 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdVAE: Mitigating Codebook Collapse with Evidential Discrete Variational Autoencoders
Oct 09, 2023Codebook collapse is a common problem in training deep generative models with discrete representation spaces like Vector Quantized Variational Autoencoders (VQ-VAEs). We observe that the same problem arises for the alternatively designed discrete variational autoencoders (dVAEs) whose encoder directly learns a distribution over the codebook embeddings to represent the data. We hypothesize that using the softmax function to obtain a probability distribution causes the codebook collapse by assigning overconfident probabilities to the best matching codebook elements. In this paper, we propose a novel way to incorporate evidential deep learning (EDL) instead of softmax to combat the codebook collapse problem of dVAE. We evidentially monitor the significance of attaining the probability distribution over the codebook embeddings, in contrast to softmax usage. Our experiments using various datasets show that our model, called EdVAE, mitigates codebook collapse while improving the reconstruction performance, and enhances the codebook usage compared to dVAE and VQ-VAE based models.
Improved Algorithms for Stochastic Linear Bandits Using Tail Bounds for Martingale Mixtures
Sep 27, 2023



We present improved algorithms with worst-case regret guarantees for the stochastic linear bandit problem. The widely used "optimism in the face of uncertainty" principle reduces a stochastic bandit problem to the construction of a confidence sequence for the unknown reward function. The performance of the resulting bandit algorithm depends on the size of the confidence sequence, with smaller confidence sets yielding better empirical performance and stronger regret guarantees. In this work, we use a novel tail bound for adaptive martingale mixtures to construct confidence sequences which are suitable for stochastic bandits. These confidence sequences allow for efficient action selection via convex programming. We prove that a linear bandit algorithm based on our confidence sequences is guaranteed to achieve competitive worst-case regret. We show that our confidence sequences are tighter than competitors, both empirically and theoretically. Finally, we demonstrate that our tighter confidence sequences give improved performance in several hyperparameter tuning tasks.
Sampling-Free Probabilistic Deep State-Space Models
Sep 15, 2023



Many real-world dynamical systems can be described as State-Space Models (SSMs). In this formulation, each observation is emitted by a latent state, which follows first-order Markovian dynamics. A Probabilistic Deep SSM (ProDSSM) generalizes this framework to dynamical systems of unknown parametric form, where the transition and emission models are described by neural networks with uncertain weights. In this work, we propose the first deterministic inference algorithm for models of this type. Our framework allows efficient approximations for training and testing. We demonstrate in our experiments that our new method can be employed for a variety of tasks and enjoys a superior balance between predictive performance and computational budget.
Estimation of Counterfactual Interventions under Uncertainties
Sep 15, 2023Counterfactual analysis is intuitively performed by humans on a daily basis eg. "What should I have done differently to get the loan approved?". Such counterfactual questions also steer the formulation of scientific hypotheses. More formally it provides insights about potential improvements of a system by inferring the effects of hypothetical interventions into a past observation of the system's behaviour which plays a prominent role in a variety of industrial applications. Due to the hypothetical nature of such analysis, counterfactual distributions are inherently ambiguous. This ambiguity is particularly challenging in continuous settings in which a continuum of explanations exist for the same observation. In this paper, we address this problem by following a hierarchical Bayesian approach which explicitly models such uncertainty. In particular, we derive counterfactual distributions for a Bayesian Warped Gaussian Process thereby allowing for non-Gaussian distributions and non-additive noise. We illustrate the properties our approach on a synthetic and on a semi-synthetic example and show its performance when used within an algorithmic recourse downstream task.
BOF-UCB: A Bayesian-Optimistic Frequentist Algorithm for Non-Stationary Contextual Bandits
Jul 19, 2023We propose a novel Bayesian-Optimistic Frequentist Upper Confidence Bound (BOF-UCB) algorithm for stochastic contextual linear bandits in non-stationary environments. This unique combination of Bayesian and frequentist principles enhances adaptability and performance in dynamic settings. The BOF-UCB algorithm utilizes sequential Bayesian updates to infer the posterior distribution of the unknown regression parameter, and subsequently employs a frequentist approach to compute the Upper Confidence Bound (UCB) by maximizing the expected reward over the posterior distribution. We provide theoretical guarantees of BOF-UCB's performance and demonstrate its effectiveness in balancing exploration and exploitation on synthetic datasets and classical control tasks in a reinforcement learning setting. Our results show that BOF-UCB outperforms existing methods, making it a promising solution for sequential decision-making in non-stationary environments.
