 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Understanding on Conceptual Abstraction Benchmarks
Jun 28, 2022

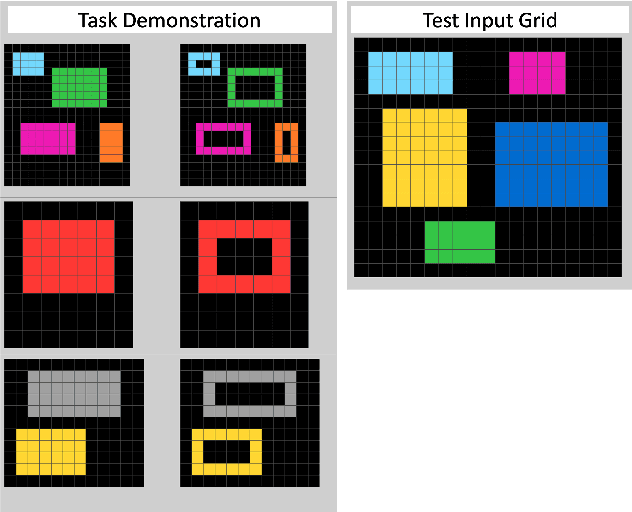

A long-held objective in AI is to build systems that understand concepts in a humanlike way. Setting aside the difficulty of building such a system, even trying to evaluate one is a challenge, due to present-day AI's relative opacity and its proclivity for finding shortcut solutions. This is exacerbated by humans' tendency to anthropomorphize, assuming that a system that can recognize one instance of a concept must also understand other instances, as a human would. In this paper, we argue that understanding a concept requires the ability to use it in varied contexts. Accordingly, we propose systematic evaluations centered around concepts, by probing a system's ability to use a given concept in many different instantiations. We present case studies of such an evaluations on two domains -- RAVEN (inspired by Raven's Progressive Matrices) and the Abstraction and Reasoning Corpus (ARC) -- that have been used to develop and assess abstraction abilities in AI systems. Our concept-based approach to evaluation reveals information about AI systems that conventional test sets would have left hidden.
Abstraction for Deep Reinforcement Learning
Feb 18, 2022
We characterise the problem of abstraction in the context of deep reinforcement learning. Various well established approaches to analogical reasoning and associative memory might be brought to bear on this issue, but they present difficulties because of the need for end-to-end differentiability. We review developments in AI and machine learning that could facilitate their adoption.
Frontiers in Collective Intelligence: A Workshop Report
Dec 13, 2021In August of 2021, the Santa Fe Institute hosted a workshop on collective intelligence as part of its Foundations of Intelligence project. This project seeks to advance the field of artificial intelligence by promoting interdisciplinary research on the nature of intelligence. The workshop brought together computer scientists, biologists, philosophers, social scientists, and others to share their insights about how intelligence can emerge from interactions among multiple agents--whether those agents be machines, animals, or human beings. In this report, we summarize each of the talks and the subsequent discussions. We also draw out a number of key themes and identify important frontiers for future research.
Frontiers in Evolutionary Computation: A Workshop Report
Oct 20, 2021In July of 2021, the Santa Fe Institute hosted a workshop on evolutionary computation as part of its Foundations of Intelligence in Natural and Artificial Systems project. This project seeks to advance the field of artificial intelligence by promoting interdisciplinary research on the nature of intelligence. The workshop brought together computer scientists and biologists to share their insights about the nature of evolution and the future of evolutionary computation. In this report, we summarize each of the talks and the subsequent discussions. We also draw out a number of key themes and identify important frontiers for future research.
