustering. However, we identify several drawbacks with na\"ively aligning representation distributions. We demonstrate that these drawbacks both lead to less separable clusters in the representation space, and inhibit the model's ability to prioritize views. Based on these observations, we develop a simple baseline model for deep multi-view clustering. Our baseline model avoids representation alignment altogether, while performing similar to, or better than, the current state of the art. We also expand our baseline model by adding a contrastive learning component. This introduces a selective alignment procedure that preserves the model's ability to prioritize views. Our experiments show that the contrastive learning component enhances the baseline model, improving on the current state of the art by a large margin on several datasets.
Joint Optimization of an Autoencoder for Clustering and Embedding
Dec 07, 2020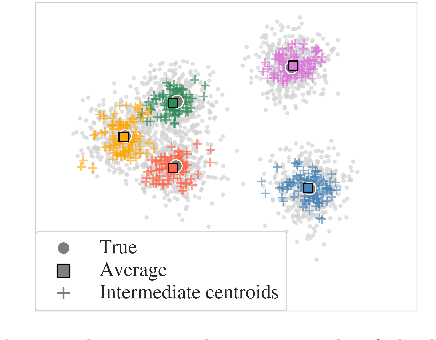
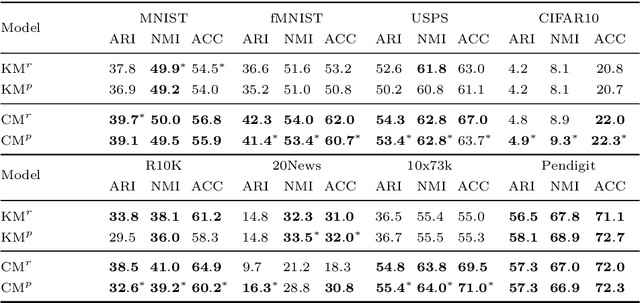
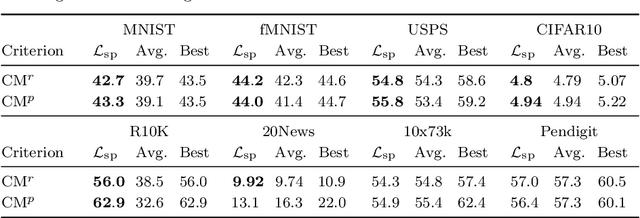
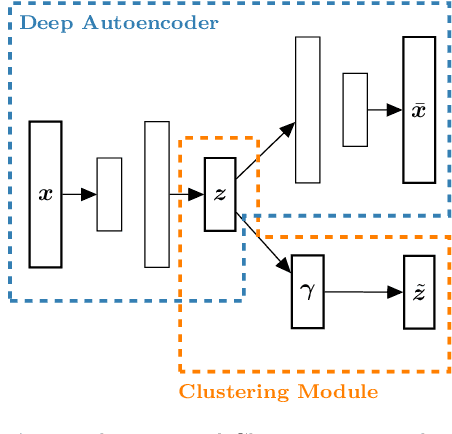
Incorporating k-means-like clustering techniques into (deep) autoencoders constitutes an interesting idea as the clustering may exploit the learned similarities in the embedding to compute a non-linear grouping of data at-hand. Unfortunately, the resulting contributions are often limited by ad-hoc choices, decoupled optimization problems and other issues. We present a theoretically-driven deep clustering approach that does not suffer from these limitations and allows for joint optimization of clustering and embedding. The network in its simplest form is derived from a Gaussian mixture model and can be incorporated seamlessly into deep autoencoders for state-of-the-art performance.
