 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidMsg: A Benchmark for Implicit Message Inference in Short Videos
Jun 02, 2026Understanding short online videos involves more than identifying visible objects and actions; video makers often include an underlying message or purpose in the clip. We introduce VidMsg, a benchmark for evaluating implicit message understanding in short, internet-native video clips. VidMsg contains 400 YouTube-derived clips across 9 practical topic areas and 52 fine-grained target messages, covering domains such as career and finance, education, health and well-being, culture, safety, sustainability, and lifestyle. VidMsg is constructed through a message-first pipeline: an LLM first translates target messages into indirect search scenarios, which are used to retrieve candidate clips. Human annotators then retain clips that convey the intended message without being overly explicit. VidMsg is designed primarily for bidirectional message-clip retrieval for scalable applications such as video search and recommendation, where systems must capture holistic video understanding. In addition to retrieval, VidMsg includes a diagnostic multiple-choice QA benchmark, where models select the intended message of a clip from semantically related alternatives. Experiments with contemporary video-language and retrieval models show that strong models often fail on VidMsg, because the task requires pragmatic inference, integration of contextual cues, and discrimination among semantically close messages. We also introduce VidVec-Msg, a baseline method that improves message-oriented retrieval while leaving substantial headroom for future work.
Find your Needle: Small Object Image Retrieval via Multi-Object Attention Optimization
Mar 10, 2025



We address the challenge of Small Object Image Retrieval (SoIR), where the goal is to retrieve images containing a specific small object, in a cluttered scene. The key challenge in this setting is constructing a single image descriptor, for scalable and efficient search, that effectively represents all objects in the image. In this paper, we first analyze the limitations of existing methods on this challenging task and then introduce new benchmarks to support SoIR evaluation. Next, we introduce Multi-object Attention Optimization (MaO), a novel retrieval framework which incorporates a dedicated multi-object pre-training phase. This is followed by a refinement process that leverages attention-based feature extraction with object masks, integrating them into a single unified image descriptor. Our MaO approach significantly outperforms existing retrieval methods and strong baselines, achieving notable improvements in both zero-shot and lightweight multi-object fine-tuning. We hope this work will lay the groundwork and inspire further research to enhance retrieval performance for this highly practical task.
EffoVPR: Effective Foundation Model Utilization for Visual Place Recognition
May 28, 2024



The task of Visual Place Recognition (VPR) is to predict the location of a query image from a database of geo-tagged images. Recent studies in VPR have highlighted the significant advantage of employing pre-trained foundation models like DINOv2 for the VPR task. However, these models are often deemed inadequate for VPR without further fine-tuning on task-specific data. In this paper, we propose a simple yet powerful approach to better exploit the potential of a foundation model for VPR. We first demonstrate that features extracted from self-attention layers can serve as a powerful re-ranker for VPR. Utilizing these features in a zero-shot manner, our method surpasses previous zero-shot methods and achieves competitive results compared to supervised methods across multiple datasets. Subsequently, we demonstrate that a single-stage method leveraging internal ViT layers for pooling can generate global features that achieve state-of-the-art results, even when reduced to a dimensionality as low as 128D. Nevertheless, incorporating our local foundation features for re-ranking, expands this gap. Our approach further demonstrates remarkable robustness and generalization, achieving state-of-the-art results, with a significant gap, in challenging scenarios, involving occlusion, day-night variations, and seasonal changes.
Automatic Error Detection in Integrated Circuits Image Segmentation: A Data-driven Approach
Nov 08, 2022



Due to the complicated nanoscale structures of current integrated circuits(IC) builds and low error tolerance of IC image segmentation tasks, most existing automated IC image segmentation approaches require human experts for visual inspection to ensure correctness, which is one of the major bottlenecks in large-scale industrial applications. In this paper, we present the first data-driven automatic error detection approach targeting two types of IC segmentation errors: wire errors and via errors. On an IC image dataset collected from real industry, we demonstrate that, by adapting existing CNN-based approaches of image classification and image translation with additional pre-processing and post-processing techniques, we are able to achieve recall/precision of 0.92/0.93 in wire error detection and 0.96/0.90 in via error detection, respectively.
Borch: A Deep Universal Probabilistic Programming Language
Sep 13, 2022
Ever since the Multilayered Perceptron was first introduced the connectionist community has struggled with the concept of uncertainty and how this could be represented in these types of models. This past decade has seen a lot of effort in trying to join the principled approach of probabilistic modeling with the scalable nature of deep neural networks. While the theoretical benefits of this consolidation are clear, there are also several important practical aspects of these endeavors; namely to force the models we create to represent, learn, and report uncertainty in every prediction that is made. Many of these efforts have been based on extending existing frameworks with additional structures. We present Borch, a scalable deep universal probabilistic programming language, built on top of PyTorch. The code is available for download and use in our repository https://gitlab.com/desupervised/borch.
Making a Difference One Rationale at a Time
Jan 13, 2022

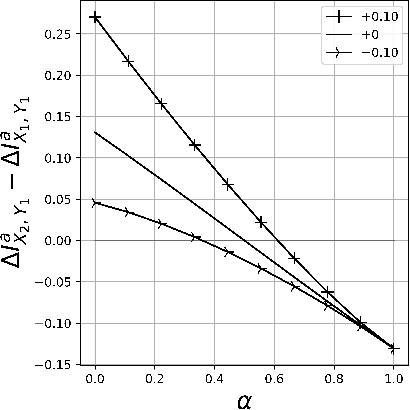
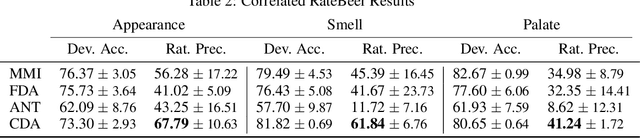
Rationales, snippets of extracted text that explain an inference, have emerged as a popular framework for interpretable natural language processing (NLP). Rationale models typically consist of two cooperating modules: a selector and a classifier with the goal of maximizing the mutual information (MMI) between the "selected" text and the document label. Despite their promises, MMI-based methods often pick up on spurious text patterns and result in models with nonsensical behaviors. In this work, we investigate whether counterfactual data augmentation (CDA), without human assistance, can improve the performance of the selector by lowering the mutual information between spurious signals and the document label. Our counterfactuals are produced in an unsupervised fashion using class-dependent generative models. From an information theoretic lens, we derive properties of the unaugmented dataset for which our CDA approach would succeed. The effectiveness of CDA is empirically evaluated by comparing against several baselines including an improved MMI-based rationale schema on two multi aspect datasets. Our results show that CDA produces rationales that better capture the signal of interest.