 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Detection of Bad Benchmark Items with Novel Scalability Coefficients
Mar 27, 2026The validity of assessments, from large-scale AI benchmarks to human classrooms, depends on the quality of individual items, yet modern evaluation instruments often contain thousands of items with minimal psychometric vetting. We introduce a new family of nonparametric scalability coefficients based on interitem isotonic regression for efficiently detecting globally bad items (e.g., miskeyed, ambiguously worded, or construct-misaligned). The central contribution is the signed isotonic $R^2$, which measures the maximal proportion of variance in one item explainable by a monotone function of another while preserving the direction of association via Kendall's $τ$. Aggregating these pairwise coefficients yields item-level scores that sharply separate problematic items from acceptable ones without assuming linearity or committing to a parametric item response model. We show that the signed isotonic $R^2$ is extremal among monotone predictors (it extracts the strongest possible monotone signal between any two items) and show that this optimality property translates directly into practical screening power. Across three AI benchmark datasets (HS Math, GSM8K, MMLU) and two human assessment datasets, the signed isotonic $R^2$ consistently achieves top-tier AUC for ranking bad items above good ones, outperforming or matching a comprehensive battery of classical test theory, item response theory, and dimensionality-based diagnostics. Crucially, the method remains robust under the small-n/large-p conditions typical of AI evaluation, requires only bivariate monotone fits computable in seconds, and handles mixed item types (binary, ordinal, continuous) without modification. It is a lightweight, model-agnostic filter that can materially reduce the reviewer effort needed to find flawed items in modern large-scale evaluation regimes.
Autoscoring Anticlimax: A Meta-analytic Understanding of AI's Short-answer Shortcomings and Wording Weaknesses
Mar 05, 2026Automated short-answer scoring lags other LLM applications. We meta-analyze 890 culminating results across a systematic review of LLM short-answer scoring studies, modeling the traditional effect size of Quadratic Weighted Kappa (QWK) with mixed effects metaregression. We quantitatively illustrate that that the level of difficulty for human experts to perform the task of scoring written work of children has no observed statistical effect on LLM performance. Particularly, we show that some scoring tasks measured as the easiest by human scorers were the hardest for LLMs. Whether by poor implementation by thoughtful researchers or patterns traceable to autoregressive training, on average decoder-only architectures underperform encoders by 0.37--a substantial difference in agreement with humans. Additionally, we measure the contributions of various aspects of LLM technology on successful scoring such as tokenizer vocabulary size, which exhibits diminishing returns--potentially due to undertrained tokens. Findings argue for systems design which better anticipates known statistical shortcomings of autoregressive models. Finally, we provide additional experiments to illustrate wording and tokenization sensitivity and bias elicitation in high-stakes education contexts, where LLMs demonstrate racial discrimination. Code and data for this study are available.
Knowledge without Wisdom: Measuring Misalignment between LLMs and Intended Impact
Mar 01, 2026LLMs increasingly excel on AI benchmarks, but doing so does not guarantee validity for downstream tasks. This study evaluates the performance of leading foundation models (FMs, i.e., generative pre-trained base LLMs) with out-of-distribution (OOD) tasks of the teaching and learning of schoolchildren. Across all FMs, inter-model behaviors on disparate tasks correlate higher than they do with expert human behaviors on target tasks. These biases shared across LLMs are poorly aligned with downstream measures of teaching quality and often \textit{negatively aligned with learning outcomes}. Further, we find multi-model ensembles, both unanimous model voting and expert-weighting by benchmark performance, further exacerbate misalignment with learning. We measure that 50\% of the variation in misalignment error is shared across foundation models, suggesting that common pretraining accounts for much of the misalignment in these tasks. We demonstrate methods for robustly measuring alignment of complex tasks and provide unique insights into both educational applications of foundation models and to understanding limitations of models.
Measuring Teaching with LLMs
Oct 27, 2025Objective and scalable measurement of teaching quality is a persistent challenge in education. While Large Language Models (LLMs) offer potential, general-purpose models have struggled to reliably apply complex, authentic classroom observation instruments. This paper uses custom LLMs built on sentence-level embeddings, an architecture better suited for the long-form, interpretive nature of classroom transcripts than conventional subword tokenization. We systematically evaluate five different sentence embeddings under a data-efficient training regime designed to prevent overfitting. Our results demonstrate that these specialized models can achieve human-level and even super-human performance with expert human ratings above 0.65 and surpassing the average human-human rater correlation. Further, through analysis of annotation context windows, we find that more advanced models-those better aligned with human judgments-attribute a larger share of score variation to lesson-level features rather than isolated utterances, challenging the sufficiency of single-turn annotation paradigms. Finally, to assess external validity, we find that aggregate model scores align with teacher value-added measures, indicating they are capturing features relevant to student learning. However, this trend does not hold at the individual item level, suggesting that while the models learn useful signals, they have not yet achieved full generalization. This work establishes a viable and powerful new methodology for AI-driven instructional measurement, offering a path toward providing scalable, reliable, and valid feedback for educator development.
"All that Glitters": Approaches to Evaluations with Unreliable Model and Human Annotations
Nov 23, 2024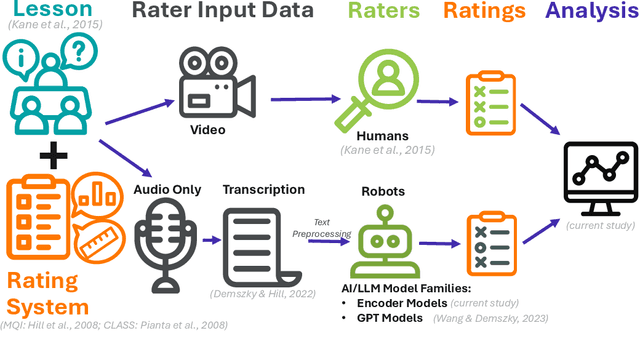



"Gold" and "ground truth" human-mediated labels have error. The effects of this error can escape commonly reported metrics of label quality or obscure questions of accuracy, bias, fairness, and usefulness during model evaluation. This study demonstrates methods for answering such questions even in the context of very low reliabilities from expert humans. We analyze human labels, GPT model ratings, and transformer encoder model annotations describing the quality of classroom teaching, an important, expensive, and currently only human task. We answer the question of whether such a task can be automated using two Large Language Model (LLM) architecture families--encoders and GPT decoders, using novel approaches to evaluating label quality across six dimensions: Concordance, Confidence, Validity, Bias, Fairness, and Helpfulness. First, we demonstrate that using standard metrics in the presence of poor labels can mask both label and model quality: the encoder family of models achieve state-of-the-art, even "super-human", results across all classroom annotation tasks. But not all these positive results remain after using more rigorous evaluation measures which reveal spurious correlations and nonrandom racial biases across models and humans. This study then expands these methods to estimate how model use would change to human label quality if models were used in a human-in-the-loop context, finding that the variance captured in GPT model labels would worsen reliabilities for humans influenced by these models. We identify areas where some LLMs, within the generalizability of the current data, could improve the quality of expensive human ratings of classroom instruction.