 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal to Global: Learning Dynamics and Effect of Initialization for Transformers
Jun 05, 2024



In recent years, transformer-based models have revolutionized deep learning, particularly in sequence modeling. To better understand this phenomenon, there is a growing interest in using Markov input processes to study transformers. However, our current understanding in this regard remains limited with many fundamental questions about how transformers learn Markov chains still unanswered. In this paper, we address this by focusing on first-order Markov chains and single-layer transformers, providing a comprehensive characterization of the learning dynamics in this context. Specifically, we prove that transformer parameters trained on next-token prediction loss can either converge to global or local minima, contingent on the initialization and the Markovian data properties, and we characterize the precise conditions under which this occurs. To the best of our knowledge, this is the first result of its kind highlighting the role of initialization. We further demonstrate that our theoretical findings are corroborated by empirical evidence. Based on these insights, we provide guidelines for the initialization of transformer parameters and demonstrate their effectiveness. Finally, we outline several open problems in this arena. Code is available at: \url{https://anonymous.4open.science/r/Local-to-Global-C70B/}.
The Fundamental Limits of Least-Privilege Learning
Feb 19, 2024



The promise of least-privilege learning -- to find feature representations that are useful for a learning task but prevent inference of any sensitive information unrelated to this task -- is highly appealing. However, so far this concept has only been stated informally. It thus remains an open question whether and how we can achieve this goal. In this work, we provide the first formalisation of the least-privilege principle for machine learning and characterise its feasibility. We prove that there is a fundamental trade-off between a representation's utility for a given task and its leakage beyond the intended task: it is not possible to learn representations that have high utility for the intended task but, at the same time prevent inference of any attribute other than the task label itself. This trade-off holds regardless of the technique used to learn the feature mappings that produce these representations. We empirically validate this result for a wide range of learning techniques, model architectures, and datasets.
Attention with Markov: A Framework for Principled Analysis of Transformers via Markov Chains
Feb 06, 2024



In recent years, attention-based transformers have achieved tremendous success across a variety of disciplines including natural languages. A key ingredient behind their success is the generative pretraining procedure, during which these models are trained on a large text corpus in an auto-regressive manner. To shed light on this phenomenon, we propose a new framework that allows both theory and systematic experiments to study the sequential modeling capabilities of transformers through the lens of Markov chains. Inspired by the Markovianity of natural languages, we model the data as a Markovian source and utilize this framework to systematically study the interplay between the data-distributional properties, the transformer architecture, the learnt distribution, and the final model performance. In particular, we theoretically characterize the loss landscape of single-layer transformers and show the existence of global minima and bad local minima contingent upon the specific data characteristics and the transformer architecture. Backed by experiments, we demonstrate that our theoretical findings are in congruence with the empirical results. We further investigate these findings in the broader context of higher order Markov chains and deeper architectures, and outline open problems in this arena. Code is available at \url{https://github.com/Bond1995/Markov}.
Batch Universal Prediction
Feb 06, 2024Large language models (LLMs) have recently gained much popularity due to their surprising ability at generating human-like English sentences. LLMs are essentially predictors, estimating the probability of a sequence of words given the past. Therefore, it is natural to evaluate their performance from a universal prediction perspective. In order to do that fairly, we introduce the notion of batch regret as a modification of the classical average regret, and we study its asymptotical value for add-constant predictors, in the case of memoryless sources and first-order Markov sources.
Fantastic Generalization Measures are Nowhere to be Found
Sep 24, 2023

Numerous generalization bounds have been proposed in the literature as potential explanations for the ability of neural networks to generalize in the overparameterized setting. However, none of these bounds are tight. For instance, in their paper ``Fantastic Generalization Measures and Where to Find Them'', Jiang et al. (2020) examine more than a dozen generalization bounds, and show empirically that none of them imply guarantees that can explain the remarkable performance of neural networks. This raises the question of whether tight generalization bounds are at all possible. We consider two types of generalization bounds common in the literature: (1) bounds that depend on the training set and the output of the learning algorithm. There are multiple bounds of this type in the literature (e.g., norm-based and margin-based bounds), but we prove mathematically that no such bound can be uniformly tight in the overparameterized setting; (2) bounds that depend on the training set and on the learning algorithm (e.g., stability bounds). For these bounds, we show a trade-off between the algorithm's performance and the bound's tightness. Namely, if the algorithm achieves good accuracy on certain distributions in the overparameterized setting, then no generalization bound can be tight for it. We conclude that generalization bounds in the overparameterized setting cannot be tight without suitable assumptions on the population distribution.
Lower Bounds on the Bayesian Risk via Information Measures
Mar 24, 2023



