 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-aware Pedestrian Trajectory Prediction with Multimodal Transformer
Jul 07, 2023



We propose a novel solution for predicting future trajectories of pedestrians. Our method uses a multimodal encoder-decoder transformer architecture, which takes as input both pedestrian locations and ego-vehicle speeds. Notably, our decoder predicts the entire future trajectory in a single-pass and does not perform one-step-ahead prediction, which makes the method effective for embedded edge deployment. We perform detailed experiments and evaluate our method on two popular datasets, PIE and JAAD. Quantitative results demonstrate the superiority of our proposed model over the current state-of-the-art, which consistently achieves the lowest error for 3 time horizons of 0.5, 1.0 and 1.5 seconds. Moreover, the proposed method is significantly faster than the state-of-the-art for the two datasets of PIE and JAAD. Lastly, ablation experiments demonstrate the impact of the key multimodal configuration of our method.
Continual Learning for Out-of-Distribution Pedestrian Detection
Jun 26, 2023



A continual learning solution is proposed to address the out-of-distribution generalization problem for pedestrian detection. While recent pedestrian detection models have achieved impressive performance on various datasets, they remain sensitive to shifts in the distribution of the inference data. Our method adopts and modifies Elastic Weight Consolidation to a backbone object detection network, in order to penalize the changes in the model weights based on their importance towards the initially learned task. We show that when trained with one dataset and fine-tuned on another, our solution learns the new distribution and maintains its performance on the previous one, avoiding catastrophic forgetting. We use two popular datasets, CrowdHuman and CityPersons for our cross-dataset experiments, and show considerable improvements over standard fine-tuning, with a 9% and 18% miss rate percent reduction improvement in the CrowdHuman and CityPersons datasets, respectively.
Can Continual Learning Improve Long-Tailed Recognition? Toward a Unified Framework
Jun 23, 2023



The Long-Tailed Recognition (LTR) problem emerges in the context of learning from highly imbalanced datasets, in which the number of samples among different classes is heavily skewed. LTR methods aim to accurately learn a dataset comprising both a larger Head set and a smaller Tail set. We propose a theorem where under the assumption of strong convexity of the loss function, the weights of a learner trained on the full dataset are within an upper bound of the weights of the same learner trained strictly on the Head. Next, we assert that by treating the learning of the Head and Tail as two separate and sequential steps, Continual Learning (CL) methods can effectively update the weights of the learner to learn the Tail without forgetting the Head. First, we validate our theoretical findings with various experiments on the toy MNIST-LT dataset. We then evaluate the efficacy of several CL strategies on multiple imbalanced variations of two standard LTR benchmarks (CIFAR100-LT and CIFAR10-LT), and show that standard CL methods achieve strong performance gains in comparison to baselines and approach solutions that have been tailor-made for LTR. We also assess the applicability of CL techniques on real-world data by exploring CL on the naturally imbalanced Caltech256 dataset and demonstrate its superiority over state-of-the-art classifiers. Our work not only unifies LTR and CL but also paves the way for leveraging advances in CL methods to tackle the LTR challenge more effectively.
Diffusion Dataset Generation: Towards Closing the Sim2Real Gap for Pedestrian Detection
May 16, 2023



We propose a method that augments a simulated dataset using diffusion models to improve the performance of pedestrian detection in real-world data. The high cost of collecting and annotating data in the real-world has motivated the use of simulation platforms to create training datasets. While simulated data is inexpensive to collect and annotate, it unfortunately does not always closely match the distribution of real-world data, which is known as the sim2real gap. In this paper we propose a novel method of synthetic data creation meant to close the sim2real gap for the challenging pedestrian detection task. Our method uses a diffusion-based architecture to learn a real-world distribution which, once trained, is used to generate datasets. We mix this generated data with simulated data as a form of augmentation and show that training on a combination of generated and simulated data increases average precision by as much as 27.3% for pedestrian detection models in real-world data, compared against training on purely simulated data.