Cheap and Deterministic Inference for Deep State-Space Models of Interacting Dynamical Systems
May 02, 2023



Graph neural networks are often used to model interacting dynamical systems since they gracefully scale to systems with a varying and high number of agents. While there has been much progress made for deterministic interacting systems, modeling is much more challenging for stochastic systems in which one is interested in obtaining a predictive distribution over future trajectories. Existing methods are either computationally slow since they rely on Monte Carlo sampling or make simplifying assumptions such that the predictive distribution is unimodal. In this work, we present a deep state-space model which employs graph neural networks in order to model the underlying interacting dynamical system. The predictive distribution is multimodal and has the form of a Gaussian mixture model, where the moments of the Gaussian components can be computed via deterministic moment matching rules. Our moment matching scheme can be exploited for sample-free inference, leading to more efficient and stable training compared to Monte Carlo alternatives. Furthermore, we propose structured approximations to the covariance matrices of the Gaussian components in order to scale up to systems with many agents. We benchmark our novel framework on two challenging autonomous driving datasets. Both confirm the benefits of our method compared to state-of-the-art methods. We further demonstrate the usefulness of our individual contributions in a carefully designed ablation study and provide a detailed runtime analysis of our proposed covariance approximations. Finally, we empirically demonstrate the generalization ability of our method by evaluating its performance on unseen scenarios.
PAC-Bayesian Soft Actor-Critic Learning
Jan 30, 2023



Actor-critic algorithms address the dual goals of reinforcement learning, policy evaluation and improvement, via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that the online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably to the state of the art on multiple classical control and locomotion tasks in both sample efficiency and asymptotic performance.
PAC-Bayes Bounds for Bandit Problems: A Survey and Experimental Comparison
Nov 29, 2022



PAC-Bayes has recently re-emerged as an effective theory with which one can derive principled learning algorithms with tight performance guarantees. However, applications of PAC-Bayes to bandit problems are relatively rare, which is a great misfortune. Many decision-making problems in healthcare, finance and natural sciences can be modelled as bandit problems. In many of these applications, principled algorithms with strong performance guarantees would be very much appreciated. This survey provides an overview of PAC-Bayes performance bounds for bandit problems and an experimental comparison of these bounds. Our experimental comparison has revealed that available PAC-Bayes upper bounds on the cumulative regret are loose, whereas available PAC-Bayes lower bounds on the expected reward can be surprisingly tight. We found that an offline contextual bandit algorithm that learns a policy by optimising a PAC-Bayes bound was able to learn randomised neural network polices with competitive expected reward and non-vacuous performance guarantees.
Learning Interacting Dynamical Systems with Latent Gaussian Process ODEs
May 24, 2022
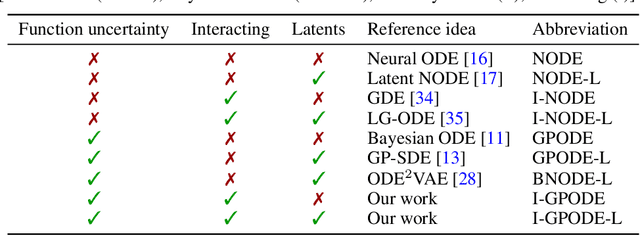
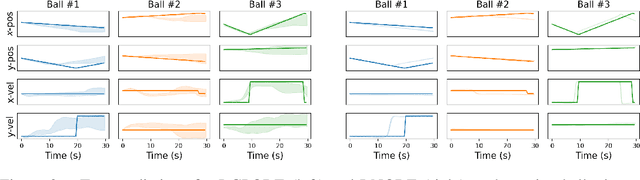
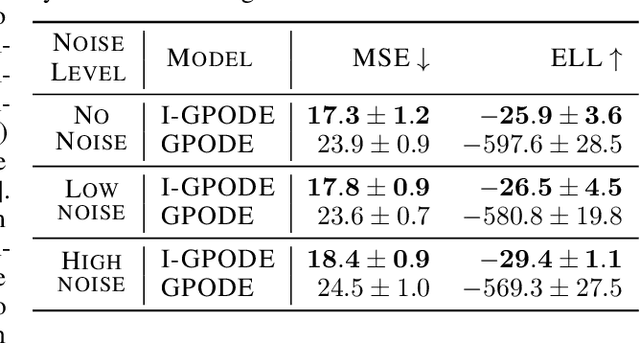
We study for the first time uncertainty-aware modeling of continuous-time dynamics of interacting objects. We introduce a new model that decomposes independent dynamics of single objects accurately from their interactions. By employing latent Gaussian process ordinary differential equations, our model infers both independent dynamics and their interactions with reliable uncertainty estimates. In our formulation, each object is represented as a graph node and interactions are modeled by accumulating the messages coming from neighboring objects. We show that efficient inference of such a complex network of variables is possible with modern variational sparse Gaussian process inference techniques. We empirically demonstrate that our model improves the reliability of long-term predictions over neural network based alternatives and it successfully handles missing dynamic or static information. Furthermore, we observe that only our model can successfully encapsulate independent dynamics and interaction information in distinct functions and show the benefit from this disentanglement in extrapolation scenarios.