This paper focuses on parameter estimation and introduces a new method for lower bounding the Bayesian risk. The method allows for the use of virtually \emph{any} information measure, including R\'enyi's $\alpha$, $\varphi$-Divergences, and Sibson's $\alpha$-Mutual Information. The approach considers divergences as functionals of measures and exploits the duality between spaces of measures and spaces of functions. In particular, we show that one can lower bound the risk with any information measure by upper bounding its dual via Markov's inequality. We are thus able to provide estimator-independent impossibility results thanks to the Data-Processing Inequalities that divergences satisfy. The results are then applied to settings of interest involving both discrete and continuous parameters, including the ``Hide-and-Seek'' problem, and compared to the state-of-the-art techniques. An important observation is that the behaviour of the lower bound in the number of samples is influenced by the choice of the information measure. We leverage this by introducing a new divergence inspired by the ``Hockey-Stick'' Divergence, which is demonstrated empirically to provide the largest lower-bound across all considered settings. If the observations are subject to privatisation, stronger impossibility results can be obtained via Strong Data-Processing Inequalities. The paper also discusses some generalisations and alternative directions.
Asymptotically Optimal Generalization Error Bounds for Noisy, Iterative Algorithms
Feb 28, 2023We adopt an information-theoretic framework to analyze the generalization behavior of the class of iterative, noisy learning algorithms. This class is particularly suitable for study under information-theoretic metrics as the algorithms are inherently randomized, and it includes commonly used algorithms such as Stochastic Gradient Langevin Dynamics (SGLD). Herein, we use the maximal leakage (equivalently, the Sibson mutual information of order infinity) metric, as it is simple to analyze, and it implies both bounds on the probability of having a large generalization error and on its expected value. We show that, if the update function (e.g., gradient) is bounded in $L_2$-norm, then adding isotropic Gaussian noise leads to optimal generalization bounds: indeed, the input and output of the learning algorithm in this case are asymptotically statistically independent. Furthermore, we demonstrate how the assumptions on the update function affect the optimal (in the sense of minimizing the induced maximal leakage) choice of the noise. Finally, we compute explicit tight upper bounds on the induced maximal leakage for several scenarios of interest.
Finite Littlestone Dimension Implies Finite Information Complexity
Jun 27, 2022We prove that every online learnable class of functions of Littlestone dimension $d$ admits a learning algorithm with finite information complexity. Towards this end, we use the notion of a globally stable algorithm. Generally, the information complexity of such a globally stable algorithm is large yet finite, roughly exponential in $d$. We also show there is room for improvement; for a canonical online learnable class, indicator functions of affine subspaces of dimension $d$, the information complexity can be upper bounded logarithmically in $d$.
From Generalisation Error to Transportation-cost Inequalities and Back
Feb 08, 2022In this work, we connect the problem of bounding the expected generalisation error with transportation-cost inequalities. Exposing the underlying pattern behind both approaches we are able to generalise them and go beyond Kullback-Leibler Divergences/Mutual Information and sub-Gaussian measures. In particular, we are able to provide a result showing the equivalence between two families of inequalities: one involving functionals and one involving measures. This result generalises the one proposed by Bobkov and G\"otze that connects transportation-cost inequalities with concentration of measure. Moreover, it allows us to recover all standard generalisation error bounds involving mutual information and to introduce new, more general bounds, that involve arbitrary divergence measures.
A Johnson--Lindenstrauss Framework for Randomly Initialized CNNs
Nov 03, 2021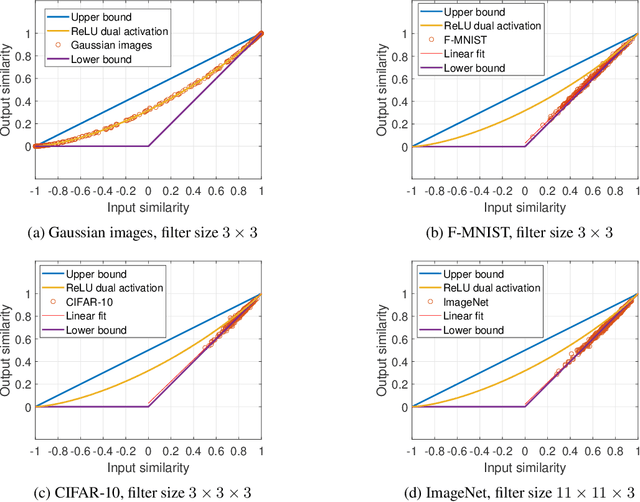
How does the geometric representation of a dataset change after the application of each randomly initialized layer of a neural network? The celebrated Johnson--Lindenstrauss lemma answers this question for linear fully-connected neural networks (FNNs), stating that the geometry is essentially preserved. For FNNs with the ReLU activation, the angle between two inputs contracts according to a known mapping. The question for non-linear convolutional neural networks (CNNs) becomes much more intricate. To answer this question, we introduce a geometric framework. For linear CNNs, we show that the Johnson--Lindenstrauss lemma continues to hold, namely, that the angle between two inputs is preserved. For CNNs with ReLU activation, on the other hand, the behavior is richer: The angle between the outputs contracts, where the level of contraction depends on the nature of the inputs. In particular, after one layer, the geometry of natural images is essentially preserved, whereas for Gaussian correlated inputs, CNNs exhibit the same contracting behavior as FNNs with ReLU activation.