A Little Robustness Goes a Long Way: Leveraging Universal Features for Targeted Transfer Attacks
Jun 03, 2021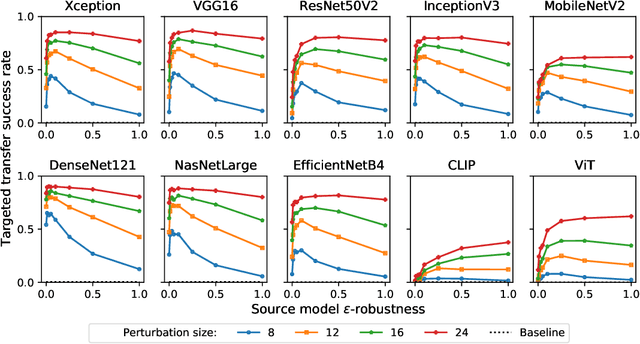
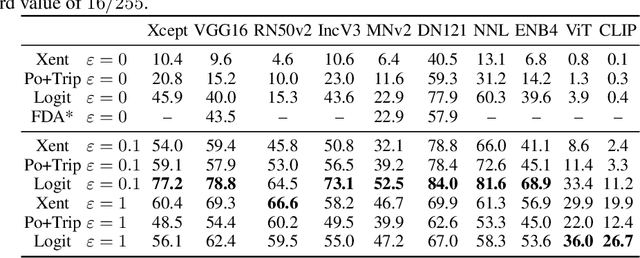
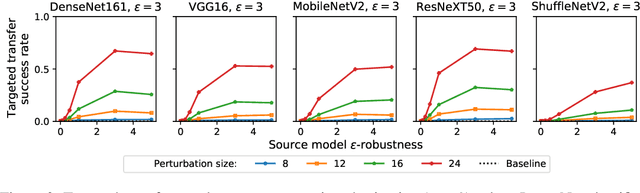
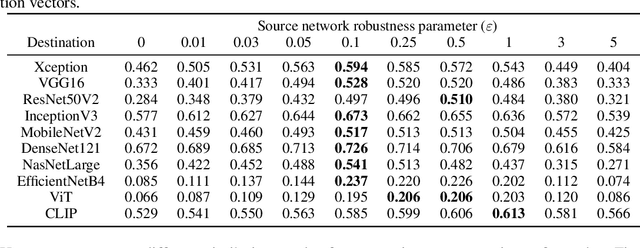
Adversarial examples for neural network image classifiers are known to be transferable: examples optimized to be misclassified by a source classifier are often misclassified as well by classifiers with different architectures. However, targeted adversarial examples -- optimized to be classified as a chosen target class -- tend to be less transferable between architectures. While prior research on constructing transferable targeted attacks has focused on improving the optimization procedure, in this work we examine the role of the source classifier. Here, we show that training the source classifier to be "slightly robust" -- that is, robust to small-magnitude adversarial examples -- substantially improves the transferability of targeted attacks, even between architectures as different as convolutional neural networks and transformers. We argue that this result supports a non-intuitive hypothesis: on the spectrum from non-robust (standard) to highly robust classifiers, those that are only slightly robust exhibit the most universal features -- ones that tend to overlap with the features learned by other classifiers trained on the same dataset. The results we present provide insight into the nature of adversarial examples as well as the mechanisms underlying so-called "robust" classifiers.
Foundations of Intelligence in Natural and Artificial Systems: A Workshop Report
May 05, 2021In March of 2021, the Santa Fe Institute hosted a workshop as part of its Foundations of Intelligence in Natural and Artificial Systems project. This project seeks to advance the field of artificial intelligence by promoting interdisciplinary research on the nature of intelligence. During the workshop, speakers from diverse disciplines gathered to develop a taxonomy of intelligence, articulating their own understanding of intelligence and how their research has furthered that understanding. In this report, we summarize the insights offered by each speaker and identify the themes that emerged during the talks and subsequent discussions.
Why AI is Harder Than We Think
Apr 28, 2021Since its beginning in the 1950s, the field of artificial intelligence has cycled several times between periods of optimistic predictions and massive investment ("AI spring") and periods of disappointment, loss of confidence, and reduced funding ("AI winter"). Even with today's seemingly fast pace of AI breakthroughs, the development of long-promised technologies such as self-driving cars, housekeeping robots, and conversational companions has turned out to be much harder than many people expected. One reason for these repeating cycles is our limited understanding of the nature and complexity of intelligence itself. In this paper I describe four fallacies in common assumptions made by AI researchers, which can lead to overconfident predictions about the field. I conclude by discussing the open questions spurred by these fallacies, including the age-old challenge of imbuing machines with humanlike common sense.
Abstraction and Analogy-Making in Artificial Intelligence
Feb 22, 2021
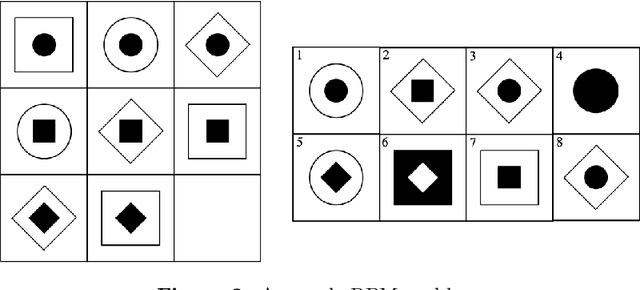
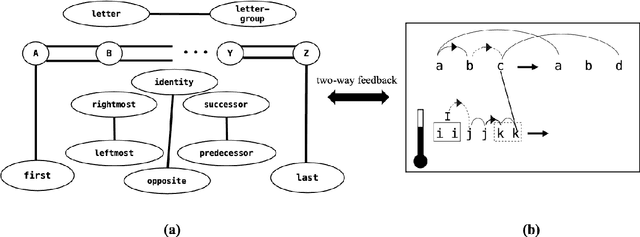
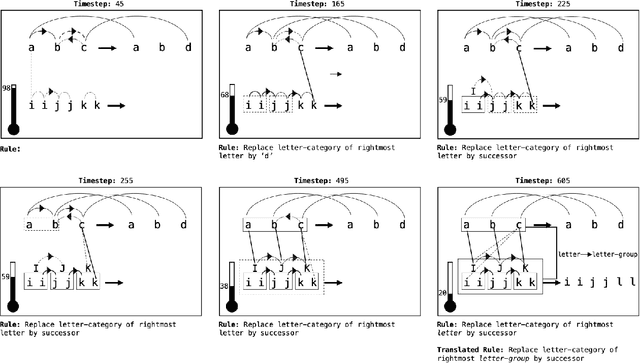
Conceptual abstraction and analogy-making are key abilities underlying humans' abilities to learn, reason, and robustly adapt their knowledge to new domains. Despite of a long history of research on constructing AI systems with these abilities, no current AI system is anywhere close to a capability of forming humanlike abstractions or analogies. This paper reviews the advantages and limitations of several approaches toward this goal, including symbolic methods, deep learning, and probabilistic program induction. The paper concludes with several proposals for designing challenge tasks and evaluation measures in order to make quantifiable and generalizable progress in this area.