PAC-Bayesian Lifelong Learning For Multi-Armed Bandits
Mar 07, 2022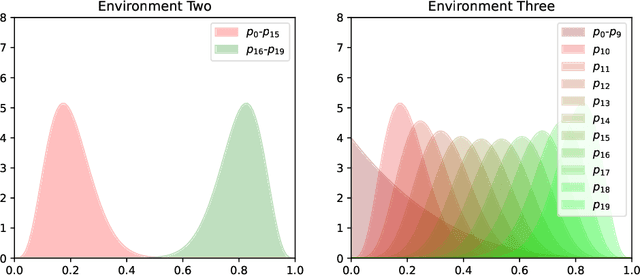
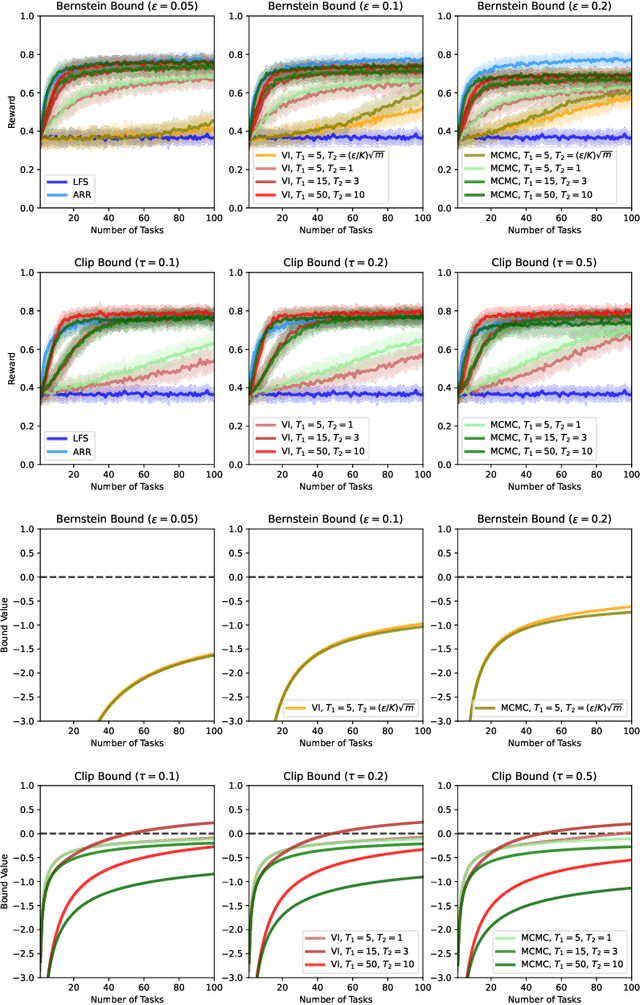
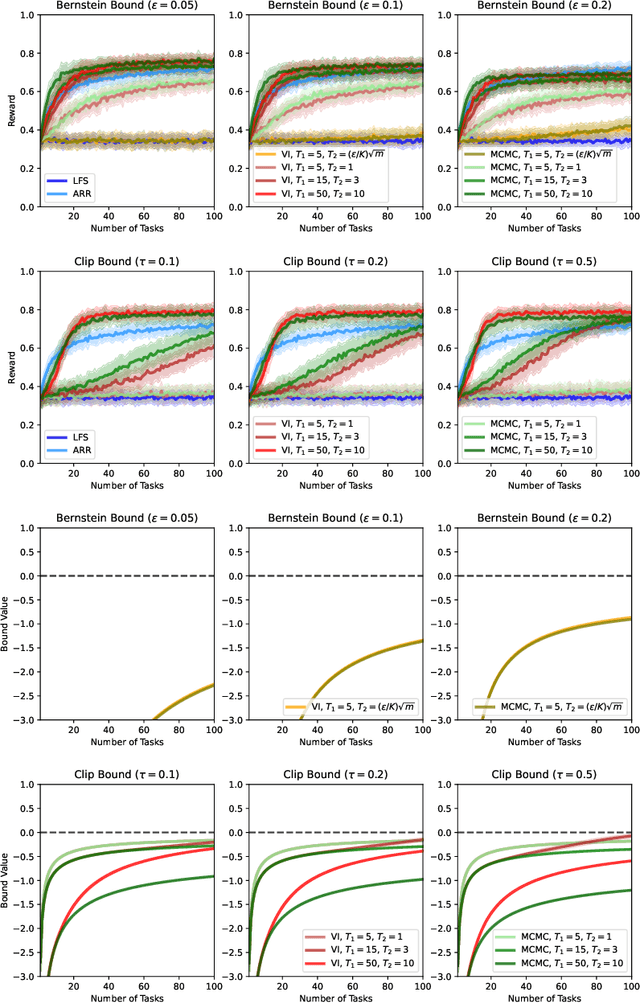
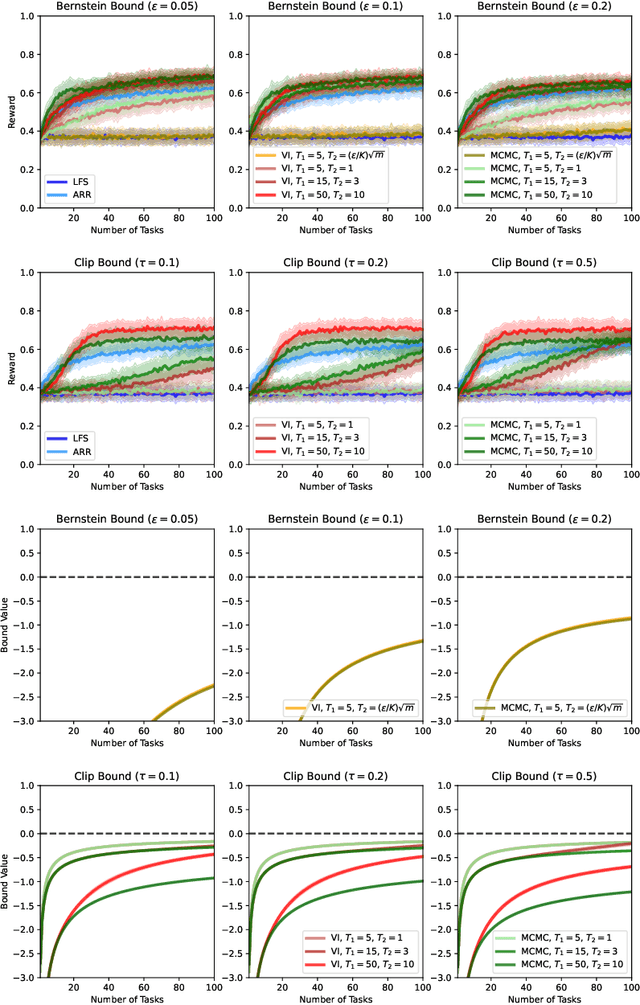
We present a PAC-Bayesian analysis of lifelong learning. In the lifelong learning problem, a sequence of learning tasks is observed one-at-a-time, and the goal is to transfer information acquired from previous tasks to new learning tasks. We consider the case when each learning task is a multi-armed bandit problem. We derive lower bounds on the expected average reward that would be obtained if a given multi-armed bandit algorithm was run in a new task with a particular prior and for a set number of steps. We propose lifelong learning algorithms that use our new bounds as learning objectives. Our proposed algorithms are evaluated in several lifelong multi-armed bandit problems and are found to perform better than a baseline method that does not use generalisation bounds.
* 29 pages, 5 figures