 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Meaningful Units with Visually Grounded Semantics from Image Captions
Nov 14, 2025



Fine-grained knowledge is crucial for vision-language models to obtain a better understanding of the real world. While there has been work trying to acquire this kind of knowledge in the space of vision and language, it has mostly focused on aligning the image patches with the tokens on the language side. However, image patches do not have any meaning to the human eye, and individual tokens do not necessarily carry groundable information in the image. It is groups of tokens which describe different aspects of the scene. In this work, we propose a model which groups the caption tokens as part of its architecture in order to capture a fine-grained representation of the language. We expect our representations to be at the level of objects present in the image, and therefore align our representations with the output of an image encoder trained to discover objects. We show that by learning to group the tokens, the vision-language model has a better fine-grained understanding of vision and language. In addition, the token groups that our model discovers are highly similar to groundable phrases in text, both qualitatively and quantitatively.
GABInsight: Exploring Gender-Activity Binding Bias in Vision-Language Models
Jul 30, 2024



Vision-language models (VLMs) are intensively used in many downstream tasks, including those requiring assessments of individuals appearing in the images. While VLMs perform well in simple single-person scenarios, in real-world applications, we often face complex situations in which there are persons of different genders doing different activities. We show that in such cases, VLMs are biased towards identifying the individual with the expected gender (according to ingrained gender stereotypes in the model or other forms of sample selection bias) as the performer of the activity. We refer to this bias in associating an activity with the gender of its actual performer in an image or text as the Gender-Activity Binding (GAB) bias and analyze how this bias is internalized in VLMs. To assess this bias, we have introduced the GAB dataset with approximately 5500 AI-generated images that represent a variety of activities, addressing the scarcity of real-world images for some scenarios. To have extensive quality control, the generated images are evaluated for their diversity, quality, and realism. We have tested 12 renowned pre-trained VLMs on this dataset in the context of text-to-image and image-to-text retrieval to measure the effect of this bias on their predictions. Additionally, we have carried out supplementary experiments to quantify the bias in VLMs' text encoders and to evaluate VLMs' capability to recognize activities. Our experiments indicate that VLMs experience an average performance decline of about 13.2% when confronted with gender-activity binding bias.
Learning to Abstract with Nonparametric Variational Information Bottleneck
Oct 26, 2023



Learned representations at the level of characters, sub-words, words and sentences, have each contributed to advances in understanding different NLP tasks and linguistic phenomena. However, learning textual embeddings is costly as they are tokenization specific and require different models to be trained for each level of abstraction. We introduce a novel language representation model which can learn to compress to different levels of abstraction at different layers of the same model. We apply Nonparametric Variational Information Bottleneck (NVIB) to stacked Transformer self-attention layers in the encoder, which encourages an information-theoretic compression of the representations through the model. We find that the layers within the model correspond to increasing levels of abstraction and that their representations are more linguistically informed. Finally, we show that NVIB compression results in a model which is more robust to adversarial perturbations.
Inducing Meaningful Units from Character Sequences with Slot Attention
Feb 01, 2021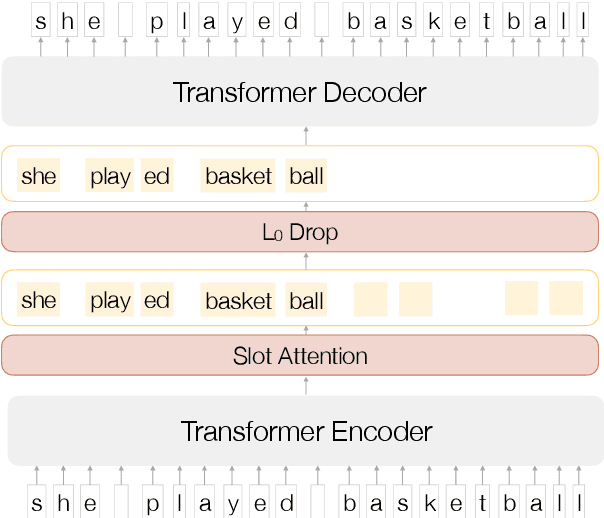
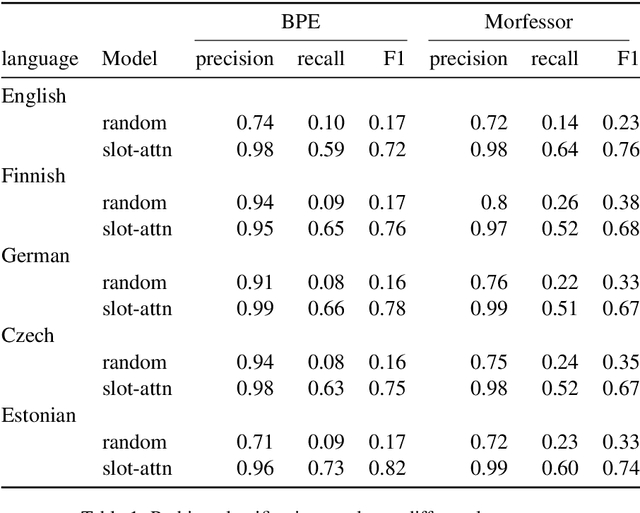
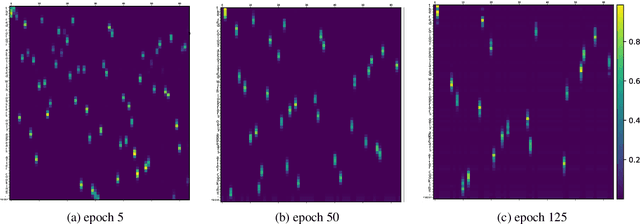
Characters do not convey meaning, but sequences of characters do. We propose an unsupervised distributional method to learn the abstract meaning-bearing units in a sequence of characters. Rather than segmenting the sequence, this model discovers continuous representations of the "objects" in the sequence, using a recently proposed architecture for object discovery in images called Slot Attention. We train our model on different languages and evaluate the quality of the obtained representations with probing classifiers. Our experiments show promising results in the ability of our units to capture meaning at a higher level of abstraction.