 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation of Dependent Expert Distributions in Multimodal Variational Autoencoders
May 02, 2025Multimodal learning with variational autoencoders (VAEs) requires estimating joint distributions to evaluate the evidence lower bound (ELBO). Current methods, the product and mixture of experts, aggregate single-modality distributions assuming independence for simplicity, which is an overoptimistic assumption. This research introduces a novel methodology for aggregating single-modality distributions by exploiting the principle of consensus of dependent experts (CoDE), which circumvents the aforementioned assumption. Utilizing the CoDE method, we propose a novel ELBO that approximates the joint likelihood of the multimodal data by learning the contribution of each subset of modalities. The resulting CoDE-VAE model demonstrates better performance in terms of balancing the trade-off between generative coherence and generative quality, as well as generating more precise log-likelihood estimations. CoDE-VAE further minimizes the generative quality gap as the number of modalities increases. In certain cases, it reaches a generative quality similar to that of unimodal VAEs, which is a desirable property that is lacking in most current methods. Finally, the classification accuracy achieved by CoDE-VAE is comparable to that of state-of-the-art multimodal VAE models.
Learning Latent Representations of Bank Customers With The Variational Autoencoder
Mar 14, 2019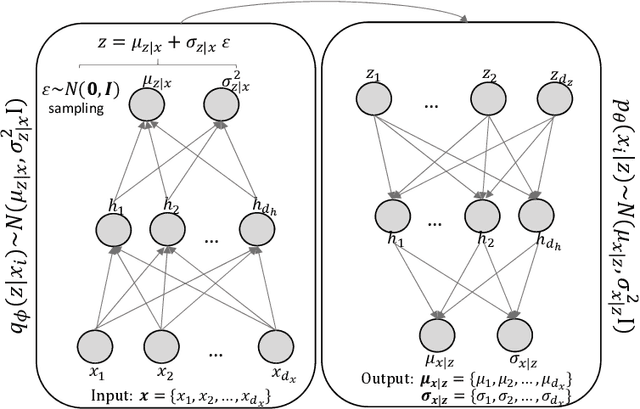
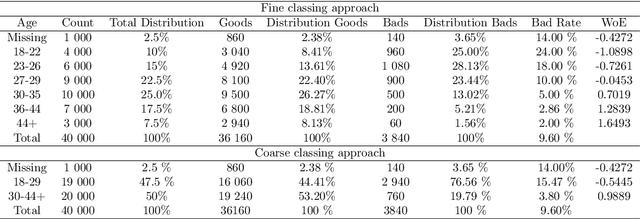
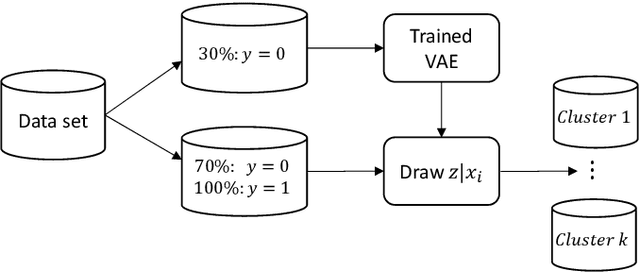

Learning data representations that reflect the customers' creditworthiness can improve marketing campaigns, customer relationship management, data and process management or the credit risk assessment in retail banks. In this research, we adopt the Variational Autoencoder (VAE), which has the ability to learn latent representations that contain useful information. We show that it is possible to steer the latent representations in the latent space of the VAE using the Weight of Evidence and forming a specific grouping of the data that reflects the customers' creditworthiness. Our proposed method learns a latent representation of the data, which shows a well-defied clustering structure capturing the customers' creditworthiness. These clusters are well suited for the aforementioned banks' activities. Further, our methodology generalizes to new customers, captures high-dimensional and complex financial data, and scales to large data sets.