Keypoint Cascade Voting for Point Cloud Based 6DoF Pose Estimation
Oct 14, 2022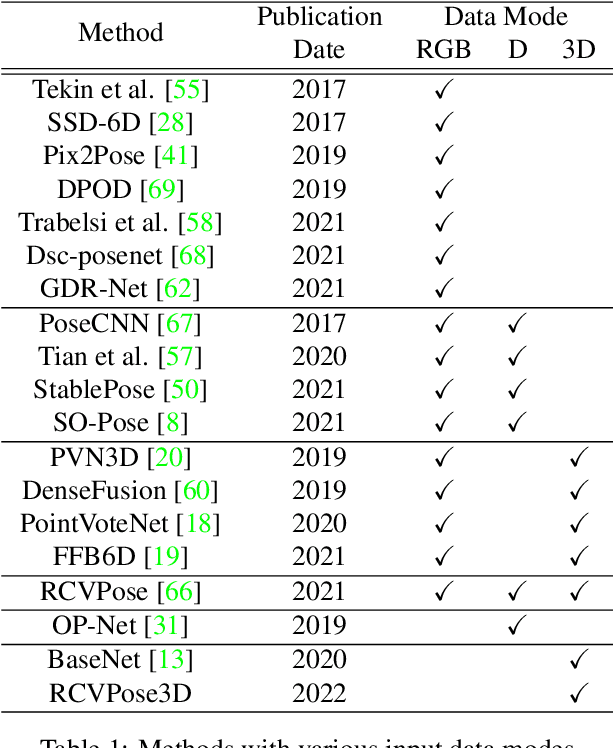
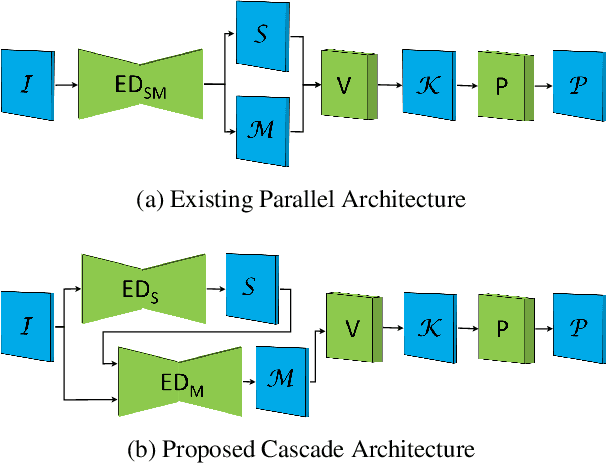
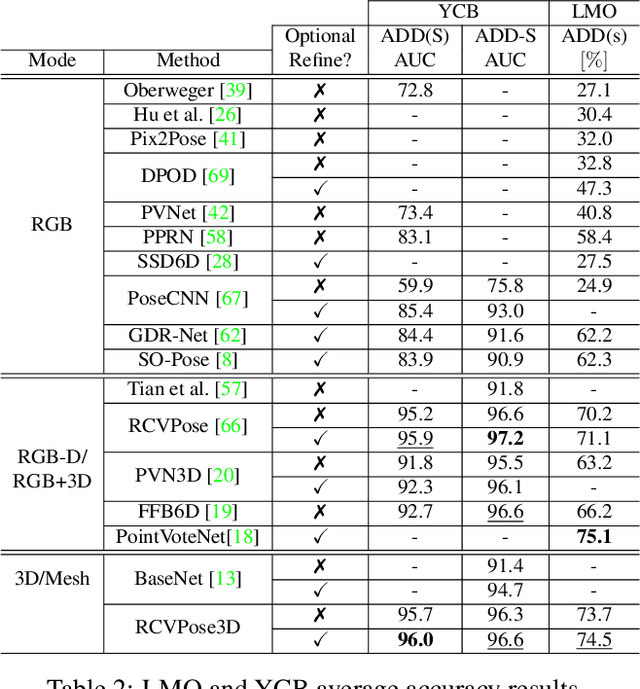
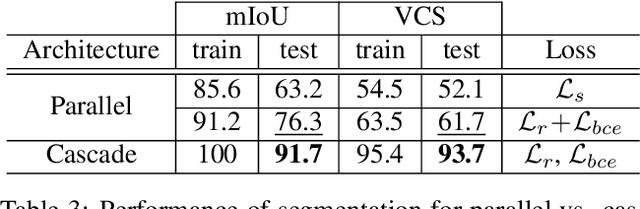
We propose a novel keypoint voting 6DoF object pose estimation method, which takes pure unordered point cloud geometry as input without RGB information. The proposed cascaded keypoint voting method, called RCVPose3D, is based upon a novel architecture which separates the task of semantic segmentation from that of keypoint regression, thereby increasing the effectiveness of both and improving the ultimate performance. The method also introduces a pairwise constraint in between different keypoints to the loss function when regressing the quantity for keypoint estimation, which is shown to be effective, as well as a novel Voter Confident Score which enhances both the learning and inference stages. Our proposed RCVPose3D achieves state-of-the-art performance on the Occlusion LINEMOD (74.5%) and YCB-Video (96.9%) datasets, outperforming existing pure RGB and RGB-D based methods, as well as being competitive with RGB plus point cloud methods.