Towards Robust Medical Image Segmentation on Small-Scale Data with Incomplete Labels
Nov 28, 2020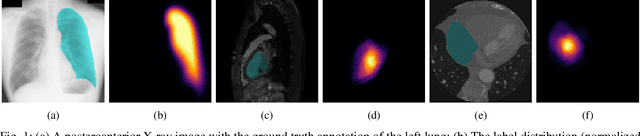

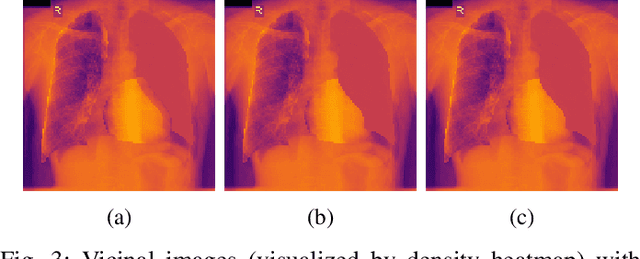
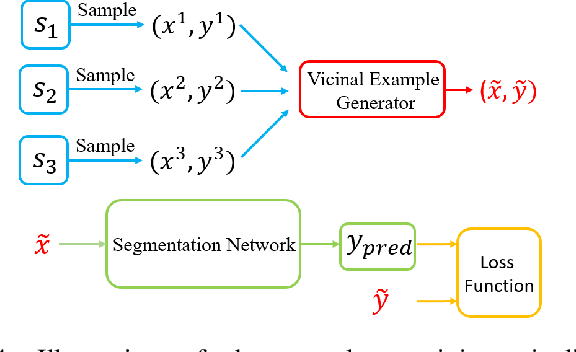
The data-driven nature of deep learning models for semantic segmentation requires a large number of pixel-level annotations. However, large-scale and fully labeled medical datasets are often unavailable for practical tasks. Recently, partially supervised methods have been proposed to utilize images with incomplete labels to mitigate the data scarcity problem in the medical domain. As an emerging research area, the breakthroughs made by existing methods rely on either large-scale data or complex model design, which makes them 1) less practical for certain real-life tasks and 2) less robust for small-scale data. It is time to step back and think about the robustness of partially supervised methods and how to maximally utilize small-scale and partially labeled data for medical image segmentation tasks. To bridge the methodological gaps in label-efficient deep learning with partial supervision, we propose RAMP, a simple yet efficient data augmentation framework for partially supervised medical image segmentation by exploiting the assumption that patients share anatomical similarities. We systematically evaluate RAMP and the previous methods in various controlled multi-structure segmentation tasks. Compared to the mainstream approaches, RAMP consistently improves the performance of traditional segmentation networks on small-scale partially labeled data and utilize additional image-wise weak annotations.
Uncertainty-Aware Deep Ensembles for Reliable and Explainable Predictions of Clinical Time Series
Oct 16, 2020
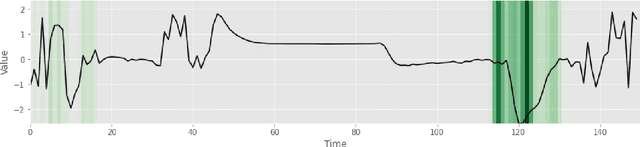
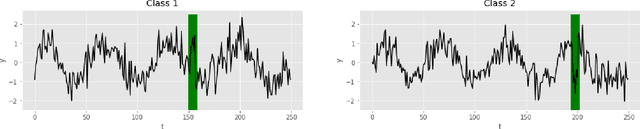
Deep learning-based support systems have demonstrated encouraging results in numerous clinical applications involving the processing of time series data. While such systems often are very accurate, they have no inherent mechanism for explaining what influenced the predictions, which is critical for clinical tasks. However, existing explainability techniques lack an important component for trustworthy and reliable decision support, namely a notion of uncertainty. In this paper, we address this lack of uncertainty by proposing a deep ensemble approach where a collection of DNNs are trained independently. A measure of uncertainty in the relevance scores is computed by taking the standard deviation across the relevance scores produced by each model in the ensemble, which in turn is used to make the explanations more reliable. The class activation mapping method is used to assign a relevance score for each time step in the time series. Results demonstrate that the proposed ensemble is more accurate in locating relevant time steps and is more consistent across random initializations, thus making the model more trustworthy. The proposed methodology paves the way for constructing trustworthy and dependable support systems for processing clinical time series for healthcare related tasks.
