 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Semantically Enriched Embeddings for Knowledge Graph Completion
Aug 02, 2023Embedding based Knowledge Graph (KG) Completion has gained much attention over the past few years. Most of the current algorithms consider a KG as a multidirectional labeled graph and lack the ability to capture the semantics underlying the schematic information. In a separate development, a vast amount of information has been captured within the Large Language Models (LLMs) which has revolutionized the field of Artificial Intelligence. KGs could benefit from these LLMs and vice versa. This vision paper discusses the existing algorithms for KG completion based on the variations for generating KG embeddings. It starts with discussing various KG completion algorithms such as transductive and inductive link prediction and entity type prediction algorithms. It then moves on to the algorithms utilizing type information within the KGs, LLMs, and finally to algorithms capturing the semantics represented in different description logic axioms. We conclude the paper with a critical reflection on the current state of work in the community and give recommendations for future directions.
RAILD: Towards Leveraging Relation Features for Inductive Link Prediction In Knowledge Graphs
Nov 21, 2022Due to the open world assumption, Knowledge Graphs (KGs) are never complete. In order to address this issue, various Link Prediction (LP) methods are proposed so far. Some of these methods are inductive LP models which are capable of learning representations for entities not seen during training. However, to the best of our knowledge, none of the existing inductive LP models focus on learning representations for unseen relations. In this work, a novel Relation Aware Inductive Link preDiction (RAILD) is proposed for KG completion which learns representations for both unseen entities and unseen relations. In addition to leveraging textual literals associated with both entities and relations by employing language models, RAILD also introduces a novel graph-based approach to generate features for relations. Experiments are conducted with different existing and newly created challenging benchmark datasets and the results indicate that RAILD leads to performance improvement over the state-of-the-art models. Moreover, since there are no existing inductive LP models which learn representations for unseen relations, we have created our own baselines and the results obtained with RAILD also outperform these baselines.
Entity Type Prediction Leveraging Graph Walks and Entity Descriptions
Jul 29, 2022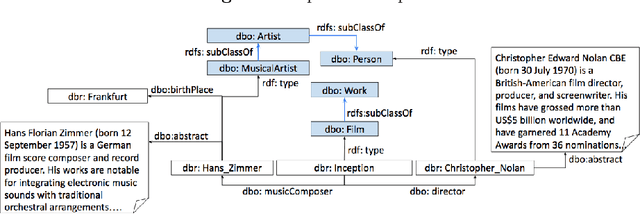
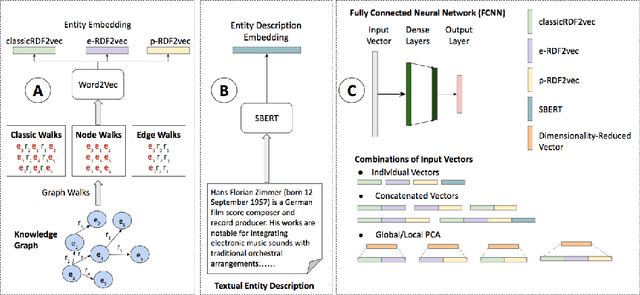
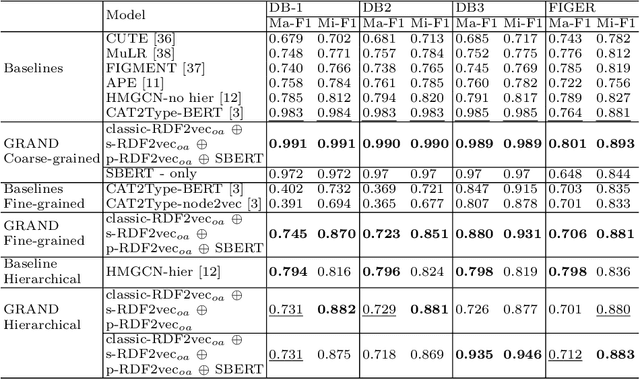
The entity type information in Knowledge Graphs (KGs) such as DBpedia, Freebase, etc. is often incomplete due to automated generation or human curation. Entity typing is the task of assigning or inferring the semantic type of an entity in a KG. This paper presents \textit{GRAND}, a novel approach for entity typing leveraging different graph walk strategies in RDF2vec together with textual entity descriptions. RDF2vec first generates graph walks and then uses a language model to obtain embeddings for each node in the graph. This study shows that the walk generation strategy and the embedding model have a significant effect on the performance of the entity typing task. The proposed approach outperforms the baseline approaches on the benchmark datasets DBpedia and FIGER for entity typing in KGs for both fine-grained and coarse-grained classes. The results show that the combination of order-aware RDF2vec variants together with the contextual embeddings of the textual entity descriptions achieve the best results.