ObjectBox: From Centers to Boxes for Anchor-Free Object Detection
Jul 14, 2022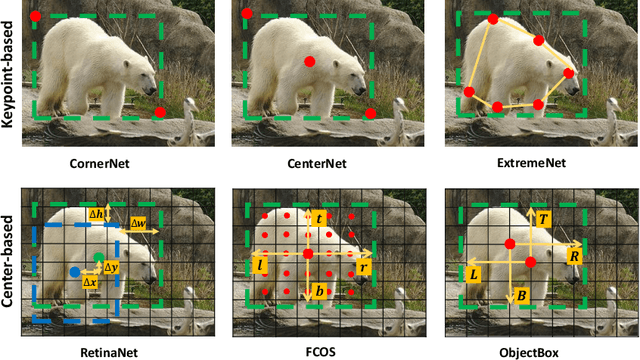
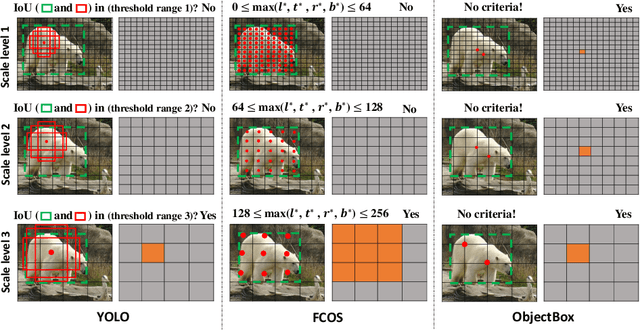
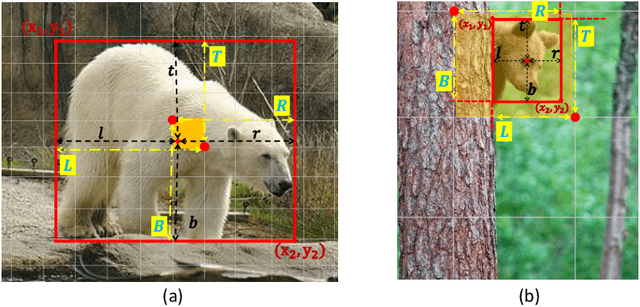
We present ObjectBox, a novel single-stage anchor-free and highly generalizable object detection approach. As opposed to both existing anchor-based and anchor-free detectors, which are more biased toward specific object scales in their label assignments, we use only object center locations as positive samples and treat all objects equally in different feature levels regardless of the objects' sizes or shapes. Specifically, our label assignment strategy considers the object center locations as shape- and size-agnostic anchors in an anchor-free fashion, and allows learning to occur at all scales for every object. To support this, we define new regression targets as the distances from two corners of the center cell location to the four sides of the bounding box. Moreover, to handle scale-variant objects, we propose a tailored IoU loss to deal with boxes with different sizes. As a result, our proposed object detector does not need any dataset-dependent hyperparameters to be tuned across datasets. We evaluate our method on MS-COCO 2017 and PASCAL VOC 2012 datasets, and compare our results to state-of-the-art methods. We observe that ObjectBox performs favorably in comparison to prior works. Furthermore, we perform rigorous ablation experiments to evaluate different components of our method. Our code is available at: https://github.com/MohsenZand/ObjectBox.