Adversarial Perturbations Are Not So Weird: Entanglement of Robust and Non-Robust Features in Neural Network Classifiers
Feb 09, 2021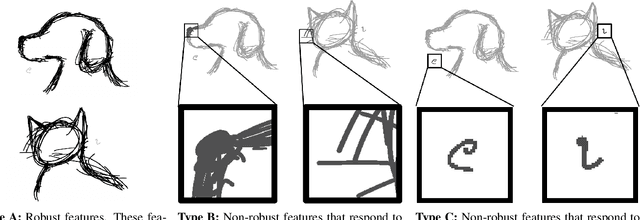
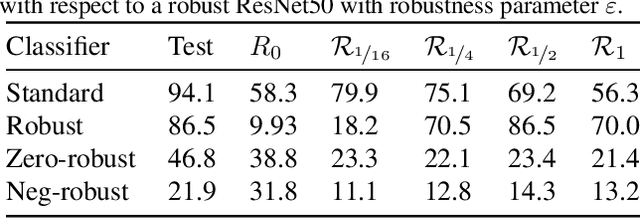

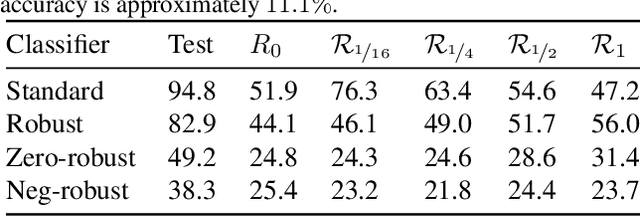
Neural networks trained on visual data are well-known to be vulnerable to often imperceptible adversarial perturbations. The reasons for this vulnerability are still being debated in the literature. Recently Ilyas et al. (2019) showed that this vulnerability arises, in part, because neural network classifiers rely on highly predictive but brittle "non-robust" features. In this paper we extend the work of Ilyas et al. by investigating the nature of the input patterns that give rise to these features. In particular, we hypothesize that in a neural network trained in a standard way, non-robust features respond to small, "non-semantic" patterns that are typically entangled with larger, robust patterns, known to be more human-interpretable, as opposed to solely responding to statistical artifacts in a dataset. Thus, adversarial examples can be formed via minimal perturbations to these small, entangled patterns. In addition, we demonstrate a corollary of our hypothesis: robust classifiers are more effective than standard (non-robust) ones as a source for generating transferable adversarial examples in both the untargeted and targeted settings. The results we present in this paper provide new insight into the nature of the non-robust features responsible for adversarial vulnerability of neural network classifiers.
Next Wave Artificial Intelligence: Robust, Explainable, Adaptable, Ethical, and Accountable
Dec 11, 2020The history of AI has included several "waves" of ideas. The first wave, from the mid-1950s to the 1980s, focused on logic and symbolic hand-encoded representations of knowledge, the foundations of so-called "expert systems". The second wave, starting in the 1990s, focused on statistics and machine learning, in which, instead of hand-programming rules for behavior, programmers constructed "statistical learning algorithms" that could be trained on large datasets. In the most recent wave research in AI has largely focused on deep (i.e., many-layered) neural networks, which are loosely inspired by the brain and trained by "deep learning" methods. However, while deep neural networks have led to many successes and new capabilities in computer vision, speech recognition, language processing, game-playing, and robotics, their potential for broad application remains limited by several factors. A concerning limitation is that even the most successful of today's AI systems suffer from brittleness-they can fail in unexpected ways when faced with situations that differ sufficiently from ones they have been trained on. This lack of robustness also appears in the vulnerability of AI systems to adversarial attacks, in which an adversary can subtly manipulate data in a way to guarantee a specific wrong answer or action from an AI system. AI systems also can absorb biases-based on gender, race, or other factors-from their training data and further magnify these biases in their subsequent decision-making. Taken together, these various limitations have prevented AI systems such as automatic medical diagnosis or autonomous vehicles from being sufficiently trustworthy for wide deployment. The massive proliferation of AI across society will require radically new ideas to yield technology that will not sacrifice our productivity, our quality of life, or our values.