Towards Analyzing the Bias of News Recommender Systems Using Sentiment and Stance Detection
Mar 11, 2022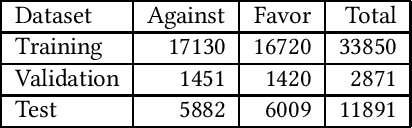

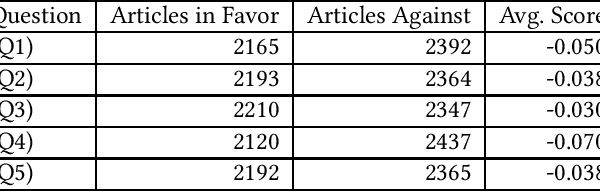
News recommender systems are used by online news providers to alleviate information overload and to provide personalized content to users. However, algorithmic news curation has been hypothesized to create filter bubbles and to intensify users' selective exposure, potentially increasing their vulnerability to polarized opinions and fake news. In this paper, we show how information on news items' stance and sentiment can be utilized to analyze and quantify the extent to which recommender systems suffer from biases. To that end, we have annotated a German news corpus on the topic of migration using stance detection and sentiment analysis. In an experimental evaluation with four different recommender systems, our results show a slight tendency of all four models for recommending articles with negative sentiments and stances against the topic of refugees and migration. Moreover, we observed a positive correlation between the sentiment and stance bias of the text-based recommenders and the preexisting user bias, which indicates that these systems amplify users' opinions and decrease the diversity of recommended news. The knowledge-aware model appears to be the least prone to such biases, at the cost of predictive accuracy.
A Knowledge Graph Embeddings based Approach for Author Name Disambiguation using Literals
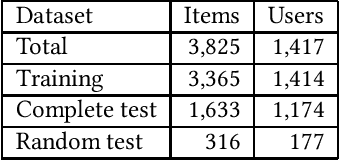
Jan 24, 2022

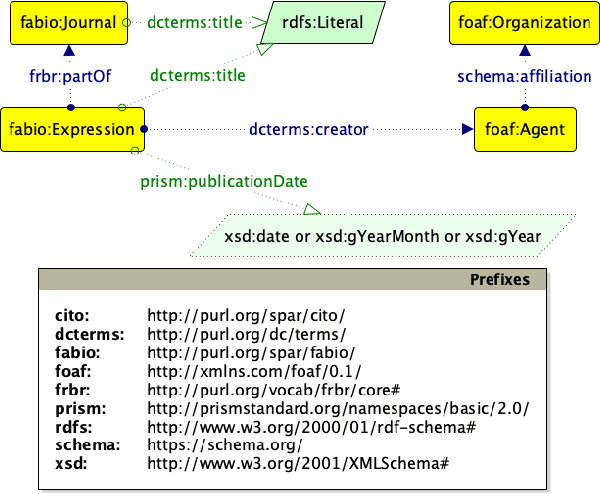

Scholarly data is growing continuously containing information about the articles from plethora of venues including conferences, journals, etc. Many initiatives have been taken to make scholarly data available in the for of Knowledge Graphs (KGs). These efforts to standardize these data and make them accessible have also lead to many challenges such as exploration of scholarly articles, ambiguous authors, etc. This study more specifically targets the problem of Author Name Disambiguation (AND) on Scholarly KGs and presents a novel framework, Literally Author Name Disambiguation (LAND), which utilizes Knowledge Graph Embeddings (KGEs) using multimodal literal information generated from these KGs. This framework is based on three components: 1) Multimodal KGEs, 2) A blocking procedure, and finally, 3) Hierarchical Agglomerative Clustering. Extensive experiments have been conducted on two newly created KGs: (i) KG containing information from Scientometrics Journal from 1978 onwards (OC-782K), and (ii) a KG extracted from a well-known benchmark for AND provided by AMiner (AMiner-534K). The results show that our proposed architecture outperforms our baselines of 8-14\% in terms of F$_1$ score and shows competitive performances on a challenging benchmark such as AMiner. The code and the datasets are publicly available through Github (https://github.com/sntcristian/and-kge) and Zenodo (https://zenodo.org/record/5675787\#.YcCJzL3MJTY) respectively.