Neuro-symbolic Natural Logic with Introspective Revision for Natural Language Inference
Mar 09, 2022


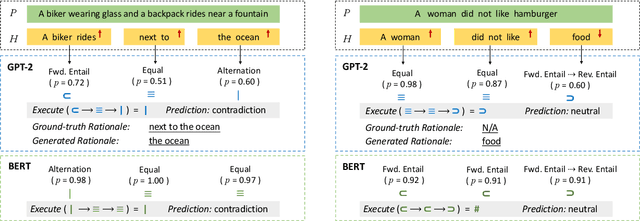
We introduce a neuro-symbolic natural logic framework based on reinforcement learning with introspective revision. The model samples and rewards specific reasoning paths through policy gradient, in which the introspective revision algorithm modifies intermediate symbolic reasoning steps to discover reward-earning operations as well as leverages external knowledge to alleviate spurious reasoning and training inefficiency. The framework is supported by properly designed local relation models to avoid input entangling, which helps ensure the interpretability of the proof paths. The proposed model has built-in interpretability and shows superior capability in monotonicity inference, systematic generalization, and interpretability, compared to previous models on the existing datasets.
Multiscale Crowd Counting and Localization By Multitask Point Supervision
Feb 21, 2022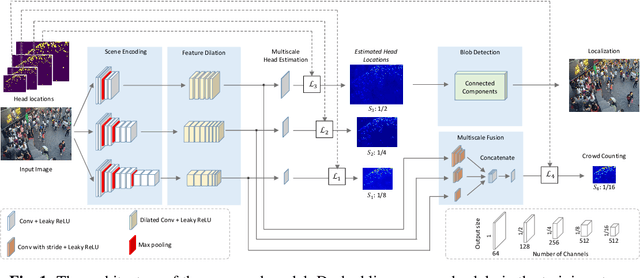
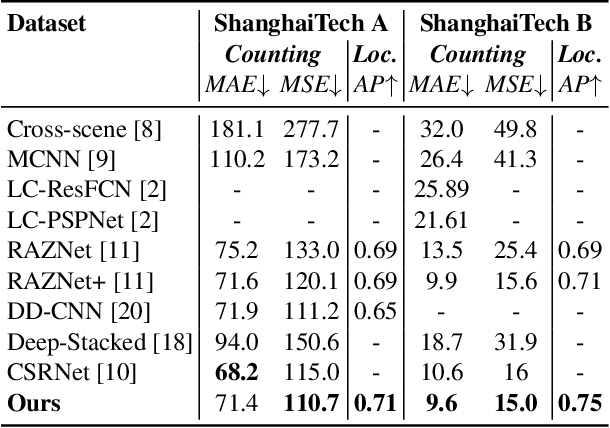

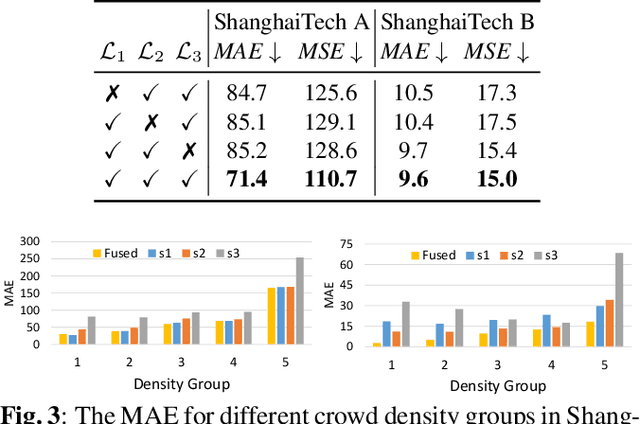
We propose a multitask approach for crowd counting and person localization in a unified framework. As the detection and localization tasks are well-correlated and can be jointly tackled, our model benefits from a multitask solution by learning multiscale representations of encoded crowd images, and subsequently fusing them. In contrast to the relatively more popular density-based methods, our model uses point supervision to allow for crowd locations to be accurately identified. We test our model on two popular crowd counting datasets, ShanghaiTech A and B, and demonstrate that our method achieves strong results on both counting and localization tasks, with MSE measures of 110.7 and 15.0 for crowd counting and AP measures of 0.71 and 0.75 for localization, on ShanghaiTech A and B respectively. Our detailed ablation experiments show the impact of our multiscale approach as well as the effectiveness of the fusion module embedded in our network. Our code is available at: https://github.com/RCVLab-AiimLab/crowd_counting.
