 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Massively Parallel Associative Memory Based on Sparse Neural Networks
Jul 21, 2013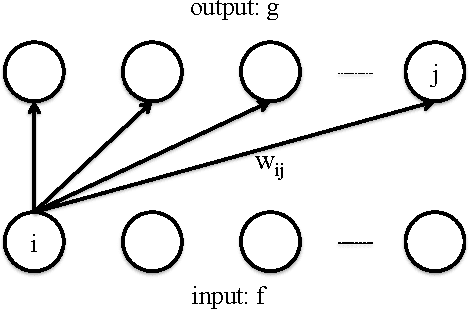
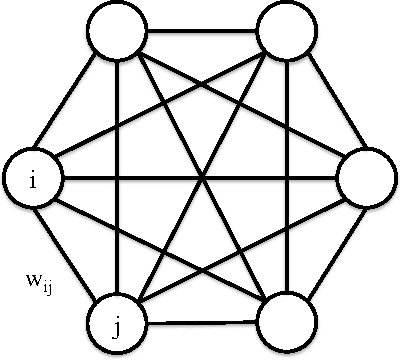
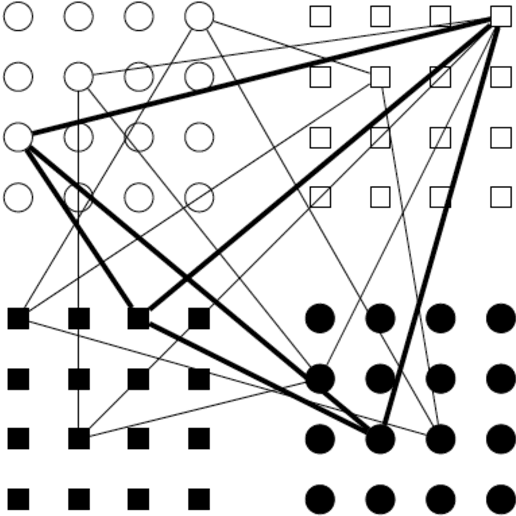
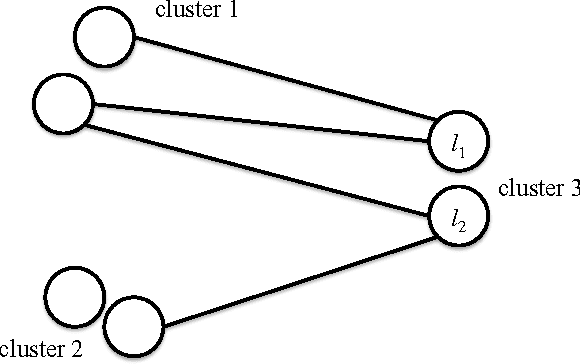
Associative memories store content in such a way that the content can be later retrieved by presenting the memory with a small portion of the content, rather than presenting the memory with an address as in more traditional memories. Associative memories are used as building blocks for algorithms within database engines, anomaly detection systems, compression algorithms, and face recognition systems. A classical example of an associative memory is the Hopfield neural network. Recently, Gripon and Berrou have introduced an alternative construction which builds on ideas from the theory of error correcting codes and which greatly outperforms the Hopfield network in capacity, diversity, and efficiency. In this paper we implement a variation of the Gripon-Berrou associative memory on a general purpose graphical processing unit (GPU). The work of Gripon and Berrou proposes two retrieval rules, sum-of-sum and sum-of-max. The sum-of-sum rule uses only matrix-vector multiplication and is easily implemented on the GPU. The sum-of-max rule is much less straightforward to implement because it involves non-linear operations. However, the sum-of-max rule gives significantly better retrieval error rates. We propose a hybrid rule tailored for implementation on a GPU which achieves a 880-fold speedup without sacrificing any accuracy.
Distributed Strongly Convex Optimization
Jul 20, 2012
A lot of effort has been invested into characterizing the convergence rates of gradient based algorithms for non-linear convex optimization. Recently, motivated by large datasets and problems in machine learning, the interest has shifted towards distributed optimization. In this work we present a distributed algorithm for strongly convex constrained optimization. Each node in a network of n computers converges to the optimum of a strongly convex, L-Lipchitz continuous, separable objective at a rate O(log (sqrt(n) T) / T) where T is the number of iterations. This rate is achieved in the online setting where the data is revealed one at a time to the nodes, and in the batch setting where each node has access to its full local dataset from the start. The same convergence rate is achieved in expectation when the subgradients used at each node are corrupted with additive zero-mean noise.