On the Impact of Temporal Representations on Metaphor Detection
Nov 05, 2021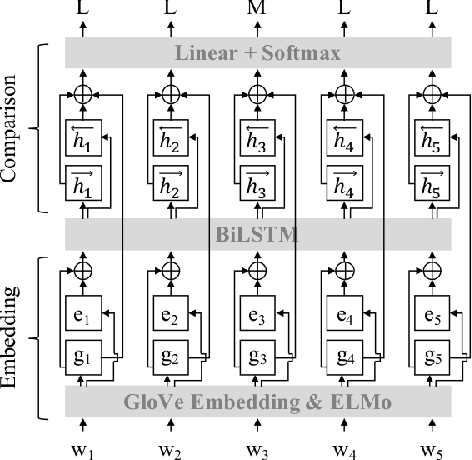
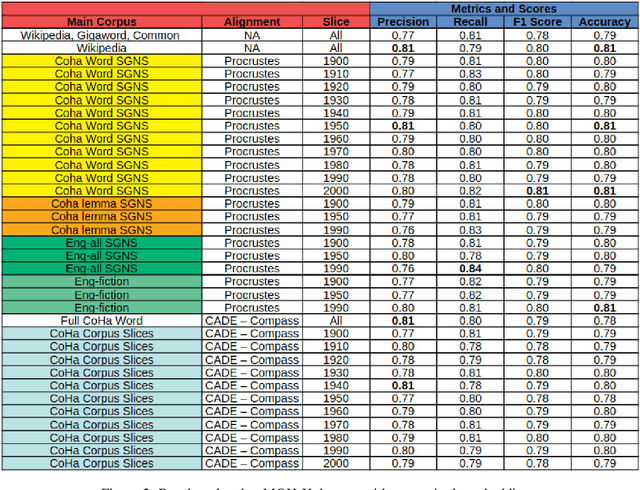
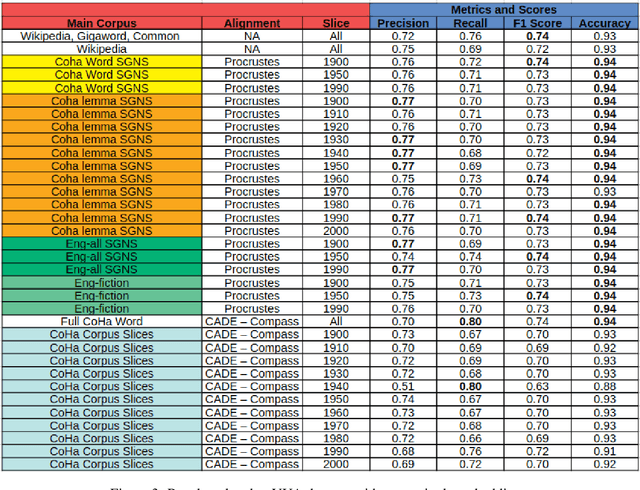
State-of-the-art approaches for metaphor detection compare their literal - or core - meaning and their contextual meaning using sequential metaphor classifiers based on neural networks. The signal that represents the literal meaning is often represented by (non-contextual) word embeddings. However, metaphorical expressions evolve over time due to various reasons, such as cultural and societal impact. Metaphorical expressions are known to co-evolve with language and literal word meanings, and even drive, to some extent, this evolution. This rises the question whether different, possibly time-specific, representations of literal meanings may impact on the metaphor detection task. To the best of our knowledge, this is the first study which examines the metaphor detection task with a detailed exploratory analysis where different temporal and static word embeddings are used to account for different representations of literal meanings. Our experimental analysis is based on three popular benchmarks used for metaphor detection and word embeddings extracted from different corpora and temporally aligned to different state-of-the-art approaches. The results suggest that different word embeddings do impact on the metaphor detection task and some temporal word embeddings slightly outperform static methods on some performance measures. However, results also suggest that temporal word embeddings may provide representations of words' core meaning even too close to their metaphorical meaning, thus confusing the classifier. Overall, the interaction between temporal language evolution and metaphor detection appears tiny in the benchmark datasets used in our experiments. This suggests that future work for the computational analysis of this important linguistic phenomenon should first start by creating a new dataset where this interaction is better represented.