Multistream ValidNet: Improving 6D Object Pose Estimation by Automatic Multistream Validation
Jun 12, 2021

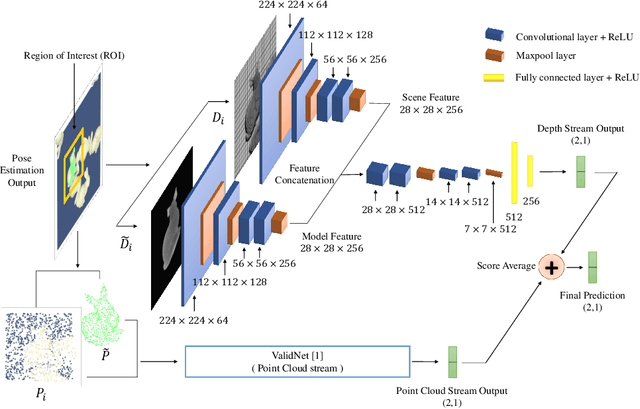

This work presents a novel approach to improve the results of pose estimation by detecting and distinguishing between the occurrence of True and False Positive results. It achieves this by training a binary classifier on the output of an arbitrary pose estimation algorithm, and returns a binary label indicating the validity of the result. We demonstrate that our approach improves upon a state-of-the-art pose estimation result on the Sil\'eane dataset, outperforming a variation of the alternative CullNet method by 4.15% in average class accuracy and 0.73% in overall accuracy at validation. Applying our method can also improve the pose estimation average precision results of Op-Net by 6.06% on average.
Oriented Bounding Boxes for Small and Freely Rotated Objects
Apr 24, 2021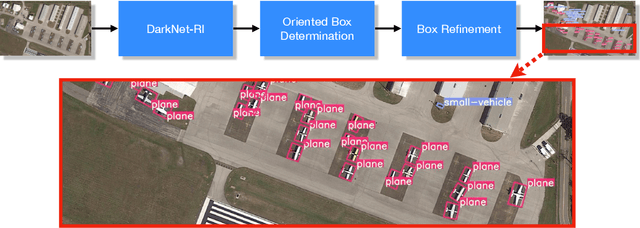
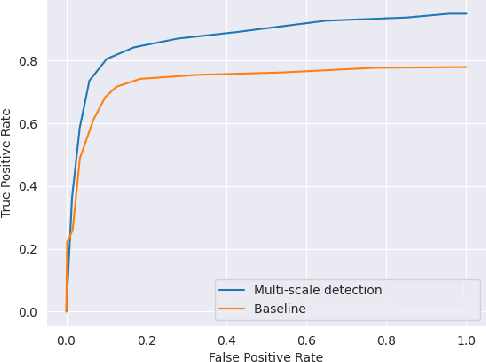
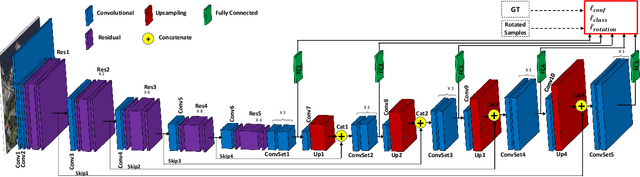
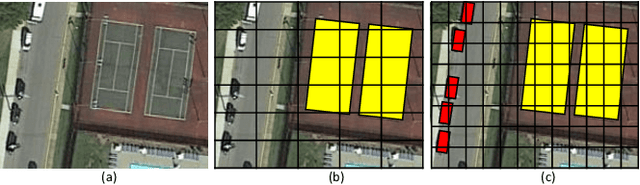
A novel object detection method is presented that handles freely rotated objects of arbitrary sizes, including tiny objects as small as $2\times 2$ pixels. Such tiny objects appear frequently in remotely sensed images, and present a challenge to recent object detection algorithms. More importantly, current object detection methods have been designed originally to accommodate axis-aligned bounding box detection, and therefore fail to accurately localize oriented boxes that best describe freely rotated objects. In contrast, the proposed CNN-based approach uses potential pixel information at multiple scale levels without the need for any external resources, such as anchor boxes.The method encodes the precise location and orientation of features of the target objects at grid cell locations. Unlike existing methods which regress the bounding box location and dimension,the proposed method learns all the required information by classification, which has the added benefit of enabling oriented bounding box detection without any extra computation. It thus infers the bounding boxes only at inference time by finding the minimum surrounding box for every set of the same predicted class labels. Moreover, a rotation-invariant feature representation is applied to each scale, which imposes a regularization constraint to enforce covering the 360 degree range of in-plane rotation of the training samples to share similar features. Evaluations on the xView and DOTA datasets show that the proposed method uniformly improves performance over existing state-of-the-art methods.