SCG-Net: Self-Constructing Graph Neural Networks for Semantic Segmentation
Sep 03, 2020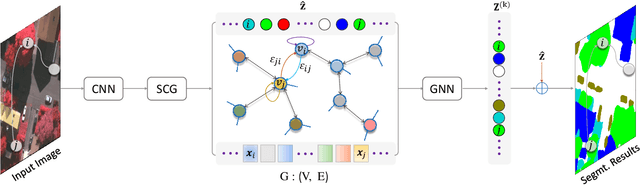
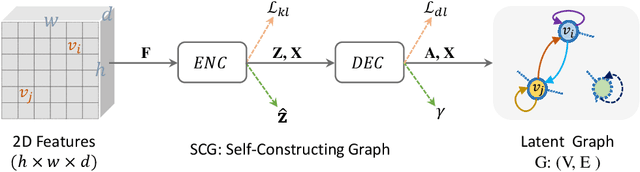
Capturing global contextual representations by exploiting long-range pixel-pixel dependencies has shown to improve semantic segmentation performance. However, how to do this efficiently is an open question as current approaches of utilising attention schemes or very deep models to increase the models field of view, result in complex models with large memory consumption. Inspired by recent work on graph neural networks, we propose the Self-Constructing Graph (SCG) module that learns a long-range dependency graph directly from the image and uses it to propagate contextual information efficiently to improve semantic segmentation. The module is optimised via a novel adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. When incorporated into a neural network (SCG-Net), semantic segmentation is performed in an end-to-end manner and competitive performance (mean F1-scores of 92.0% and 89.8% respectively) on the publicly available ISPRS Potsdam and Vaihingen datasets is achieved, with much fewer parameters, and at a lower computational cost compared to related pure convolutional neural network (CNN) based models.
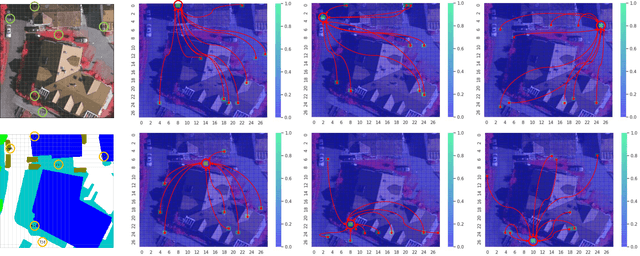
Self-Constructing Graph Convolutional Networks for Semantic Labeling
Apr 23, 2020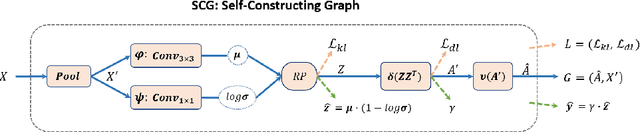
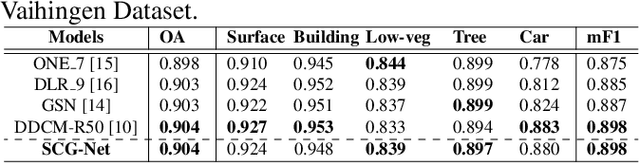
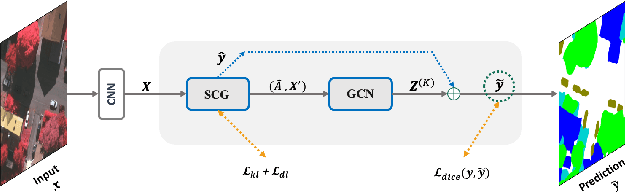
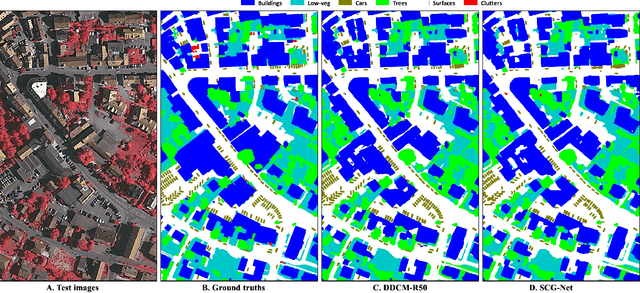
Graph Neural Networks (GNNs) have received increasing attention in many fields. However, due to the lack of prior graphs, their use for semantic labeling has been limited. Here, we propose a novel architecture called the Self-Constructing Graph (SCG), which makes use of learnable latent variables to generate embeddings and to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs. SCG can automatically obtain optimized non-local context graphs from complex-shaped objects in aerial imagery. We optimize SCG via an adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. We demonstrate the effectiveness and flexibility of the proposed SCG on the publicly available ISPRS Vaihingen dataset and our model SCG-Net achieves competitive results in terms of F1-score with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Our code will be made public soon.