MigrationsKB: A Knowledge Base of Public Attitudes towards Migrations and their Driving Factors
Aug 17, 2021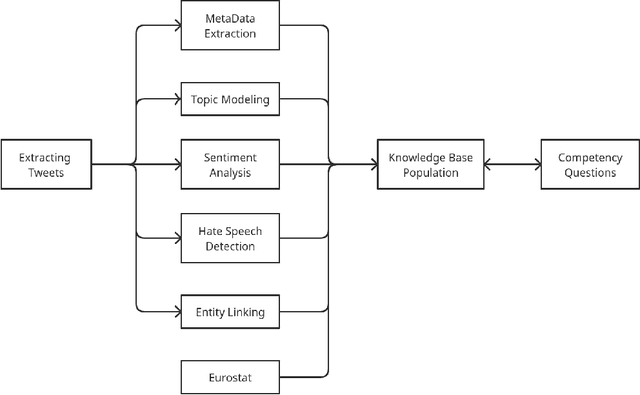
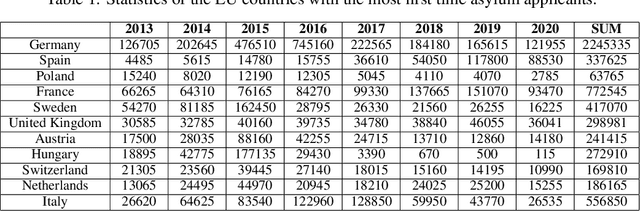

With the increasing trend in the topic of migration in Europe, the public is now more engaged in expressing their opinions through various platforms such as Twitter. Understanding the online discourses is therefore essential to capture the public opinion. The goal of this study is the analysis of social media platform to quantify public attitudes towards migrations and the identification of different factors causing these attitudes. The tweets spanning from 2013 to Jul-2021 in the European countries which are hosts to immigrants are collected, pre-processed, and filtered using advanced topic modeling technique. BERT-based entity linking and sentiment analysis, and attention-based hate speech detection are performed to annotate the curated tweets. Moreover, the external databases are used to identify the potential social and economic factors causing negative attitudes of the people about migration. To further promote research in the interdisciplinary fields of social science and computer science, the outcomes are integrated into a Knowledge Base (KB), i.e., MigrationsKB which significantly extends the existing models to take into account the public attitudes towards migrations and the economic indicators. This KB is made public using FAIR principles, which can be queried through SPARQL endpoint. Data dumps are made available on Zenodo.
Entity Type Prediction in Knowledge Graphs using Embeddings
May 06, 2020
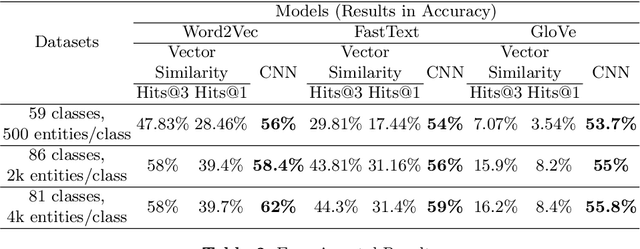
Open Knowledge Graphs (such as DBpedia, Wikidata, YAGO) have been recognized as the backbone of diverse applications in the field of data mining and information retrieval. Hence, the completeness and correctness of the Knowledge Graphs (KGs) are vital. Most of these KGs are mostly created either via an automated information extraction from Wikipedia snapshots or information accumulation provided by the users or using heuristics. However, it has been observed that the type information of these KGs is often noisy, incomplete, and incorrect. To deal with this problem a multi-label classification approach is proposed in this work for entity typing using KG embeddings. We compare our approach with the current state-of-the-art type prediction method and report on experiments with the KGs.
Semantic Entity Enrichment by Leveraging Multilingual Descriptions for Link Prediction
Apr 22, 2020
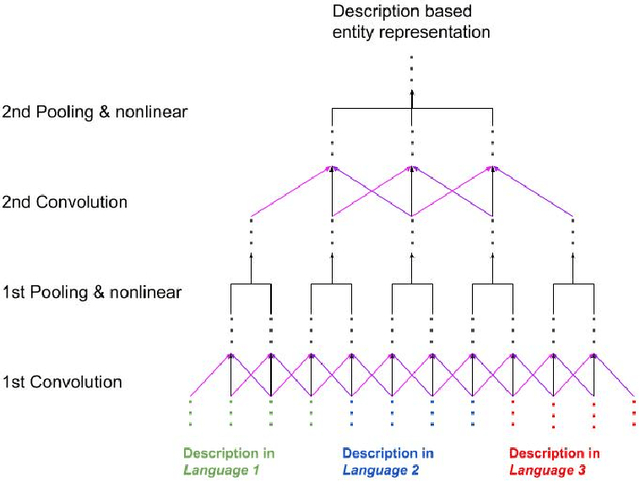
Most Knowledge Graphs (KGs) contain textual descriptions of entities in various natural languages. These descriptions of entities provide valuable information that may not be explicitly represented in the structured part of the KG. Based on this fact, some link prediction methods which make use of the information presented in the textual descriptions of entities have been proposed to learn representations of (monolingual) KGs. However, these methods use entity descriptions in only one language and ignore the fact that descriptions given in different languages may provide complementary information and thereby also additional semantics. In this position paper, the problem of effectively leveraging multilingual entity descriptions for the purpose of link prediction in KGs will be discussed along with potential solutions to the problem.
Is Aligning Embedding Spaces a Challenging Task? An Analysis of the Existing Methods
Feb 21, 2020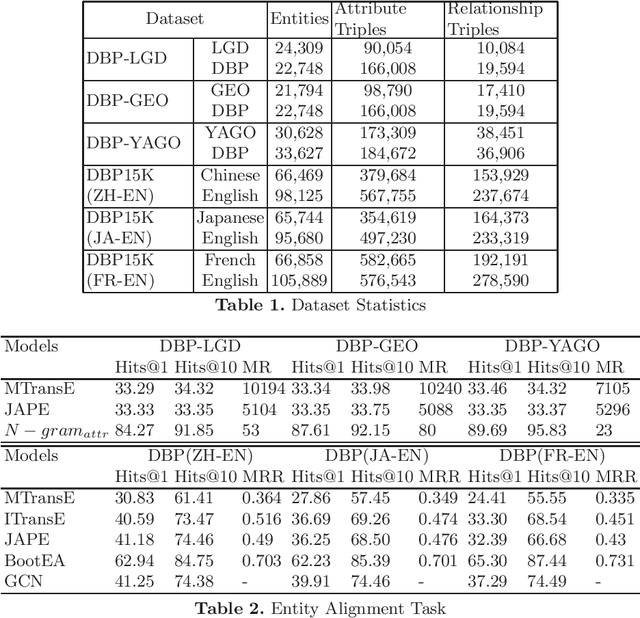
Representation Learning of words and Knowledge Graphs (KG) into low dimensional vector spaces along with its applications to many real-world scenarios have recently gained momentum. In order to make use of multiple KG embeddings for knowledge-driven applications such as question answering, named entity disambiguation, knowledge graph completion, etc., alignment of different KG embedding spaces is necessary. In addition to multilinguality and domain-specific information, different KGs pose the problem of structural differences making the alignment of the KG embeddings more challenging. This paper provides a theoretical analysis and comparison of the state-of-the-art alignment methods between two embedding spaces representing entity-entity and entity-word. This paper also aims at assessing the capability and short-comings of the existing alignment methods on the pretext of different applications.